AnyV2V: A Tuning-Free Framework For Any Video-to-Video Editing Tasks
2403.14468
0
0

Abstract
In the dynamic field of digital content creation using generative models, state-of-the-art video editing models still do not offer the level of quality and control that users desire. Previous works on video editing either extended from image-based generative models in a zero-shot manner or necessitated extensive fine-tuning, which can hinder the production of fluid video edits. Furthermore, these methods frequently rely on textual input as the editing guidance, leading to ambiguities and limiting the types of edits they can perform. Recognizing these challenges, we introduce AnyV2V, a novel tuning-free paradigm designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model to modify the first frame, (2) utilizing an existing image-to-video generation model to generate the edited video through temporal feature injection. AnyV2V can leverage any existing image editing tools to support an extensive array of video editing tasks, including prompt-based editing, reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. AnyV2V can also support any video length. Our evaluation indicates that AnyV2V significantly outperforms other baseline methods in automatic and human evaluations by significant margin, maintaining visual consistency with the source video while achieving high-quality edits across all the editing tasks.
Create account to get full access
Overview
- The paper presents AnyV2V, a plug-and-play framework for video-to-video editing tasks.
- AnyV2V is designed to be a flexible and versatile solution for various video editing applications.
- The framework leverages diffusion models to enable a wide range of video editing capabilities, from style transfer to object manipulation.
Plain English Explanation
The researchers have developed a new system called AnyV2V that makes it easier to edit videos in different ways. Rather than having to use specialized software for each type of video editing task, AnyV2V is a flexible framework that can handle a variety of video editing applications.
At the core of AnyV2V are diffusion models, which are a type of artificial intelligence that can generate and manipulate images and videos. By using diffusion models, AnyV2V can enable things like transferring the style of one video to another, removing or adding objects in a video, and more.
The key advantage of AnyV2V is that it provides a "plug-and-play" solution, meaning users don't have to learn complex video editing tools or write custom code for each task. Instead, they can simply plug in the video they want to edit and the desired editing effect, and AnyV2V will handle the rest.
This makes video editing much more accessible and versatile, as users don't need specialized expertise to perform advanced editing on their videos. The researchers hope AnyV2V will open up new creative possibilities for a wide range of video creators and applications.
Technical Explanation
The paper introduces AnyV2V, a novel plug-and-play framework for video-to-video (V2V) editing tasks. AnyV2V leverages diffusion models, a type of generative AI, to enable a wide range of video editing capabilities in a flexible and versatile manner.
Unlike previous video editing systems that often require custom models or programming for each task, AnyV2V is designed to be a unified solution. By utilizing diffusion models, AnyV2V can perform a variety of editing operations, such as I2V-Adapter style transfer, InstructVid2Vid text-guided editing, and UniEdit object manipulation, without the need for specialized models or extensive fine-tuning.
The core of AnyV2V is a diffusion-based video generator that can translate an input video into a desired output video based on a given condition, such as a reference image or a natural language instruction. The framework also includes a content-aware temporal propagation module to ensure temporal consistency in the edited videos.
The authors evaluate AnyV2V on a range of video editing tasks and benchmark datasets, demonstrating its versatility and effectiveness across different applications. The results show that AnyV2V can outperform or match the performance of specialized models while providing a unified and user-friendly interface for video editing.
Critical Analysis
The AnyV2V framework presents a promising approach to video editing, addressing the limitations of existing solutions that often require specialized models or extensive customization for each task. By leveraging the power of diffusion models, the researchers have developed a flexible and versatile system that can handle a wide range of video editing applications.
One potential limitation of the AnyV2V framework is the computational complexity and resource requirements of the diffusion models used. Diffusion models can be computationally intensive, which may limit their real-time or interactive applications, especially on resource-constrained devices. The authors acknowledge this challenge and suggest exploring ways to optimize the diffusion model for better efficiency.
Additionally, while the framework demonstrates strong performance on benchmark datasets, its ability to handle real-world, diverse video content with complex editing requirements may still need further validation. The researchers could consider expanding the evaluation to include more diverse and challenging video editing scenarios to better assess the framework's robustness and generalizability.
Future research could also explore ways to enhance the user experience and interactivity of the AnyV2V framework, such as by incorporating more intuitive control mechanisms or providing better visual feedback during the editing process. Integrating AnyV2V with existing video editing workflows and tools could also increase its adoption and practical utility for a broader range of users.
Conclusion
The AnyV2V framework presented in this paper is a significant step towards a more unified and versatile approach to video editing. By leveraging the power of diffusion models, the researchers have developed a plug-and-play system that can handle a wide range of video editing tasks, from style transfer to object manipulation, without the need for specialized models or extensive customization.
The flexibility and extensibility of AnyV2V have the potential to democratize video editing, making advanced editing capabilities more accessible to a broader range of creators and applications. As the researchers continue to refine and optimize the framework, it could become a valuable tool for various video-centric industries, from content creation to video analysis and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
0
0
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
5/28/2024
🌿
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, Yueting Zhuang
0
0
We introduce InstructVid2Vid, an end-to-end diffusion-based methodology for video editing guided by human language instructions. Our approach empowers video manipulation guided by natural language directives, eliminating the need for per-example fine-tuning or inversion. The proposed InstructVid2Vid model modifies a pretrained image generation model, Stable Diffusion, to generate a time-dependent sequence of video frames. By harnessing the collective intelligence of disparate models, we engineer a training dataset rich in video-instruction triplets, which is a more cost-efficient alternative to collecting data in real-world scenarios. To enhance the coherence between successive frames within the generated videos, we propose the Inter-Frames Consistency Loss and incorporate it during the training process. With multimodal classifier-free guidance during the inference stage, the generated videos is able to resonate with both the input video and the accompanying instructions. Experimental results demonstrate that InstructVid2Vid is capable of generating high-quality, temporally coherent videos and performing diverse edits, including attribute editing, background changes, and style transfer. These results underscore the versatility and effectiveness of our proposed method.
5/30/2024

UniEdit: A Unified Tuning-Free Framework for Video Motion and Appearance Editing
Jianhong Bai, Tianyu He, Yuchi Wang, Junliang Guo, Haoji Hu, Zuozhu Liu, Jiang Bian
0
0
Recent advances in text-guided video editing have showcased promising results in appearance editing (e.g., stylization). However, video motion editing in the temporal dimension (e.g., from eating to waving), which distinguishes video editing from image editing, is underexplored. In this work, we present UniEdit, a tuning-free framework that supports both video motion and appearance editing by harnessing the power of a pre-trained text-to-video generator within an inversion-then-generation framework. To realize motion editing while preserving source video content, based on the insights that temporal and spatial self-attention layers encode inter-frame and intra-frame dependency respectively, we introduce auxiliary motion-reference and reconstruction branches to produce text-guided motion and source features respectively. The obtained features are then injected into the main editing path via temporal and spatial self-attention layers. Extensive experiments demonstrate that UniEdit covers video motion editing and various appearance editing scenarios, and surpasses the state-of-the-art methods. Our code will be publicly available.
4/9/2024
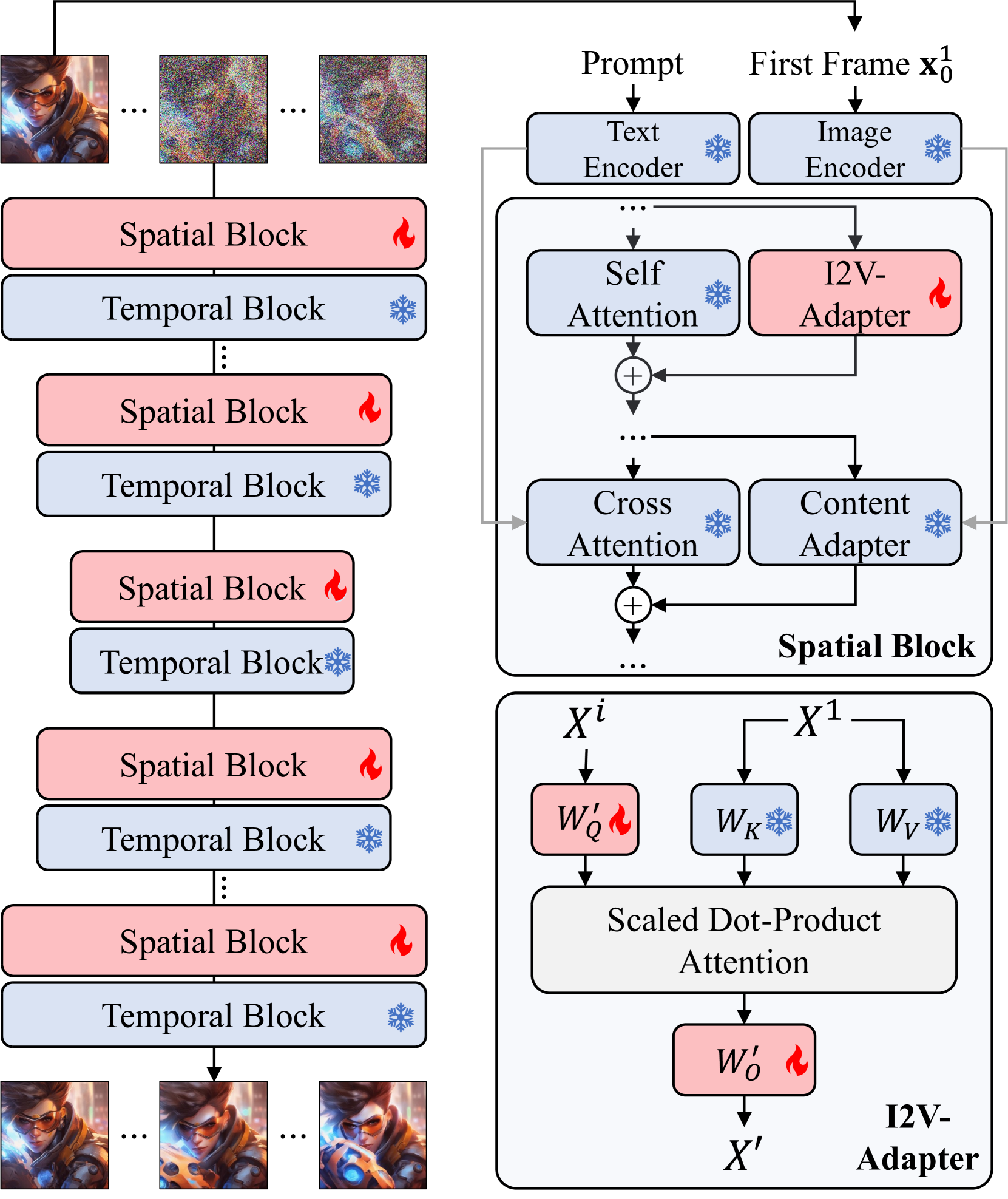
I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, Haibin Huang, Chongyang Ma
0
0
Text-guided image-to-video (I2V) generation aims to generate a coherent video that preserves the identity of the input image and semantically aligns with the input prompt. Existing methods typically augment pretrained text-to-video (T2V) models by either concatenating the image with noised video frames channel-wise before being fed into the model or injecting the image embedding produced by pretrained image encoders in cross-attention modules. However, the former approach often necessitates altering the fundamental weights of pretrained T2V models, thus restricting the model's compatibility within the open-source communities and disrupting the model's prior knowledge. Meanwhile, the latter typically fails to preserve the identity of the input image. We present I2V-Adapter to overcome such limitations. I2V-Adapter adeptly propagates the unnoised input image to subsequent noised frames through a cross-frame attention mechanism, maintaining the identity of the input image without any changes to the pretrained T2V model. Notably, I2V-Adapter only introduces a few trainable parameters, significantly alleviating the training cost and also ensures compatibility with existing community-driven personalized models and control tools. Moreover, we propose a novel Frame Similarity Prior to balance the motion amplitude and the stability of generated videos through two adjustable control coefficients. Our experimental results demonstrate that I2V-Adapter is capable of producing high-quality videos. This performance, coupled with its agility and adaptability, represents a substantial advancement in the field of I2V, particularly for personalized and controllable applications.
6/28/2024