Object Aware Egocentric Online Action Detection
2406.01079
0
0
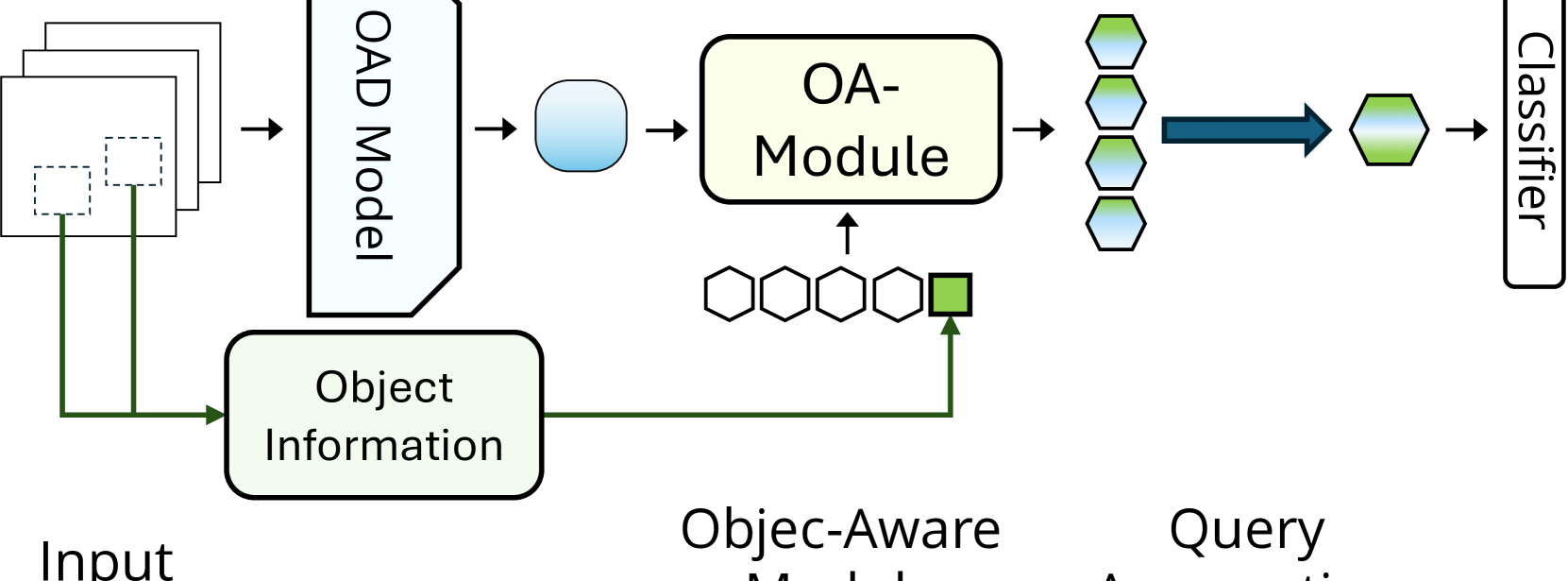
Abstract
Advancements in egocentric video datasets like Ego4D, EPIC-Kitchens, and Ego-Exo4D have enriched the study of first-person human interactions, which is crucial for applications in augmented reality and assisted living. Despite these advancements, current Online Action Detection methods, which efficiently detect actions in streaming videos, are predominantly designed for exocentric views and thus fail to capitalize on the unique perspectives inherent to egocentric videos. To address this gap, we introduce an Object-Aware Module that integrates egocentric-specific priors into existing OAD frameworks, enhancing first-person footage interpretation. Utilizing object-specific details and temporal dynamics, our module improves scene understanding in detecting actions. Validated extensively on the Epic-Kitchens 100 dataset, our work can be seamlessly integrated into existing models with minimal overhead and bring consistent performance enhancements, marking an important step forward in adapting action detection systems to egocentric video analysis.
Create account to get full access
Overview
• This research paper proposes an "Object Aware Egocentric Online Action Detection" system that can detect actions in real-time using a first-person (egocentric) video perspective. • The key innovation is incorporating object-level awareness to improve the accuracy and speed of action detection, which is critical for applications like assistive robotics and augmented reality. • The system leverages object detection and tracking, along with temporal modeling, to recognize actions as they occur in the video stream.
Plain English Explanation
• Imagine you're wearing a camera on your head that's constantly recording your everyday activities. The goal of this research is to create a system that can watch that video in real-time and automatically detect the actions you're performing. • This is useful for all sorts of applications, like helping a robot understand what you're doing so it can assist you, or enhancing augmented reality experiences by overlaying digital information based on your current actions. • The key insight is that by paying attention to the objects you're interacting with - like a cup, a book, a laptop, etc. - the system can more accurately and quickly figure out what you're doing, compared to just looking at the overall motion in the video. • So the system combines object detection (identifying the objects in the video) with tracking those objects over time, and then using that information to recognize the actions you're performing.
Technical Explanation
• The proposed system takes an egocentric video as input and performs online action detection - meaning it can recognize actions as they happen in real-time, rather than after the fact. • It uses an object detector to identify the objects present in each video frame, and then tracks those objects over time using a dedicated tracking module. • The system also has a temporal modeling component that analyzes the sequence of object interactions to recognize the ongoing action. • This object-aware approach outperforms prior work on standard egocentric action recognition benchmarks, demonstrating the benefits of incorporating object-level information.
Critical Analysis
• The paper provides a thorough technical evaluation of the proposed system, including comparisons to state-of-the-art methods on multiple datasets. • However, the authors do not discuss any potential limitations or failure cases of the approach, such as how it might perform in more cluttered or ambiguous environments. • Additionally, the paper focuses solely on action recognition, but does not explore other related tasks like action prediction or interaction reasoning, which could provide a more comprehensive understanding of egocentric activities.
Conclusion
• This work presents a novel approach to real-time egocentric action detection that leverages object-level awareness to improve accuracy and speed. • The object-aware temporal modeling technique outperforms previous methods, highlighting the importance of incorporating rich contextual information for understanding human activities from a first-person perspective. • While the technical evaluation is solid, further research is needed to explore the limitations and broader applicability of this approach, particularly for real-world deployments in complex environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Cross-view Action Recognition Understanding From Exocentric to Egocentric Perspective
Thanh-Dat Truong, Khoa Luu
0
0
Understanding action recognition in egocentric videos has emerged as a vital research topic with numerous practical applications. With the limitation in the scale of egocentric data collection, learning robust deep learning-based action recognition models remains difficult. Transferring knowledge learned from the large-scale exocentric data to the egocentric data is challenging due to the difference in videos across views. Our work introduces a novel cross-view learning approach to action recognition (CVAR) that effectively transfers knowledge from the exocentric to the selfish view. First, we present a novel geometric-based constraint into the self-attention mechanism in Transformer based on analyzing the camera positions between two views. Then, we propose a new cross-view self-attention loss learned on unpaired cross-view data to enforce the self-attention mechanism learning to transfer knowledge across views. Finally, to further improve the performance of our cross-view learning approach, we present the metrics to measure the correlations in videos and attention maps effectively. Experimental results on standard egocentric action recognition benchmarks, i.e., Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100, have shown our approach's effectiveness and state-of-the-art performance.
5/16/2024

In My Perspective, In My Hands: Accurate Egocentric 2D Hand Pose and Action Recognition
Wiktor Mucha, Martin Kampel
0
0
Action recognition is essential for egocentric video understanding, allowing automatic and continuous monitoring of Activities of Daily Living (ADLs) without user effort. Existing literature focuses on 3D hand pose input, which requires computationally intensive depth estimation networks or wearing an uncomfortable depth sensor. In contrast, there has been insufficient research in understanding 2D hand pose for egocentric action recognition, despite the availability of user-friendly smart glasses in the market capable of capturing a single RGB image. Our study aims to fill this research gap by exploring the field of 2D hand pose estimation for egocentric action recognition, making two contributions. Firstly, we introduce two novel approaches for 2D hand pose estimation, namely EffHandNet for single-hand estimation and EffHandEgoNet, tailored for an egocentric perspective, capturing interactions between hands and objects. Both methods outperform state-of-the-art models on H2O and FPHA public benchmarks. Secondly, we present a robust action recognition architecture from 2D hand and object poses. This method incorporates EffHandEgoNet, and a transformer-based action recognition method. Evaluated on H2O and FPHA datasets, our architecture has a faster inference time and achieves an accuracy of 91.32% and 94.43%, respectively, surpassing state of the art, including 3D-based methods. Our work demonstrates that using 2D skeletal data is a robust approach for egocentric action understanding. Extensive evaluation and ablation studies show the impact of the hand pose estimation approach, and how each input affects the overall performance.
4/16/2024

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024
📈
EgoVideo: Exploring Egocentric Foundation Model and Downstream Adaptation
Baoqi Pei, Guo Chen, Jilan Xu, Yuping He, Yicheng Liu, Kanghua Pan, Yifei Huang, Yali Wang, Tong Lu, Limin Wang, Yu Qiao
0
0
In this report, we present our solutions to the EgoVis Challenges in CVPR 2024, including five tracks in the Ego4D challenge and three tracks in the EPIC-Kitchens challenge. Building upon the video-language two-tower model and leveraging our meticulously organized egocentric video data, we introduce a novel foundation model called EgoVideo. This model is specifically designed to cater to the unique characteristics of egocentric videos and provides strong support for our competition submissions. In the Ego4D challenges, we tackle various tasks including Natural Language Queries, Step Grounding, Moment Queries, Short-term Object Interaction Anticipation, and Long-term Action Anticipation. In addition, we also participate in the EPIC-Kitchens challenge, where we engage in the Action Recognition, Multiple Instance Retrieval, and Domain Adaptation for Action Recognition tracks. By adapting EgoVideo to these diverse tasks, we showcase its versatility and effectiveness in different egocentric video analysis scenarios, demonstrating the powerful representation ability of EgoVideo as an egocentric foundation model. Our codebase and pretrained models are publicly available at https://github.com/OpenGVLab/EgoVideo.
7/1/2024