Action-conditioned video data improves predictability
2404.05439
0
0

Abstract
Long-term video generation and prediction remain challenging tasks in computer vision, particularly in partially observable scenarios where cameras are mounted on moving platforms. The interaction between observed image frames and the motion of the recording agent introduces additional complexities. To address these issues, we introduce the Action-Conditioned Video Generation (ACVG) framework, a novel approach that investigates the relationship between actions and generated image frames through a deep dual Generator-Actor architecture. ACVG generates video sequences conditioned on the actions of robots, enabling exploration and analysis of how vision and action mutually influence one another in dynamic environments. We evaluate the framework's effectiveness on an indoor robot motion dataset which consists of sequences of image frames along with the sequences of actions taken by the robotic agent, conducting a comprehensive empirical study comparing ACVG to other state-of-the-art frameworks along with a detailed ablation study.
Create account to get full access
Overview
- The paper investigates how action-conditioned video data can improve the predictability of future video frames in a video generation task.
- It explores the use of action information, represented as human joint movements, to guide the generation of future video frames.
- The proposed approach aims to leverage the correlation between human actions and the resulting visual scene changes to enhance the performance of video prediction models.
Plain English Explanation
The researchers in this study wanted to find out if including information about the actions people take in a video can help make the future frames of the video more predictable. They believe that the way people move and interact with their environment is closely linked to the changes we see in the video. By using data on the specific joint movements and actions of people in the video, the researchers hoped to create video prediction models that could more accurately forecast what will happen next.
This is useful because being able to accurately predict future video frames has many practical applications, such as link to "intention-conditioned-long-term-human-egocentric-action" in robotics, self-driving cars, and video compression. The researchers wanted to see if incorporating action data could improve the performance of these video prediction models compared to using just the visual information alone.
Technical Explanation
The paper proposes an action-conditioned video generation approach that leverages human joint movements to guide the prediction of future video frames. The key components include:
-
Generator Network: A neural network architecture that takes in the current video frame, the predicted action, and the previous latent state as inputs to generate the next video frame.
-
Action Encoder: An encoder network that processes the human joint movement data and outputs a compact action representation to condition the video generation process.
The researchers trained and evaluated this model on several video datasets, including link to "genhowto-learning-to-generate-actions-state-transformations" and link to "audio-visual-conversational-graph-from-egocentric-exocentric". Their experiments showed that incorporating action-conditioned data can significantly improve the quality and predictability of the generated future video frames compared to baselines that only use visual information.
Critical Analysis
The paper provides a compelling approach to leveraging action information for improved video prediction, but there are a few considerations:
-
The reliance on accurate human pose estimation: The method assumes that the joint movement data is available and can be reliably extracted from the input video. In real-world scenarios, this may not always be the case, especially in complex or occluded scenes.
-
Generalization to diverse actions and environments: The experiments were conducted on relatively constrained datasets. It would be valuable to see how the approach performs on more diverse and unconstrained video data, including link to "language-model-guided-interpretable-video-action-reasoning".
-
Computational efficiency: While the action-conditioned approach showed improved performance, the additional computational overhead of the action encoder and its integration into the video generation process should be considered, especially for real-time applications.
Conclusion
This research demonstrates the potential of leveraging action-conditioned video data to enhance the predictability of future video frames. By incorporating human joint movement information, the proposed model can generate more accurate and realistic future video frames compared to approaches that only use visual data. This has promising implications for applications like link to "bridging-language-vision-action-multimodal-vaes-robotic" that rely on accurate video prediction. Further research is needed to address the identified limitations and explore the broader applicability of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
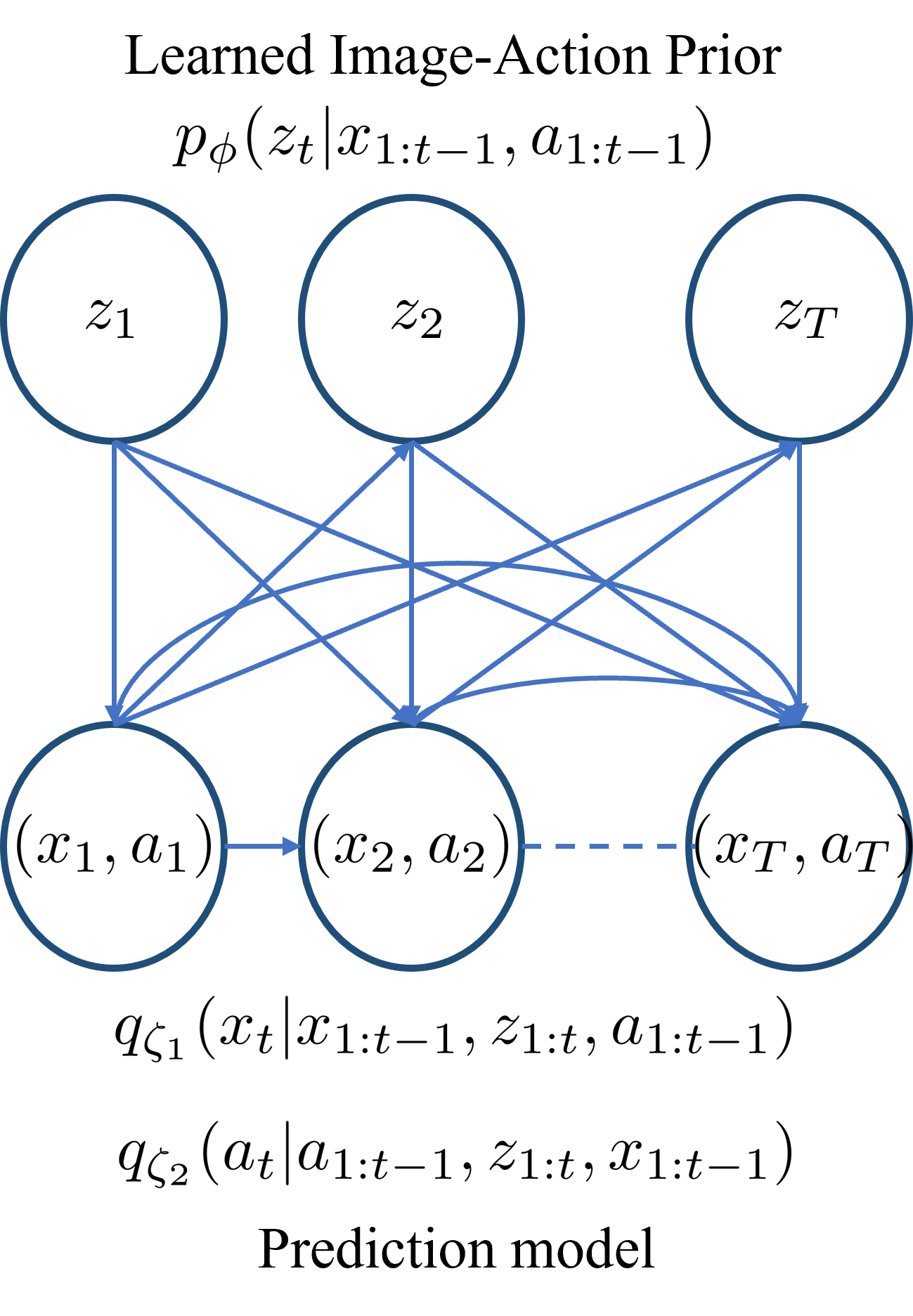
Video Generation with Learned Action Prior
Meenakshi Sarkar, Devansh Bhardwaj, Debasish Ghose
0
0
Stochastic video generation is particularly challenging when the camera is mounted on a moving platform, as camera motion interacts with observed image pixels, creating complex spatio-temporal dynamics and making the problem partially observable. Existing methods typically address this by focusing on raw pixel-level image reconstruction without explicitly modelling camera motion dynamics. We propose a solution by considering camera motion or action as part of the observed image state, modelling both image and action within a multi-modal learning framework. We introduce three models: Video Generation with Learning Action Prior (VG-LeAP) treats the image-action pair as an augmented state generated from a single latent stochastic process and uses variational inference to learn the image-action latent prior; Causal-LeAP, which establishes a causal relationship between action and the observed image frame at time $t$, learning an action prior conditioned on the observed image states; and RAFI, which integrates the augmented image-action state concept into flow matching with diffusion generative processes, demonstrating that this action-conditioned image generation concept can be extended to other diffusion-based models. We emphasize the importance of multi-modal training in partially observable video generation problems through detailed empirical studies on our new video action dataset, RoAM.
6/21/2024

Exploring Explainability in Video Action Recognition
Avinab Saha, Shashank Gupta, Sravan Kumar Ankireddy, Karl Chahine, Joydeep Ghosh
0
0
Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
4/16/2024
🛸
ConditionVideo: Training-Free Condition-Guided Text-to-Video Generation
Bo Peng, Xinyuan Chen, Yaohui Wang, Chaochao Lu, Yu Qiao
0
0
Recent works have successfully extended large-scale text-to-image models to the video domain, producing promising results but at a high computational cost and requiring a large amount of video data. In this work, we introduce ConditionVideo, a training-free approach to text-to-video generation based on the provided condition, video, and input text, by leveraging the power of off-the-shelf text-to-image generation methods (e.g., Stable Diffusion). ConditionVideo generates realistic dynamic videos from random noise or given scene videos. Our method explicitly disentangles the motion representation into condition-guided and scenery motion components. To this end, the ConditionVideo model is designed with a UNet branch and a control branch. To improve temporal coherence, we introduce sparse bi-directional spatial-temporal attention (sBiST-Attn). The 3D control network extends the conventional 2D controlnet model, aiming to strengthen conditional generation accuracy by additionally leveraging the bi-directional frames in the temporal domain. Our method exhibits superior performance in terms of frame consistency, clip score, and conditional accuracy, outperforming other compared methods.
5/24/2024
🛸
CamViG: Camera Aware Image-to-Video Generation with Multimodal Transformers
Andrew Marmon, Grant Schindler, Jos'e Lezama, Dan Kondratyuk, Bryan Seybold, Irfan Essa
0
0
We extend multimodal transformers to include 3D camera motion as a conditioning signal for the task of video generation. Generative video models are becoming increasingly powerful, thus focusing research efforts on methods of controlling the output of such models. We propose to add virtual 3D camera controls to generative video methods by conditioning generated video on an encoding of three-dimensional camera movement over the course of the generated video. Results demonstrate that we are (1) able to successfully control the camera during video generation, starting from a single frame and a camera signal, and (2) we demonstrate the accuracy of the generated 3D camera paths using traditional computer vision methods.
5/24/2024