Anticipating Next Active Objects for Egocentric Videos

0
📉
Sign in to get full access
Overview
- This paper tackles the problem of anticipating the location of the next active object in an egocentric video clip, before any action takes place.
- Estimating the position of such objects is challenging, as the observed clip and the action segment are separated by a "time to contact" (TTC) period.
- Previous methods have focused on anticipating human actions based on hand movements and interactions, but not the next interactable object and its future location.
- The authors define this task as "Anticipating the Next ACTive Object" (ANACTO) and propose a transformer-based self-attention framework to address it.
Plain English Explanation
The paper aims to solve a difficult problem: predicting where the next object that a person will interact with will be located, before they actually start interacting with it. This is challenging because there is a gap in time between when the video is recorded and when the person starts their action.
Previous research has looked at predicting what actions a person will take based on their hand movements and interactions with the environment. However, no one has tried to figure out which specific object the person will interact with next, and where that object will be located in the video.
The researchers call this task "Anticipating the Next ACTive Object" (ANACTO). To tackle this problem, they developed a transformer-based neural network that can identify and locate the next object that the person will interact with, using the information in the video clip.
Technical Explanation
The authors propose a transformer-based self-attention framework to tackle the ANACTO task. This approach allows the model to identify and locate the next object that the person will interact with, even during the "time to contact" (TTC) period between the observed video clip and the actual interaction.
The method is evaluated on three datasets: EpicKitchens-100, EGTEA+, and Ego4D. The authors also provide new annotations for the first two datasets to support the ANACTO task.
The proposed approach outperforms relevant baseline methods on these benchmarks. The authors also conduct ablation studies to understand the effectiveness of their method and the baselines under different conditions.
Critical Analysis
The paper addresses an important and challenging problem in computer vision and egocentric video understanding. The authors' transformer-based approach seems well-suited to the task, as it can effectively capture the spatial and temporal relationships between the person, their actions, and the objects in the environment.
However, the paper does not discuss potential limitations or edge cases of the proposed method. It would be helpful to understand how the model might perform in more complex or noisy environments, or with a wider variety of object types and interactions.
Additionally, the paper could benefit from a more in-depth discussion of the practical applications and implications of being able to anticipate the next active object. How might this capability be leveraged in real-world scenarios, such as human-robot interaction or assistive technologies?
Conclusion
This paper introduces the novel task of "Anticipating the Next ACTive Object" (ANACTO) and proposes a transformer-based solution to address it. The authors demonstrate the effectiveness of their approach on several benchmark datasets, outperforming relevant baselines.
The ability to anticipate the location of the next object a person will interact with, before the interaction occurs, could have significant implications for a range of applications, from robotics and automation to assistive technologies and human-computer interaction. Further research in this area could lead to important advancements in egocentric video understanding and real-world perception and prediction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Anticipating Next Active Objects for Egocentric Videos
Sanket Thakur, Cigdem Beyan, Pietro Morerio, Vittorio Murino, Alessio Del Bue
This paper addresses the problem of anticipating the next-active-object location in the future, for a given egocentric video clip where the contact might happen, before any action takes place. The problem is considerably hard, as we aim at estimating the position of such objects in a scenario where the observed clip and the action segment are separated by the so-called ``time to contact'' (TTC) segment. Many methods have been proposed to anticipate the action of a person based on previous hand movements and interactions with the surroundings. However, there have been no attempts to investigate the next possible interactable object, and its future location with respect to the first-person's motion and the field-of-view drift during the TTC window. We define this as the task of Anticipating the Next ACTive Object (ANACTO). To this end, we propose a transformer-based self-attention framework to identify and locate the next-active-object in an egocentric clip. We benchmark our method on three datasets: EpicKitchens-100, EGTEA+ and Ego4D. We also provide annotations for the first two datasets. Our approach performs best compared to relevant baseline methods. We also conduct ablation studies to understand the effectiveness of the proposed and baseline methods on varying conditions. Code and ANACTO task annotations will be made available upon paper acceptance.
Read more5/2/2024
🎲
0
Anticipating Object State Changes
Victoria Manousaki, Konstantinos Bacharidis, Filippos Gouidis, Konstantinos Papoutsakis, Dimitris Plexousakis, Antonis Argyros
Anticipating object state changes in images and videos is a challenging problem whose solution has important implications in vision-based scene understanding, automated monitoring systems, and action planning. In this work, we propose the first method for solving this problem. The proposed method predicts object state changes that will occur in the near future as a result of yet unseen human actions. To address this new problem, we propose a novel framework that integrates learnt visual features that represent the recent visual information, with natural language (NLP) features that represent past object state changes and actions. Leveraging the extensive and challenging Ego4D dataset which provides a large-scale collection of first-person perspective videos across numerous interaction scenarios, we introduce new curated annotation data for the object state change anticipation task (OSCA), noted as Ego4D-OSCA. An extensive experimental evaluation was conducted that demonstrates the efficacy of the proposed method in predicting object state changes in dynamic scenarios. The proposed work underscores the potential of integrating video and linguistic cues to enhance the predictive performance of video understanding systems. Moreover, it lays the groundwork for future research on the new task of object state change anticipation. The source code and the new annotation data (Ego4D-OSCA) will be made publicly available.
Read more5/22/2024

0
Short-term Object Interaction Anticipation with Disentangled Object Detection @ Ego4D Short Term Object Interaction Anticipation Challenge
Hyunjin Cho, Dong Un Kang, Se Young Chun
Short-term object interaction anticipation is an important task in egocentric video analysis, including precise predictions of future interactions and their timings as well as the categories and positions of the involved active objects. To alleviate the complexity of this task, our proposed method, SOIA-DOD, effectively decompose it into 1) detecting active object and 2) classifying interaction and predicting their timing. Our method first detects all potential active objects in the last frame of egocentric video by fine-tuning a pre-trained YOLOv9. Then, we combine these potential active objects as query with transformer encoder, thereby identifying the most promising next active object and predicting its future interaction and time-to-contact. Experimental results demonstrate that our method outperforms state-of-the-art models on the challenge test set, achieving the best performance in predicting next active objects and their interactions. Finally, our proposed ranked the third overall top-5 mAP when including time-to-contact predictions. The source code is available at https://github.com/KeenyJin/SOIA-DOD.
Read more7/9/2024
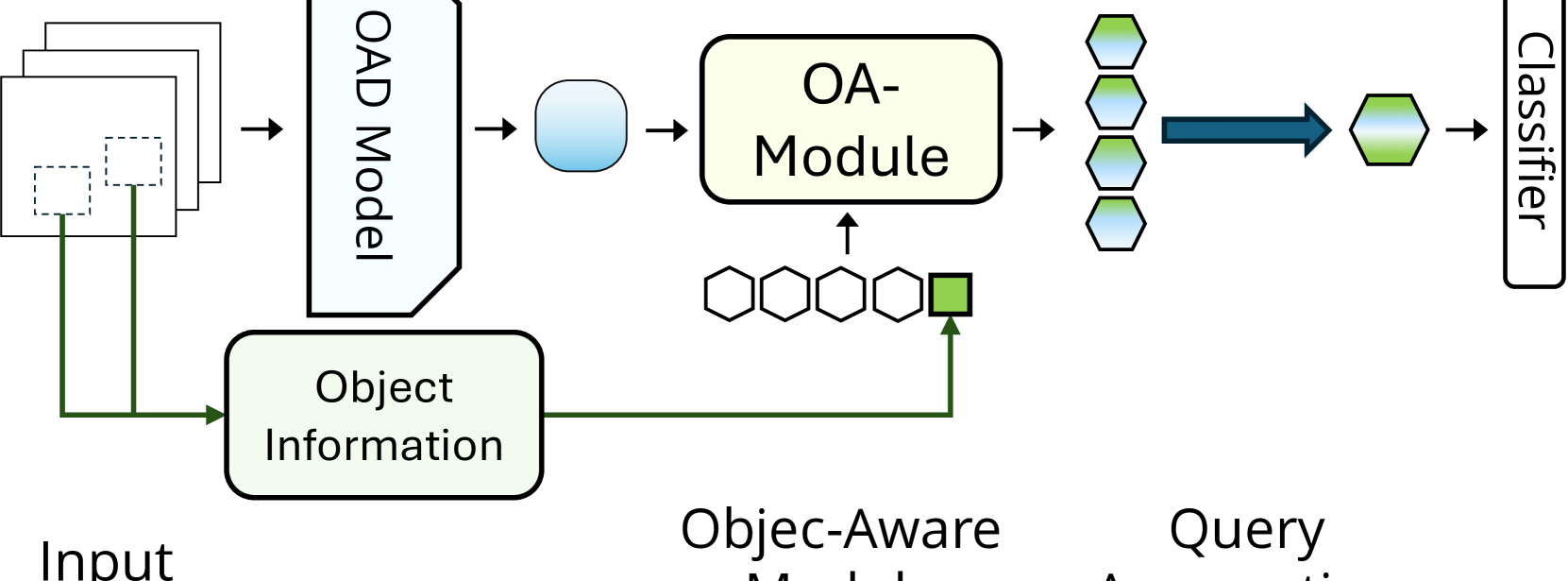
0
Object Aware Egocentric Online Action Detection
Joungbin An, Yunsu Park, Hyolim Kang, Seon Joo Kim
Advancements in egocentric video datasets like Ego4D, EPIC-Kitchens, and Ego-Exo4D have enriched the study of first-person human interactions, which is crucial for applications in augmented reality and assisted living. Despite these advancements, current Online Action Detection methods, which efficiently detect actions in streaming videos, are predominantly designed for exocentric views and thus fail to capitalize on the unique perspectives inherent to egocentric videos. To address this gap, we introduce an Object-Aware Module that integrates egocentric-specific priors into existing OAD frameworks, enhancing first-person footage interpretation. Utilizing object-specific details and temporal dynamics, our module improves scene understanding in detecting actions. Validated extensively on the Epic-Kitchens 100 dataset, our work can be seamlessly integrated into existing models with minimal overhead and bring consistent performance enhancements, marking an important step forward in adapting action detection systems to egocentric video analysis.
Read more6/4/2024