Any360D: Towards 360 Depth Anything with Unlabeled 360 Data and Mobius Spatial Augmentation
2406.13378
0
0
Abstract
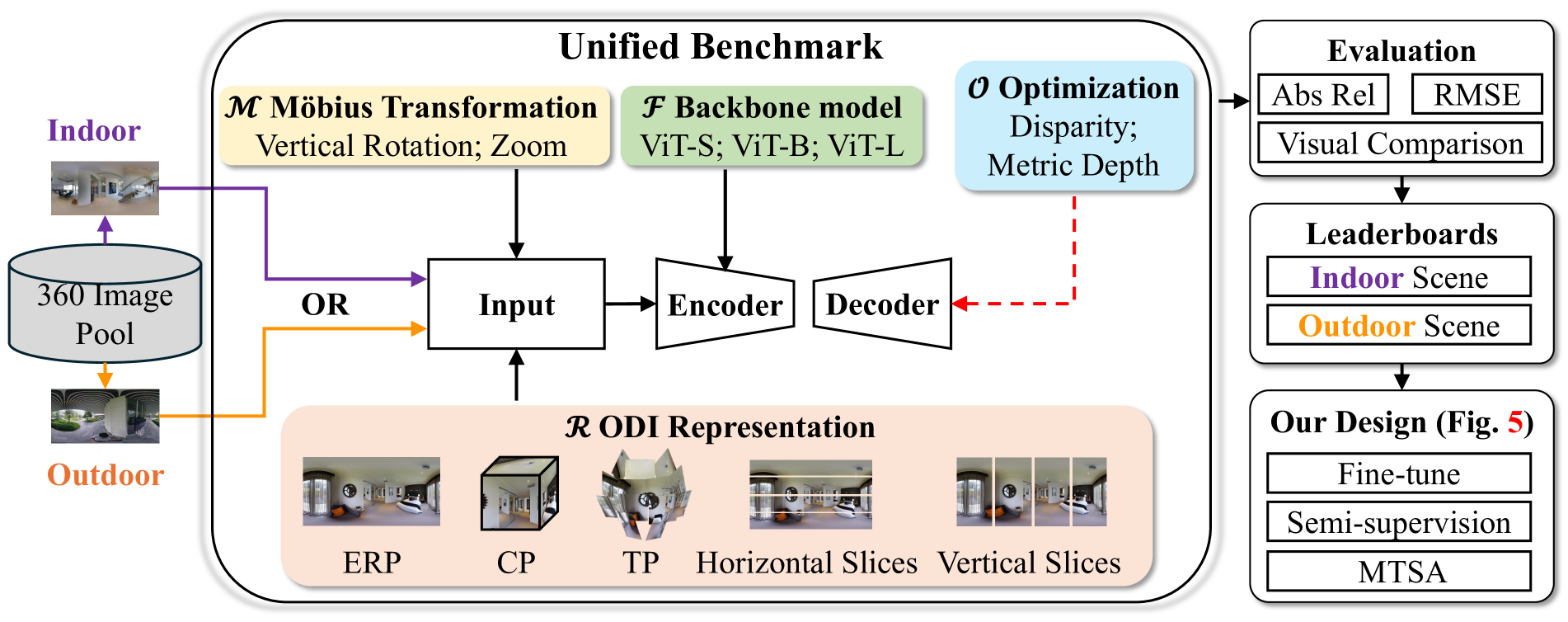
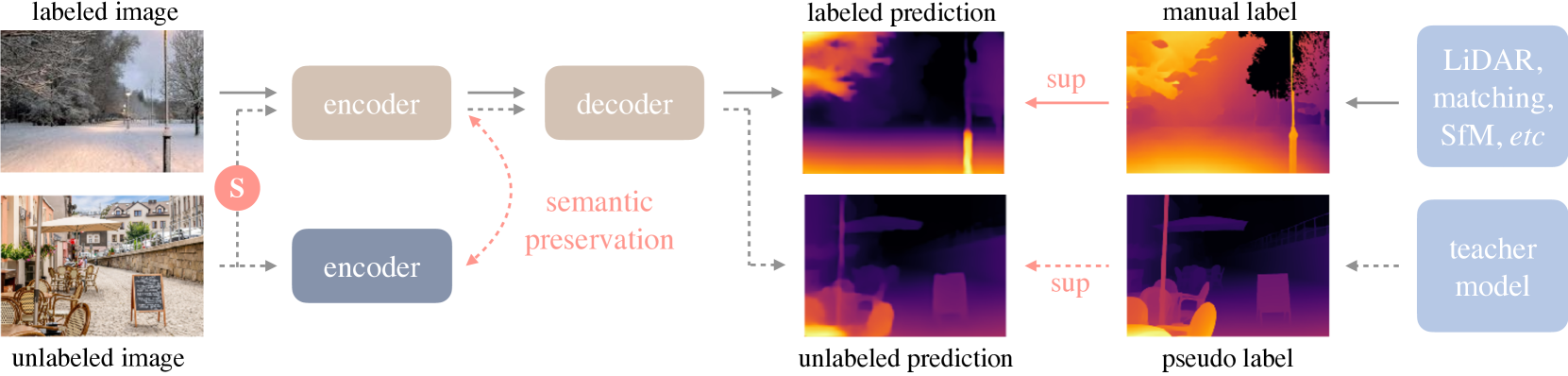
Recently, Depth Anything Model (DAM) - a type of depth foundation model - reveals impressive zero-shot capacity for diverse perspective images. Despite its success, it remains an open question regarding DAM's performance on 360 images that enjoy a large field-of-view (180x360) but suffer from spherical distortions. To this end, we establish, to our knowledge, the first benchmark that aims to 1) evaluate the performance of DAM on 360 images and 2) develop a powerful 360 DAM for the benefit of the community. For this, we conduct a large suite of experiments that consider the key properties of 360 images, e.g., different 360 representations, various spatial transformations, and diverse indoor and outdoor scenes. This way, our benchmark unveils some key findings, e.g., DAM is less effective for diverse 360 scenes and sensitive to spatial transformations. To address these challenges, we first collect a large-scale unlabeled dataset including diverse indoor and outdoor scenes. We then propose a semi-supervised learning (SSL) framework to learn a 360 DAM, dubbed Any360D. Under the umbrella of SSL, Any360D first learns a teacher model by fine-tuning DAM via metric depth supervision. Then, we train the student model by uncovering the potential of large-scale unlabeled data with pseudo labels from the teacher model. Mobius transformation-based spatial augmentation (MTSA) is proposed to impose consistency regularization between the unlabeled data and spatially transformed ones. This subtly improves the student model's robustness to various spatial transformations even under severe distortions. Extensive experiments demonstrate that Any360D outperforms DAM and many prior data-specific models, e.g., PanoFormer, across diverse scenes, showing impressive zero-shot capacity for being a 360 depth foundation model.
Create account to get full access
Overview
- This paper proposes a novel approach called "Any360D" for 360-degree depth estimation using unlabeled 360-degree data and a technique called Möbius Spatial Augmentation.
- The key ideas are to leverage large-scale unlabeled 360-degree data to train depth estimation models, and to use Möbius Spatial Augmentation to improve the models' performance.
- The paper demonstrates the effectiveness of the Any360D approach on several 360-degree depth estimation benchmarks, showing significant improvements over previous state-of-the-art methods.
Plain English Explanation
The researchers have developed a new way to estimate the depth, or distance, of objects in 360-degree panoramic images. Typically, training depth estimation models requires a lot of labeled data, which can be time-consuming and expensive to obtain.
The Any360D approach gets around this by using a large amount of unlabeled 360-degree data instead. The researchers use a mathematical technique called Möbius Spatial Augmentation to transform the 360-degree images in ways that help the depth estimation model learn better.
The results show that the Any360D method can produce much more accurate 360-degree depth estimates compared to previous techniques. This could be very useful for applications like virtual reality, autonomous vehicles, and robotics, where understanding the 3D structure of the environment is crucial.
Technical Explanation
The paper proposes the "Any360D" method for 360-degree depth estimation, which leverages large-scale unlabeled 360-degree data and a novel Möbius Spatial Augmentation technique.
The key innovations are:
-
Leveraging Unlabeled 360-degree Data: Rather than relying on expensive, manually labeled 360-degree depth data, the Any360D approach uses self-supervised learning on a large corpus of unlabeled 360-degree imagery. This allows the depth estimation model to learn from a much broader range of visual data.
-
Möbius Spatial Augmentation: The researchers introduce a Möbius Spatial Augmentation technique that applies specific geometric transformations to the 360-degree images. This helps the depth estimation model learn more robust features that generalize better to diverse 360-degree scenes.
-
Benchmarking Performance: The paper evaluates the Any360D method on several 360-degree depth estimation benchmarks, including depth-anywhere-enhancing-360-monocular-depth-estimation, depth-anything-unleashing-power-large-scale-unlabeled, depth-anything-v2, elite360d-towards-efficient-360-depth-estimation-via, and 360loc-dataset-benchmark-omnidirectional-visual-localization-cross. The results demonstrate significant improvements over previous state-of-the-art methods.
Critical Analysis
The paper presents a compelling approach to 360-degree depth estimation, but there are a few potential limitations and areas for further research:
-
Dependence on Unlabeled Data: While the use of unlabeled 360-degree data is a strength of the Any360D method, the quality and diversity of this data could still impact the final depth estimation performance. Further research is needed to understand the specific data requirements and potential biases.
-
Möbius Spatial Augmentation: The Möbius Spatial Augmentation technique is a novel contribution, but it's not clear how this compares to other more standard data augmentation methods. Additional analysis and comparisons would help contextualize the significance of this component.
-
Generalization to Real-World Applications: The paper focuses on benchmark performance, but more research is needed to understand how the Any360D method would perform in real-world 360-degree depth estimation applications, such as virtual reality or autonomous navigation.
Overall, the Any360D approach represents an interesting and promising step forward in 360-degree depth estimation, but there are still opportunities to further explore the method's limitations and potential.
Conclusion
The Any360D paper presents a novel approach for 360-degree depth estimation that leverages large-scale unlabeled 360-degree data and a Möbius Spatial Augmentation technique. The results demonstrate significant improvements over previous state-of-the-art methods on several 360-degree depth estimation benchmarks.
This work has important implications for applications that rely on accurate 3D understanding of 360-degree environments, such as virtual reality, robotics, and autonomous vehicles. By reducing the need for expensive, manually labeled depth data, the Any360D method could help enable more widespread adoption of 360-degree depth estimation technologies.
Further research is needed to fully understand the method's limitations and generalization to real-world scenarios, but the paper's core contributions represent an exciting advance in the field of 360-degree computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Depth Anywhere: Enhancing 360 Monocular Depth Estimation via Perspective Distillation and Unlabeled Data Augmentation
Ning-Hsu Wang, Yu-Lun Liu
0
0
Accurately estimating depth in 360-degree imagery is crucial for virtual reality, autonomous navigation, and immersive media applications. Existing depth estimation methods designed for perspective-view imagery fail when applied to 360-degree images due to different camera projections and distortions, whereas 360-degree methods perform inferior due to the lack of labeled data pairs. We propose a new depth estimation framework that utilizes unlabeled 360-degree data effectively. Our approach uses state-of-the-art perspective depth estimation models as teacher models to generate pseudo labels through a six-face cube projection technique, enabling efficient labeling of depth in 360-degree images. This method leverages the increasing availability of large datasets. Our approach includes two main stages: offline mask generation for invalid regions and an online semi-supervised joint training regime. We tested our approach on benchmark datasets such as Matterport3D and Stanford2D3D, showing significant improvements in depth estimation accuracy, particularly in zero-shot scenarios. Our proposed training pipeline can enhance any 360 monocular depth estimator and demonstrates effective knowledge transfer across different camera projections and data types. See our project page for results: https://albert100121.github.io/Depth-Anywhere/
6/19/2024
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
0
0
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a better depth-conditioned ControlNet. Our models are released at https://github.com/LiheYoung/Depth-Anything.
4/9/2024
Composition Vision-Language Understanding via Segment and Depth Anything Model
Mingxiao Huo, Pengliang Ji, Haotian Lin, Junchen Liu, Yixiao Wang, Yijun Chen
0
0
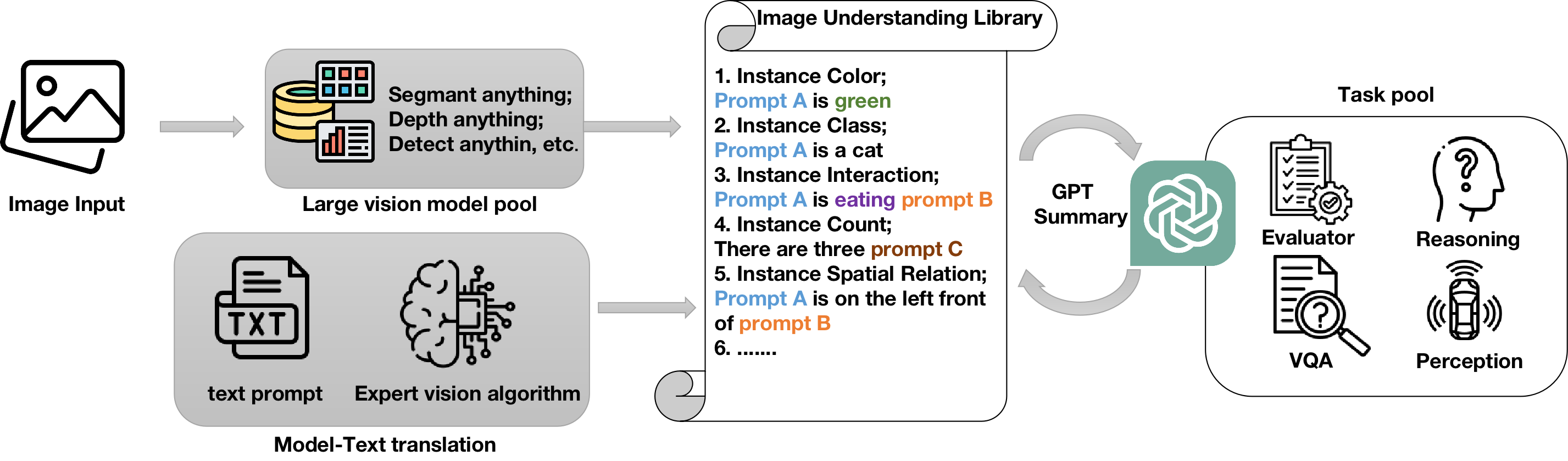
We introduce a pioneering unified library that leverages depth anything, segment anything models to augment neural comprehension in language-vision model zero-shot understanding. This library synergizes the capabilities of the Depth Anything Model (DAM), Segment Anything Model (SAM), and GPT-4V, enhancing multimodal tasks such as vision-question-answering (VQA) and composition reasoning. Through the fusion of segmentation and depth analysis at the symbolic instance level, our library provides nuanced inputs for language models, significantly advancing image interpretation. Validated across a spectrum of in-the-wild real-world images, our findings showcase progress in vision-language models through neural-symbolic integration. This novel approach melds visual and language analysis in an unprecedented manner. Overall, our library opens new directions for future research aimed at decoding the complexities of the real world through advanced multimodal technologies and our code is available at url{https://github.com/AnthonyHuo/SAM-DAM-for-Compositional-Reasoning}.
6/28/2024
Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
0
0
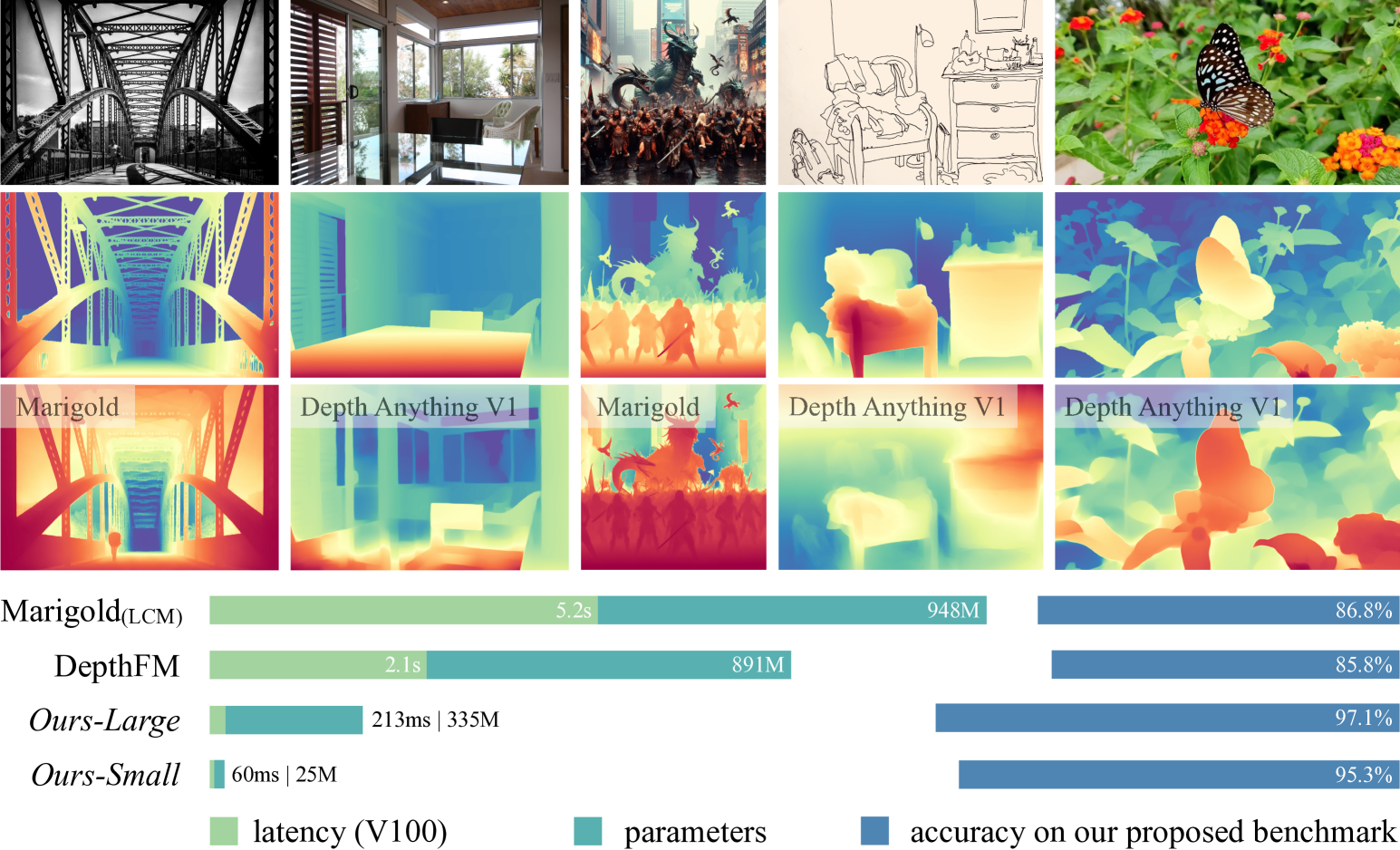
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
6/14/2024