Video Generation with Learned Action Prior

0
Sign in to get full access
Overview
- This paper presents a novel approach for generating realistic videos conditioned on actions performed by characters in the scene.
- The key innovation is the use of a learned action prior, which captures the inherent structure and dynamics of common actions and helps guide the video generation process.
- The authors demonstrate the effectiveness of their approach on several challenging video generation tasks, including future frame prediction and interpolation.
Plain English Explanation
The researchers in this paper developed a new way to generate realistic videos based on the actions that characters are performing. Instead of just trying to predict the next frame in a video sequence, their approach takes into account the underlying structure and dynamics of the actions themselves.
Imagine you're watching a video of someone playing basketball. The way they dribble the ball, shoot, or pass follows certain patterns and rules. The researchers created a "learned action prior" that captures these natural action dynamics. This prior knowledge then helps guide the video generation process, allowing the model to produce more plausible and coherent videos.
For example, if the model sees a character starting to raise their arms to shoot a basketball, it can use the learned action prior to predict how the rest of the shot will unfold - the ball arcing through the air, the character's follow-through, etc. This helps the generated video feel more grounded in realistic physical behavior.
The researchers tested their approach on a variety of video generation tasks, like predicting future frames and interpolating between existing frames. By incorporating the learned action prior, they were able to produce more accurate and coherent videos compared to previous methods.
Technical Explanation
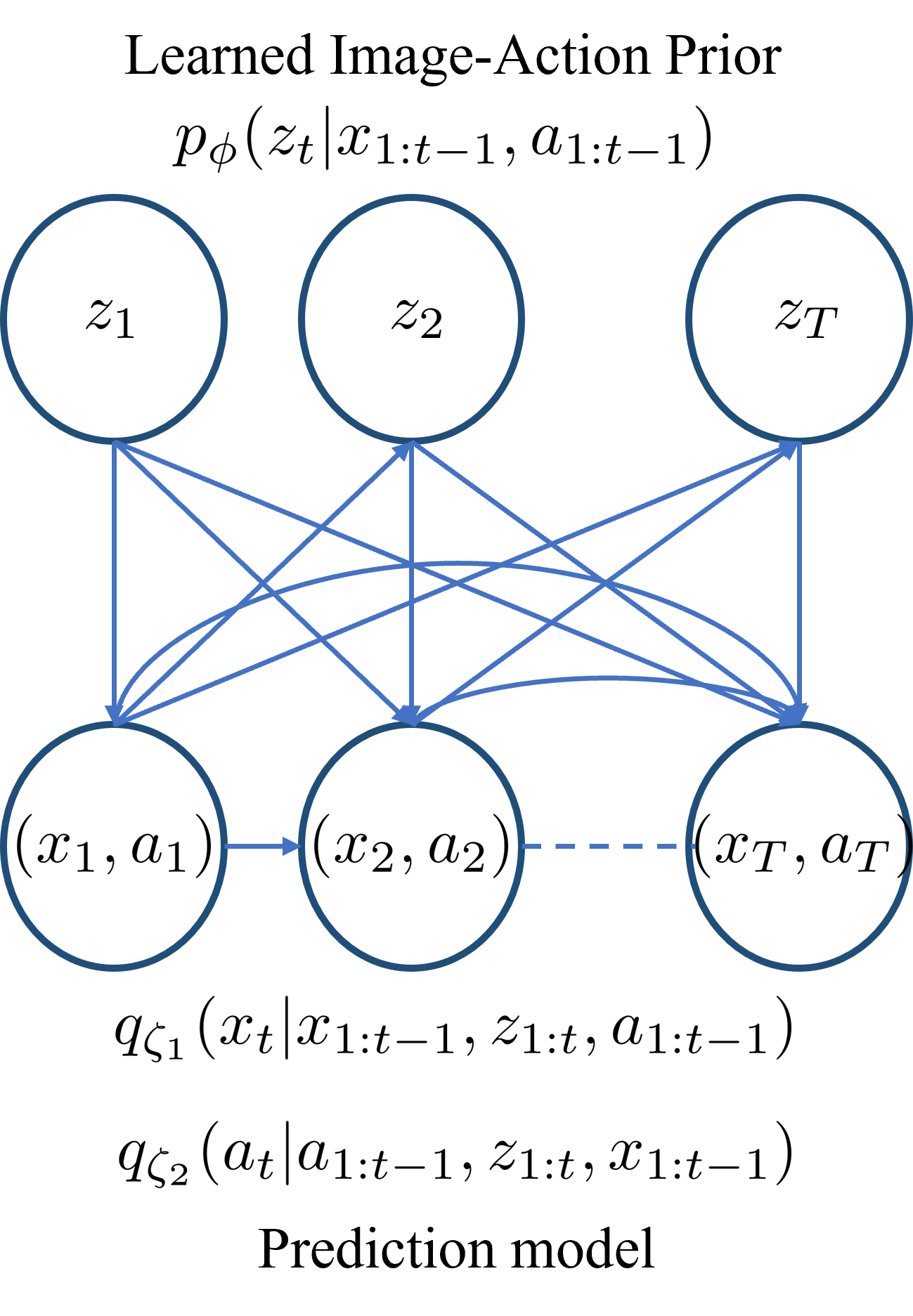
The core of the researchers' approach is the use of a learned action prior, which captures the inherent structure and dynamics of common actions. This prior is learned from a large dataset of action-labeled videos using a self-supervised technique.
Specifically, the action prior is represented as a latent space model that can encode the key features of an action, such as the limb movements, object interactions, and overall motion patterns. During video generation, this learned action prior is combined with a generative model that produces the actual video frames.
The researchers experiment with two different video generation architectures. The first is a future frame prediction model, which takes the current frame and action label as input and generates the next frame in the sequence. The second is an interpolation model, which generates new in-between frames given a pair of existing frames and their associated actions.
Across these tasks, the authors demonstrate that incorporating the learned action prior leads to significant improvements in video quality and coherence, as measured by both quantitative metrics and human evaluation. They also show that the action prior model can be applied to a camera-aware video generation task, producing more realistic camera motions.
Critical Analysis
One potential limitation of this approach is the reliance on having action-labeled video data to learn the action prior. In many real-world scenarios, such detailed annotations may not be readily available. The authors do mention that their method could potentially be extended to work with weaker forms of supervision, but this would likely require further research and experimentation.
Additionally, while the learned action prior helps improve the overall coherence of the generated videos, there may still be room for further refinement. For example, the model may struggle to capture more complex, hierarchical relationships between different actions or handle large-scale, long-term dependencies in the video sequences.
It would also be valuable to investigate the generalization capabilities of the action prior, particularly when applied to novel actions or settings that were not well-represented in the training data. Robustness to such variations is an important consideration for real-world deployment.
Conclusion
This paper presents a novel approach for generating realistic videos by leveraging a learned action prior. The key insight is that capturing the inherent structure and dynamics of common actions can significantly improve the quality and coherence of the generated video sequences.
The researchers demonstrate the effectiveness of their method on several challenging video generation tasks, including future frame prediction and interpolation. By incorporating the action prior, they are able to produce more accurate and realistic videos compared to previous techniques.
While the current approach shows promising results, there are still opportunities for further refinement and exploration, particularly around handling more complex action relationships and improving generalization to novel scenarios. Overall, this work represents an important step forward in the field of video generation and could have valuable applications in areas like animation, virtual reality, and autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Video Generation with Learned Action Prior
Meenakshi Sarkar, Devansh Bhardwaj, Debasish Ghose
Stochastic video generation is particularly challenging when the camera is mounted on a moving platform, as camera motion interacts with observed image pixels, creating complex spatio-temporal dynamics and making the problem partially observable. Existing methods typically address this by focusing on raw pixel-level image reconstruction without explicitly modelling camera motion dynamics. We propose a solution by considering camera motion or action as part of the observed image state, modelling both image and action within a multi-modal learning framework. We introduce three models: Video Generation with Learning Action Prior (VG-LeAP) treats the image-action pair as an augmented state generated from a single latent stochastic process and uses variational inference to learn the image-action latent prior; Causal-LeAP, which establishes a causal relationship between action and the observed image frame at time $t$, learning an action prior conditioned on the observed image states; and RAFI, which integrates the augmented image-action state concept into flow matching with diffusion generative processes, demonstrating that this action-conditioned image generation concept can be extended to other diffusion-based models. We emphasize the importance of multi-modal training in partially observable video generation problems through detailed empirical studies on our new video action dataset, RoAM.
Read more6/21/2024

0
Action-conditioned video data improves predictability
Meenakshi Sarkar, Debasish Ghose
Long-term video generation and prediction remain challenging tasks in computer vision, particularly in partially observable scenarios where cameras are mounted on moving platforms. The interaction between observed image frames and the motion of the recording agent introduces additional complexities. To address these issues, we introduce the Action-Conditioned Video Generation (ACVG) framework, a novel approach that investigates the relationship between actions and generated image frames through a deep dual Generator-Actor architecture. ACVG generates video sequences conditioned on the actions of robots, enabling exploration and analysis of how vision and action mutually influence one another in dynamic environments. We evaluate the framework's effectiveness on an indoor robot motion dataset which consists of sequences of image frames along with the sequences of actions taken by the robotic agent, conducting a comprehensive empirical study comparing ACVG to other state-of-the-art frameworks along with a detailed ablation study.
Read more4/9/2024
🖼️
0
Generative Image Dynamics
Zhengqi Li, Richard Tucker, Noah Snavely, Aleksander Holynski
We present an approach to modeling an image-space prior on scene motion. Our prior is learned from a collection of motion trajectories extracted from real video sequences depicting natural, oscillatory dynamics such as trees, flowers, candles, and clothes swaying in the wind. We model this dense, long-term motion prior in the Fourier domain:given a single image, our trained model uses a frequency-coordinated diffusion sampling process to predict a spectral volume, which can be converted into a motion texture that spans an entire video. Along with an image-based rendering module, these trajectories can be used for a number of downstream applications, such as turning still images into seamlessly looping videos, or allowing users to realistically interact with objects in real pictures by interpreting the spectral volumes as image-space modal bases, which approximate object dynamics.
Read more5/16/2024

0
Training-free Camera Control for Video Generation
Chen Hou, Guoqiang Wei, Yan Zeng, Zhibo Chen
We propose a training-free and robust solution to offer camera movement control for off-the-shelf video diffusion models. Unlike previous work, our method does not require any supervised finetuning on camera-annotated datasets or self-supervised training via data augmentation. Instead, it can be plugged and played with most pretrained video diffusion models and generate camera controllable videos with a single image or text prompt as input. The inspiration of our work comes from the layout prior that intermediate latents hold towards generated results, thus rearranging noisy pixels in them will make output content reallocated as well. As camera move could also be seen as a kind of pixel rearrangement caused by perspective change, videos could be reorganized following specific camera motion if their noisy latents change accordingly. Established on this, we propose our method CamTrol, which enables robust camera control for video diffusion models. It is achieved by a two-stage process. First, we model image layout rearrangement through explicit camera movement in 3D point cloud space. Second, we generate videos with camera motion using layout prior of noisy latents formed by a series of rearranged images. Extensive experiments have demonstrated the robustness our method holds in controlling camera motion of generated videos. Furthermore, we show that our method can produce impressive results in generating 3D rotation videos with dynamic content. Project page at https://lifedecoder.github.io/CamTrol/.
Read more9/9/2024