Faces that Speak: Jointly Synthesising Talking Face and Speech from Text

0
Sign in to get full access
Overview
- This paper presents a novel method for jointly synthesizing a talking face and its corresponding speech from text input.
- The proposed approach, called "Faces that Speak," aims to generate realistic audiovisual content by leveraging the connection between facial movements and speech.
- The authors explore the potential of this technology for various applications, such as virtual assistants, video conferencing, and animated storytelling.
Plain English Explanation
The paper describes a new way to create video of a person's face talking, along with the audio of what they are saying, all starting from just some text. This is a challenging task because there is a complex connection between the movements of a person's face and the sounds they make when speaking.
The researchers developed a system that can take a piece of text, like a script or dialogue, and then automatically generate a video of a digital human face speaking those words out loud. This could be useful for things like creating virtual assistants that can talk to you, improving video calls by animating the other person's face, or making animated stories where the characters speak.
The key innovation is that the system learns to jointly model both the facial movements and the speech, so that they are synchronized and look natural together. This is different from previous approaches that generated the face and speech separately.
Technical Explanation
The "Faces that Speak" system uses a deep learning architecture to perform the joint synthesis of talking face and speech from text input. The core of the model consists of several neural network components:
- A text encoder that converts the input text into a compact representation.
- A facial feature generator that predicts the sequence of facial landmarks and expressions based on the text encoding.
- An audio waveform generator that produces the corresponding speech audio from the text encoding.
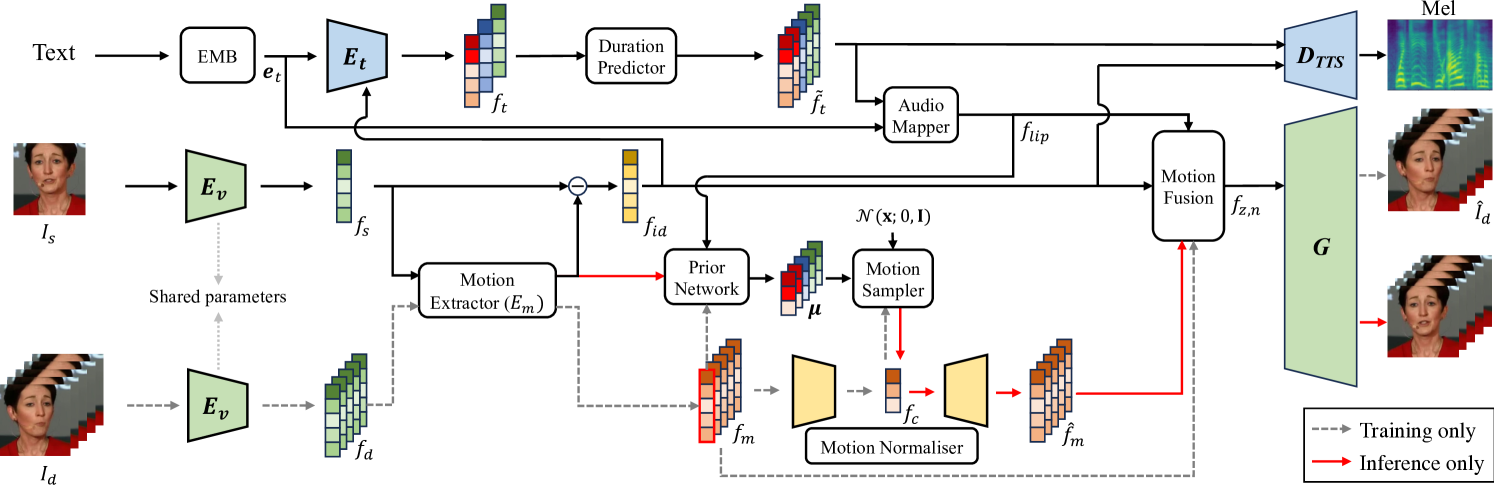
The authors train these components in an end-to-end fashion, allowing the model to learn the inherent relationship between facial movements and speech. This enables the system to generate realistic audiovisual outputs where the lip movements, head poses, and other facial dynamics are synchronized with the generated speech.
The model is trained on a large dataset of audiovisual recordings, and the authors explore different strategies for improving the quality and controllability of the generated content, such as incorporating speaker-specific information and leveraging additional conditioning signals.
Critical Analysis
The "Faces that Speak" approach represents an important step forward in the field of audiovisual content synthesis. By jointly modeling the facial and speech components, the system is able to produce more natural and coherent talking face animations compared to previous methods that generated these elements separately.
However, the paper also acknowledges some limitations of the current work. For example, the generated face animations may still exhibit some artifacts or lack fine-grained control over individual facial features. Additionally, the authors note that the model's performance is dependent on the quality and diversity of the training data, which may be a constraint for certain applications or domains.
Further research is needed to address these challenges and explore ways to enhance the realism, controllability, and generalization capabilities of the system. Potential directions could include incorporating more advanced facial modeling techniques, exploring hierarchical or disentangled representations, and investigating ways to leverage additional modalities or external signals to guide the synthesis process.
Conclusion
The "Faces that Speak" paper presents a promising approach for the joint synthesis of talking face and speech from text input. By learning the inherent connection between facial movements and speech, the system is able to generate realistic audiovisual content that could have numerous applications in virtual communication, entertainment, and beyond.
While the current system shows promising results, there is still room for improvement in terms of realism, controllability, and generalization. Continued research in this area has the potential to unlock new frontiers in human-computer interaction, digital storytelling, and the creation of lifelike virtual characters.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, Joon Son Chung
The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
Read more5/17/2024
0
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
Jun Ling, Yiwen Wang, Han Xue, Rong Xie, Li Song
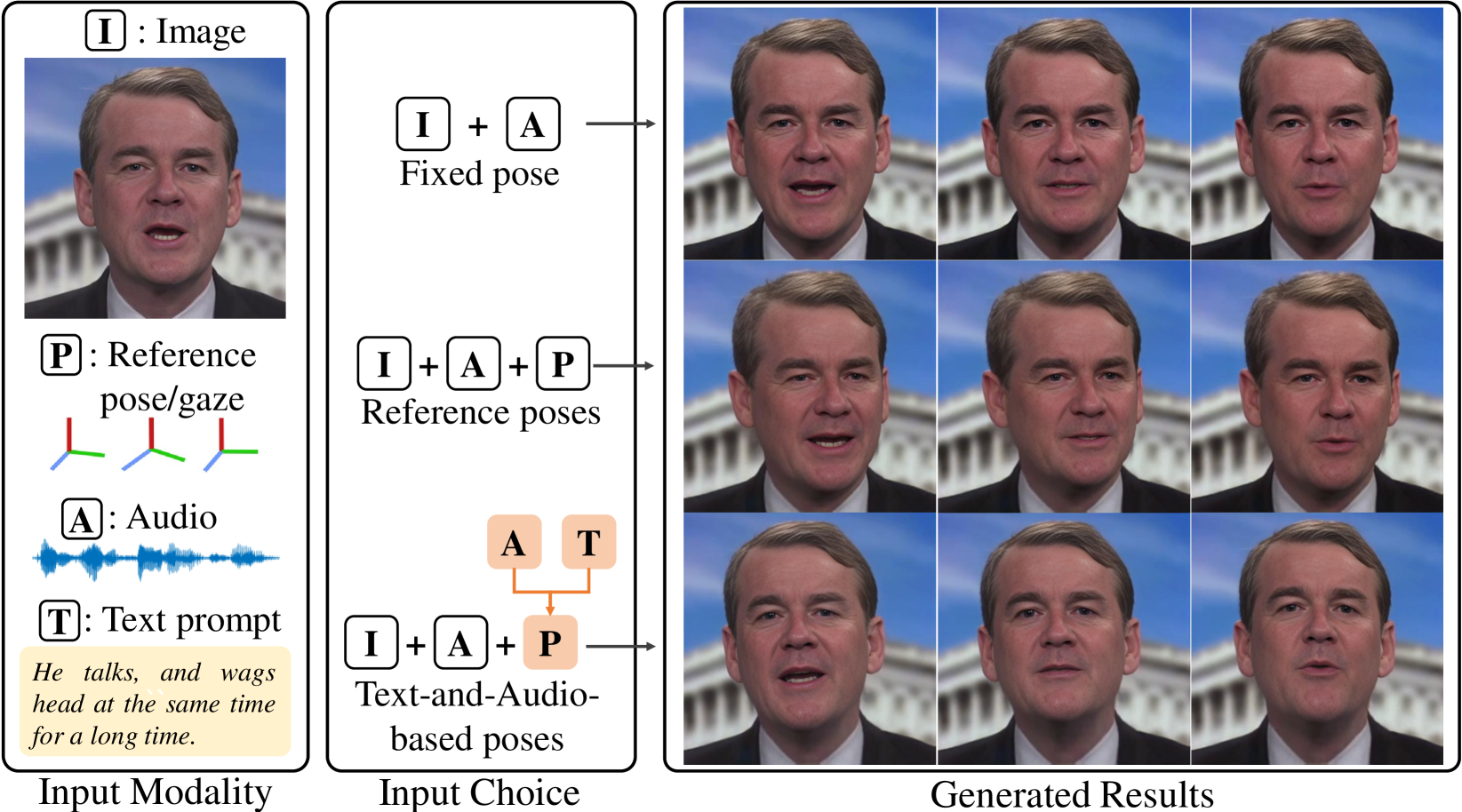
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: https://junleen.github.io/projects/posetalk.
Read more9/5/2024
0
FastTalker: Jointly Generating Speech and Conversational Gestures from Text
Zixin Guo, Jian Zhang
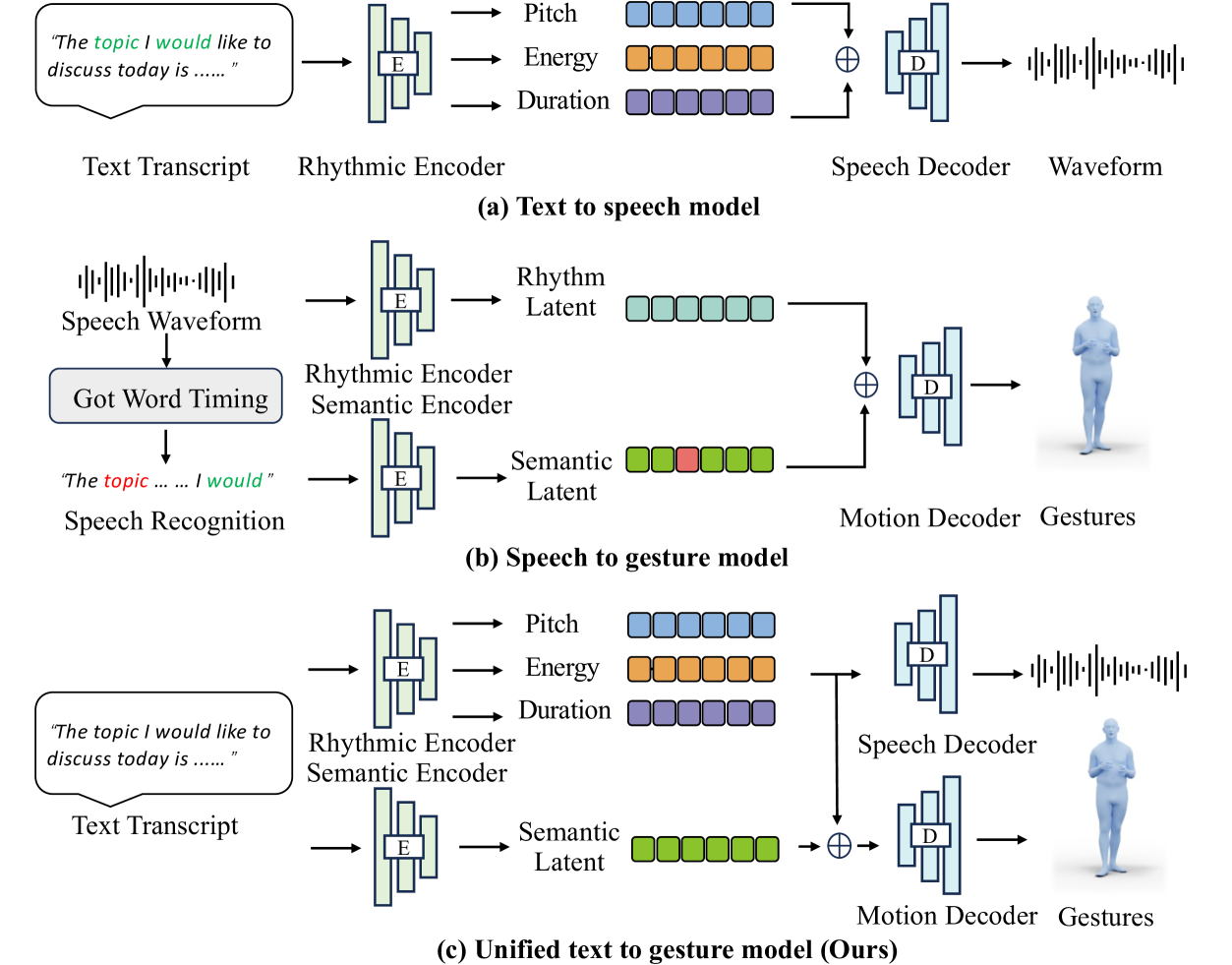
Generating 3D human gestures and speech from a text script is critical for creating realistic talking avatars. One solution is to leverage separate pipelines for text-to-speech (TTS) and speech-to-gesture (STG), but this approach suffers from poor alignment of speech and gestures and slow inference times. In this paper, we introduce FastTalker, an efficient and effective framework that simultaneously generates high-quality speech audio and 3D human gestures at high inference speeds. Our key insight is reusing the intermediate features from speech synthesis for gesture generation, as these features contain more precise rhythmic information than features re-extracted from generated speech. Specifically, 1) we propose an end-to-end framework that concurrently generates speech waveforms and full-body gestures, using intermediate speech features such as pitch, onset, energy, and duration directly for gesture decoding; 2) we redesign the causal network architecture to eliminate dependencies on future inputs for real applications; 3) we employ Reinforcement Learning-based Neural Architecture Search (NAS) to enhance both performance and inference speed by optimizing our network architecture. Experimental results on the BEAT2 dataset demonstrate that FastTalker achieves state-of-the-art performance in both speech synthesis and gesture generation, processing speech and gestures in 0.17 seconds per second on an NVIDIA 3090.
Read more9/26/2024

0
JEAN: Joint Expression and Audio-guided NeRF-based Talking Face Generation
Sai Tanmay Reddy Chakkera, Aggelina Chatziagapi, Dimitris Samaras
We introduce a novel method for joint expression and audio-guided talking face generation. Recent approaches either struggle to preserve the speaker identity or fail to produce faithful facial expressions. To address these challenges, we propose a NeRF-based network. Since we train our network on monocular videos without any ground truth, it is essential to learn disentangled representations for audio and expression. We first learn audio features in a self-supervised manner, given utterances from multiple subjects. By incorporating a contrastive learning technique, we ensure that the learned audio features are aligned to the lip motion and disentangled from the muscle motion of the rest of the face. We then devise a transformer-based architecture that learns expression features, capturing long-range facial expressions and disentangling them from the speech-specific mouth movements. Through quantitative and qualitative evaluation, we demonstrate that our method can synthesize high-fidelity talking face videos, achieving state-of-the-art facial expression transfer along with lip synchronization to unseen audio.
Read more9/19/2024