An Animation-based Augmentation Approach for Action Recognition from Discontinuous Video

0

Sign in to get full access
Overview
- This research paper presents an animation-based approach to augment action recognition from discontinuous video data.
- The key idea is to generate synthetic human animations to supplement the training data, which can improve the performance of action recognition models.
- The approach involves using motion capture data to create realistic human animations that can be inserted into the original video frames, effectively increasing the diversity and volume of the training data.
Plain English Explanation
The researchers developed a way to improve action recognition in videos, even when the videos have gaps or missing frames. They did this by creating artificial human animations to add to the training data for the action recognition models.
The process starts with using motion capture data - this is technology that can record the movements of a person's body in 3D. The researchers then use this motion data to generate realistic computer-animated human characters performing various actions. These synthetic animations are then seamlessly inserted into the original video frames, effectively expanding the training dataset.
The advantage of this approach is that it can help the action recognition models learn more effectively, even when the original video data has missing frames or other discontinuities. By having a richer and more diverse set of examples to train on, including the synthetic animations, the models can become more robust and accurate at recognizing actions in real-world videos.
This technique could be particularly useful for applications where the available video data has gaps or is otherwise incomplete, such as surveillance footage or videos captured by wearable devices. The animation-based augmentation helps fill in those gaps and improves the overall performance of the action recognition system.
Technical Explanation
The paper proposes an animation-based augmentation approach for action recognition from discontinuous video data. The key idea is to generate synthetic human animations and integrate them into the original video frames to augment the training data for action recognition models.
The approach involves two main steps:
-
Synthetic Human Animation Generation: The researchers use motion capture data to create realistic computer-generated animations of humans performing various actions. This is done by extracting 3D skeletal pose information from the motion capture data and then animating a virtual human model accordingly.
-
Animation Integration: The synthetic human animations are then seamlessly inserted into the original video frames, effectively increasing the diversity and volume of the training data for the action recognition models. This is achieved through a careful alignment and blending process to ensure the inserted animations appear natural and coherent with the surrounding scene.
The authors evaluate their approach on several benchmark datasets for action recognition, including ActNetFormer and ActivityNet. The results show that the animation-based augmentation can significantly improve the performance of the action recognition models, particularly in scenarios where the original video data has discontinuities or missing frames.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenge of action recognition in the presence of discontinuous video data. The authors' use of synthetic human animations to augment the training data is an ingenious solution that effectively expands the diversity of examples the models can learn from.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the approach. For example, it would be interesting to understand the extent to which the synthetic animations need to closely match the visual characteristics of the original video data to be effective. Additionally, the paper does not explore the computational cost and complexity of generating and integrating the animations, which could be an important consideration for real-world applications.
Furthermore, the paper could have delved deeper into the broader implications of this research, such as its potential benefits for other areas of computer vision and robotics that rely on accurate action recognition, or the ethical considerations around the use of synthetic data in sensitive applications like surveillance.
Overall, the paper presents a compelling and technically sound approach, but could have provided a more comprehensive discussion of the limitations, broader context, and future research directions.
Conclusion
This research paper introduces an innovative animation-based augmentation approach for improving action recognition in discontinuous video data. By generating realistic synthetic human animations and seamlessly integrating them into the original video frames, the authors are able to effectively expand the diversity and volume of the training data for action recognition models.
The results demonstrate that this approach can significantly boost the performance of state-of-the-art action recognition systems, particularly in scenarios where the input video data contains gaps or missing frames. This technique could be valuable for a wide range of applications, from surveillance and robotics to sports analytics and virtual reality, where accurate action recognition is crucial.
While the paper leaves room for further exploration of the limitations and broader implications of the research, it presents a promising step forward in addressing the challenging problem of action recognition in the real world, where video data is often incomplete or discontinuous.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Animation-based Augmentation Approach for Action Recognition from Discontinuous Video
Xingyu Song, Zhan Li, Shi Chen, Xin-Qiang Cai, Kazuyuki Demachi
Action recognition, an essential component of computer vision, plays a pivotal role in multiple applications. Despite significant improvements brought by Convolutional Neural Networks (CNNs), these models suffer performance declines when trained with discontinuous video frames, which is a frequent scenario in real-world settings. This decline primarily results from the loss of temporal continuity, which is crucial for understanding the semantics of human actions. To overcome this issue, we introduce the 4A (Action Animation-based Augmentation Approach) pipeline, which employs a series of sophisticated techniques: starting with 2D human pose estimation from RGB videos, followed by Quaternion-based Graph Convolution Network for joint orientation and trajectory prediction, and Dynamic Skeletal Interpolation for creating smoother, diversified actions using game engine technology. This innovative approach generates realistic animations in varied game environments, viewed from multiple viewpoints. In this way, our method effectively bridges the domain gap between virtual and real-world data. In experimental evaluations, the 4A pipeline achieves comparable or even superior performance to traditional training approaches using real-world data, while requiring only 10% of the original data volume. Additionally, our approach demonstrates enhanced performance on In-the-wild videos, marking a significant advancement in the field of action recognition.
Read more8/23/2024

0
Action-conditioned video data improves predictability
Meenakshi Sarkar, Debasish Ghose
Long-term video generation and prediction remain challenging tasks in computer vision, particularly in partially observable scenarios where cameras are mounted on moving platforms. The interaction between observed image frames and the motion of the recording agent introduces additional complexities. To address these issues, we introduce the Action-Conditioned Video Generation (ACVG) framework, a novel approach that investigates the relationship between actions and generated image frames through a deep dual Generator-Actor architecture. ACVG generates video sequences conditioned on the actions of robots, enabling exploration and analysis of how vision and action mutually influence one another in dynamic environments. We evaluate the framework's effectiveness on an indoor robot motion dataset which consists of sequences of image frames along with the sequences of actions taken by the robotic agent, conducting a comprehensive empirical study comparing ACVG to other state-of-the-art frameworks along with a detailed ablation study.
Read more4/9/2024

0
Towards Weakly Supervised End-to-end Learning for Long-video Action Recognition
Jiaming Zhou, Hanjun Li, Kun-Yu Lin, Junwei Liang
Developing end-to-end action recognition models on long videos is fundamental and crucial for long-video action understanding. Due to the unaffordable cost of end-to-end training on the whole long videos, existing works generally train models on short clips trimmed from long videos. However, this ``trimming-then-training'' practice requires action interval annotations for clip-level supervision, i.e., knowing which actions are trimmed into the clips. Unfortunately, collecting such annotations is very expensive and prevents model training at scale. To this end, this work aims to build a weakly supervised end-to-end framework for training recognition models on long videos, with only video-level action category labels. Without knowing the precise temporal locations of actions in long videos, our proposed weakly supervised framework, namely AdaptFocus, estimates where and how likely the actions will occur to adaptively focus on informative action clips for end-to-end training. The effectiveness of the proposed AdaptFocus framework is demonstrated on three long-video datasets. Furthermore, for downstream long-video tasks, our AdaptFocus framework provides a weakly supervised feature extraction pipeline for extracting more robust long-video features, such that the state-of-the-art methods on downstream tasks are significantly advanced. We will release the code and models.
Read more5/27/2024
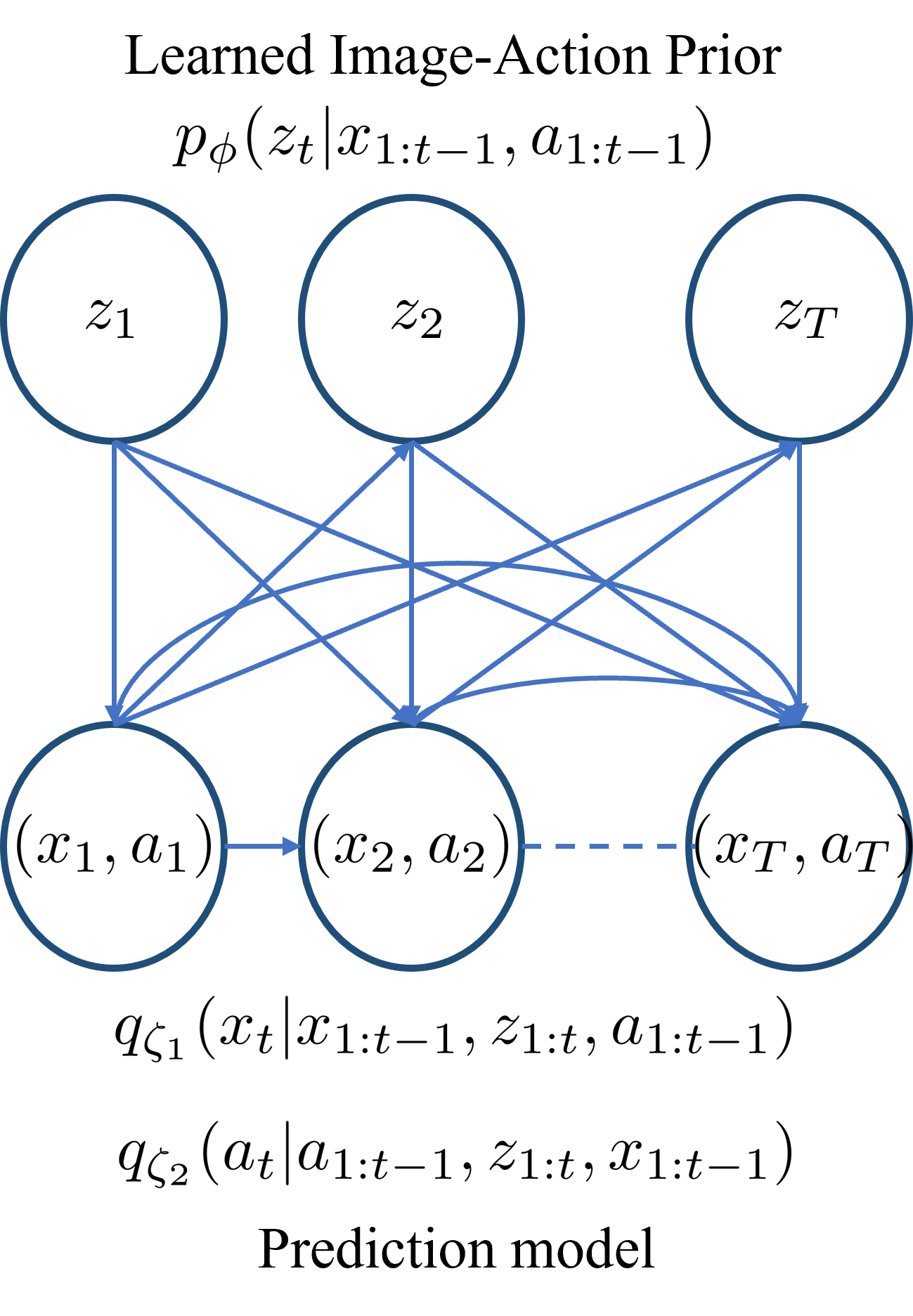
0
Video Generation with Learned Action Prior
Meenakshi Sarkar, Devansh Bhardwaj, Debasish Ghose
Stochastic video generation is particularly challenging when the camera is mounted on a moving platform, as camera motion interacts with observed image pixels, creating complex spatio-temporal dynamics and making the problem partially observable. Existing methods typically address this by focusing on raw pixel-level image reconstruction without explicitly modelling camera motion dynamics. We propose a solution by considering camera motion or action as part of the observed image state, modelling both image and action within a multi-modal learning framework. We introduce three models: Video Generation with Learning Action Prior (VG-LeAP) treats the image-action pair as an augmented state generated from a single latent stochastic process and uses variational inference to learn the image-action latent prior; Causal-LeAP, which establishes a causal relationship between action and the observed image frame at time $t$, learning an action prior conditioned on the observed image states; and RAFI, which integrates the augmented image-action state concept into flow matching with diffusion generative processes, demonstrating that this action-conditioned image generation concept can be extended to other diffusion-based models. We emphasize the importance of multi-modal training in partially observable video generation problems through detailed empirical studies on our new video action dataset, RoAM.
Read more6/21/2024