Anomaly Multi-classification in Industrial Scenarios: Transferring Few-shot Learning to a New Task

0

Sign in to get full access
Overview
• This paper explores the challenge of anomaly multi-classification in industrial scenarios, where the goal is to identify and categorize different types of anomalies in sensor data or machine operations.
• The key focus is on leveraging few-shot learning techniques to enable the transfer of knowledge from one anomaly classification task to a new, related task with limited training data.
• The proposed approach, called Anomaly-DiNo, utilizes a patch-based anomaly detection model combined with few-shot learning strategies to achieve high accuracy on new anomaly classification tasks.
Plain English Explanation
The paper addresses the problem of identifying and classifying different types of unusual or problematic events in industrial settings, such as factory equipment malfunctions or sensor irregularities. The researchers explore a technique called "few-shot learning," which allows a model to quickly adapt to a new classification task by leveraging knowledge gained from previous, similar tasks.
Instead of starting from scratch each time a new anomaly classification challenge arises, the proposed Anomaly-DiNo approach builds on a pre-trained model that can identify general anomalies. This base model is then fine-tuned using only a small amount of labeled data for the specific new task, enabling rapid adaptation to classify different types of anomalies. The goal is to make the process of deploying anomaly detection more efficient and effective in real-world industrial applications where data may be limited.
Technical Explanation
The paper presents a framework called Anomaly-DiNo that leverages few-shot learning to enable the transfer of anomaly classification capabilities from one industrial scenario to another. The approach builds upon a patch-based anomaly detection model, which learns to recognize general anomalous patterns by analyzing small regions of sensor data or machine operation images.
To adapt this base model to a new anomaly classification task, the researchers employ few-shot learning techniques. Specifically, they fine-tune the model's parameters using only a small number of labeled examples for each new anomaly class, allowing the model to quickly learn the distinctive characteristics of the target anomalies.
The proposed framework is evaluated on several industrial datasets, demonstrating its ability to achieve high classification accuracy on new tasks with limited training data. This is in contrast to traditional approaches that often struggle when faced with significant data scarcity in emerging industrial scenarios.
Critical Analysis
The paper provides a compelling approach to addressing the challenge of anomaly multi-classification in industrial settings, where the availability of labeled data for new tasks can be limited. By leveraging few-shot learning, the Anomaly-DiNo framework enables the efficient transfer of knowledge from one anomaly classification task to another, potentially reducing the cost and effort required to deploy anomaly detection systems in new industrial contexts.
However, the paper does not address potential limitations of the patch-based anomaly detection model, such as its ability to capture more complex, contextual anomalies that may extend beyond local regions of sensor data or machine operation images. Additionally, the evaluation is primarily focused on controlled, laboratory-like settings, and further research may be needed to assess the framework's performance in real-world, dynamic industrial environments.
Conclusion
This paper presents a novel approach to anomaly multi-classification in industrial scenarios, leveraging few-shot learning techniques to enable the efficient transfer of knowledge from one task to another. By building upon a patch-based anomaly detection model and fine-tuning it using limited labeled data, the Anomaly-DiNo framework aims to make the deployment of anomaly detection systems more scalable and adaptable to emerging industrial challenges. While the approach shows promise, further research may be needed to address potential limitations and ensure its effectiveness in complex, real-world industrial settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Anomaly Multi-classification in Industrial Scenarios: Transferring Few-shot Learning to a New Task
Jie Liu, Yao Wu, Xiaotong Luo, Zongze Wu
In industrial scenarios, it is crucial not only to identify anomalous items but also to classify the type of anomaly. However, research on anomaly multi-classification remains largely unexplored. This paper proposes a novel and valuable research task called anomaly multi-classification. Given the challenges in applying few-shot learning to this task, due to limited training data and unique characteristics of anomaly images, we introduce a baseline model that combines RelationNet and PatchCore. We propose a data generation method that creates pseudo classes and a corresponding proxy task, aiming to bridge the gap in transferring few-shot learning to industrial scenarios. Furthermore, we utilize contrastive learning to improve the vanilla baseline, achieving much better performance than directly fine-tune a ResNet. Experiments conducted on MvTec AD and MvTec3D AD demonstrate that our approach shows superior performance in this novel task.
Read more6/18/2024
0
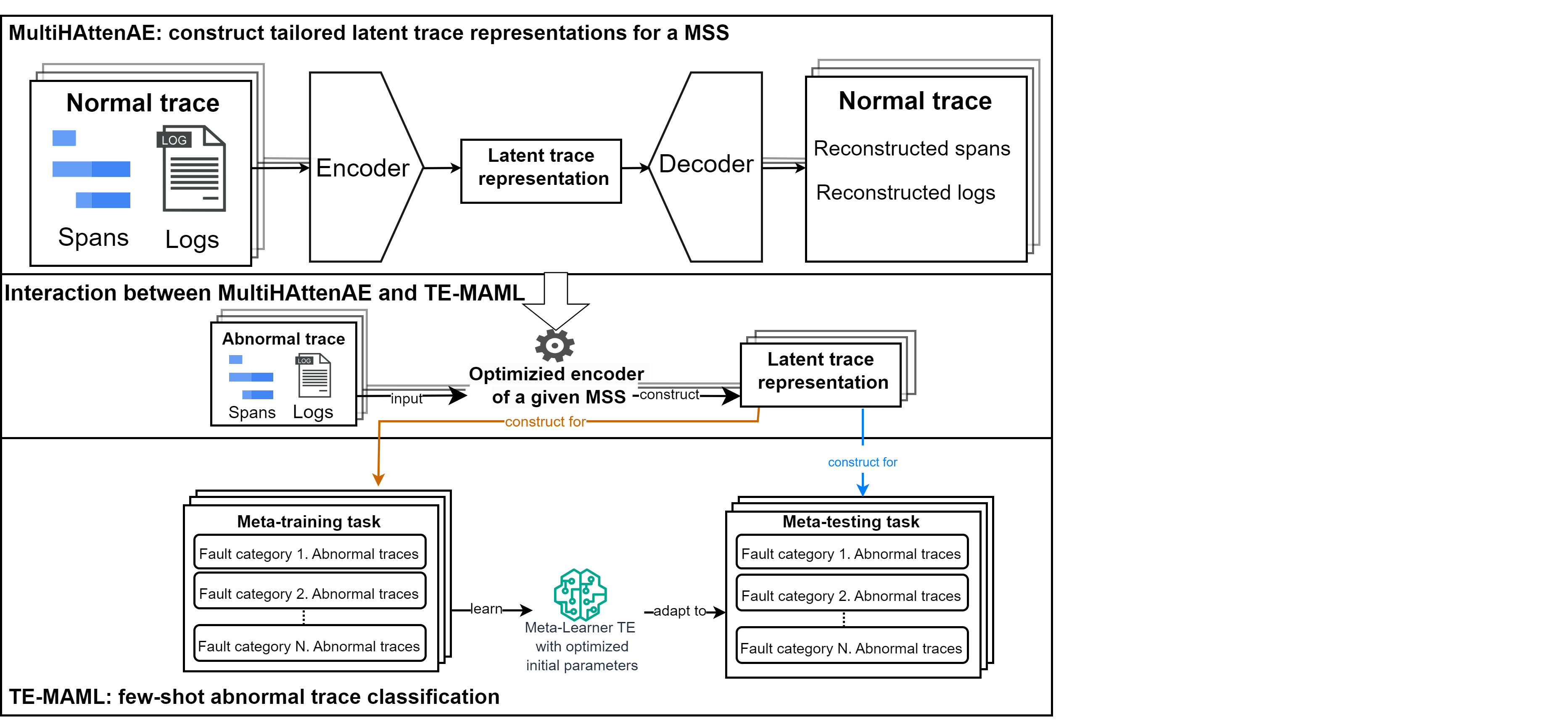
Few-Shot Cross-System Anomaly Trace Classification for Microservice-based systems
Yuqing Wang, Mika V. Mantyla, Serge Demeyer, Mutlu Beyazit, Joanna Kisaakye, Jesse Nyyssola
Microservice-based systems (MSS) may experience failures in various fault categories due to their complex and dynamic nature. To effectively handle failures, AIOps tools utilize trace-based anomaly detection and root cause analysis. In this paper, we propose a novel framework for few-shot abnormal trace classification for MSS. Our framework comprises two main components: (1) Multi-Head Attention Autoencoder for constructing system-specific trace representations, which enables (2) Transformer Encoder-based Model-Agnostic Meta-Learning to perform effective and efficient few-shot learning for abnormal trace classification. The proposed framework is evaluated on two representative MSS, Trainticket and OnlineBoutique, with open datasets. The results show that our framework can adapt the learned knowledge to classify new, unseen abnormal traces of novel fault categories both within the same system it was initially trained on and even in the different MSS. Within the same MSS, our framework achieves an average accuracy of 93.26% and 85.2% across 50 meta-testing tasks for Trainticket and OnlineBoutique, respectively, when provided with 10 instances for each task. In a cross-system context, our framework gets an average accuracy of 92.19% and 84.77% for the same meta-testing tasks of the respective system, also with 10 instances provided for each task. Our work demonstrates the applicability of achieving few-shot abnormal trace classification for MSS and shows how it can enable cross-system adaptability. This opens an avenue for building more generalized AIOps tools that require less system-specific data labeling for anomaly detection and root cause analysis.
Read more4/15/2024

0
Domain-independent detection of known anomalies
Jonas Buhler, Jonas Fehrenbach, Lucas Steinmann, Christian Nauck, Marios Koulakis
One persistent obstacle in industrial quality inspection is the detection of anomalies. In real-world use cases, two problems must be addressed: anomalous data is sparse and the same types of anomalies need to be detected on previously unseen objects. Current anomaly detection approaches can be trained with sparse nominal data, whereas domain generalization approaches enable detecting objects in previously unseen domains. Utilizing those two observations, we introduce the hybrid task of domain generalization on sparse classes. To introduce an accompanying dataset for this task, we present a modification of the well-established MVTec AD dataset by generating three new datasets. In addition to applying existing methods for benchmark, we design two embedding-based approaches, Spatial Embedding MLP (SEMLP) and Labeled PatchCore. Overall, SEMLP achieves the best performance with an average image-level AUROC of 87.2 % vs. 80.4 % by MIRO. The new and openly available datasets allow for further research to improve industrial anomaly detection.
Read more7/4/2024
0
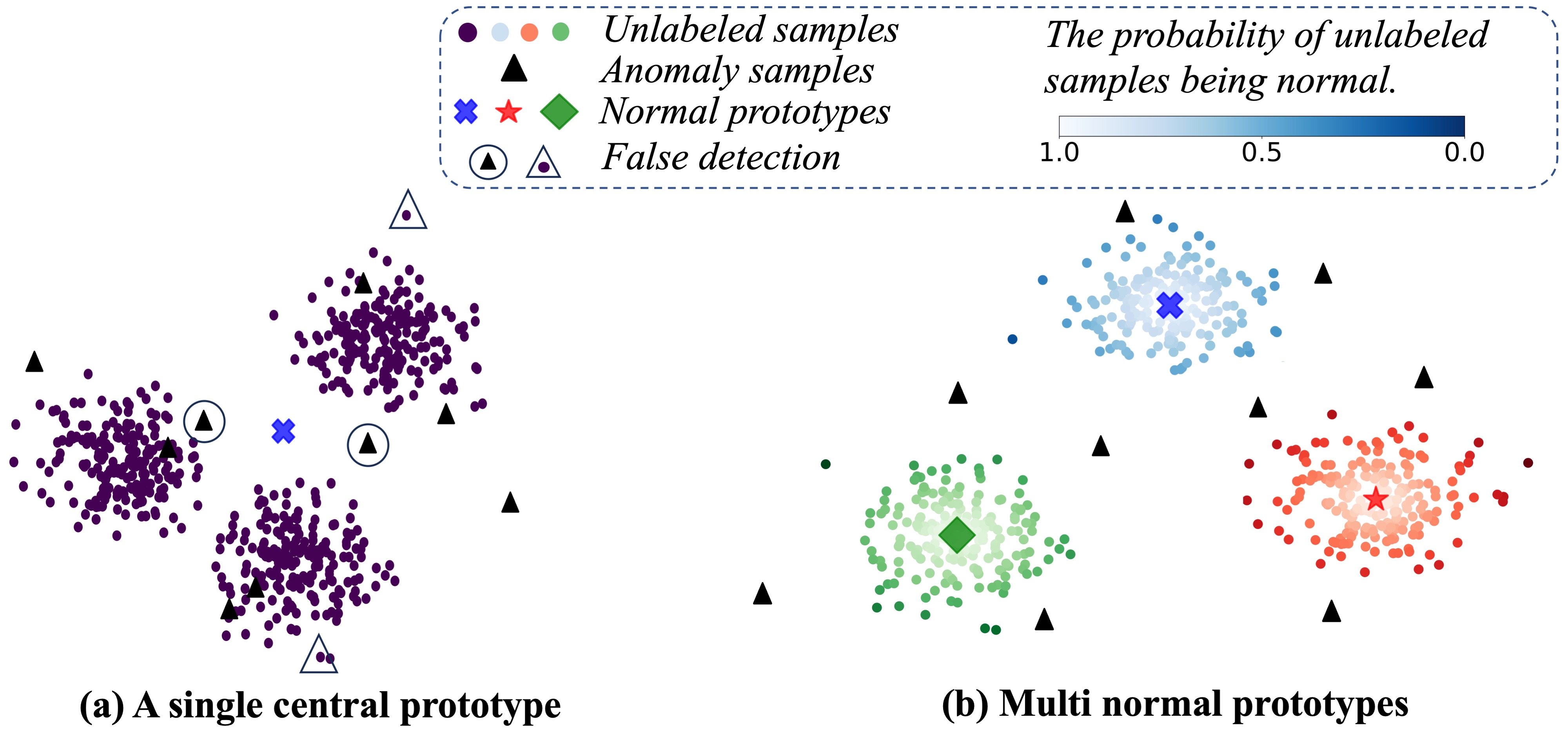
Reconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection
Zhijin Dong, Hongzhi Liu, Boyuan Ren, Weimin Xiong, Zhonghai Wu
Anomaly detection is a crucial task in various domains. Most of the existing methods assume the normal sample data clusters around a single central prototype while the real data may consist of multiple categories or subgroups. In addition, existing methods always assume all unlabeled data are normal while they inevitably contain some anomalous samples. To address these issues, we propose a reconstruction-based multi-normal prototypes learning framework that leverages limited labeled anomalies in conjunction with abundant unlabeled data for anomaly detection. Specifically, we assume the normal sample data may satisfy multi-modal distribution, and utilize deep embedding clustering and contrastive learning to learn multiple normal prototypes to represent it. Additionally, we estimate the likelihood of each unlabeled sample being normal based on the multi-normal prototypes, guiding the training process to mitigate the impact of contaminated anomalies in the unlabeled data. Extensive experiments on various datasets demonstrate the superior performance of our method compared to state-of-the-art techniques.
Read more8/28/2024