I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models

0
Sign in to get full access
Overview
- This paper introduces a new image-to-video (I2V) adapter that can be used to condition video diffusion models on input images.
- The I2V adapter is a general-purpose module that can be applied to various video diffusion models to enable image-to-video generation.
- The authors demonstrate the effectiveness of their I2V adapter on several benchmark datasets, showing that it can generate high-quality videos conditioned on a single input image.
Plain English Explanation
The paper presents a new technique called the I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models that allows video generation models to create videos based on a single input image. This is a valuable capability, as it enables users to generate dynamic video content from a static image.
The key innovation is the I2V adapter, which is a special module that can be added to existing video diffusion models to give them the ability to generate videos from images. The authors show that this adapter can be used with a variety of different video diffusion models, making it a general-purpose solution.
To demonstrate the effectiveness of their approach, the researchers tested the I2V adapter on several video datasets. They found that it could generate high-quality videos that were well-aligned with the input images, indicating that the adapter successfully bridged the gap between static images and dynamic video generation.
This research builds on previous work in areas like text-to-image generation, video diffusion models, and multimodal video transfer learning. By combining these ideas, the I2V adapter represents a significant advance in the field of generative video modeling, potentially enabling a wide range of applications where users can create dynamic video content from static images.
Technical Explanation
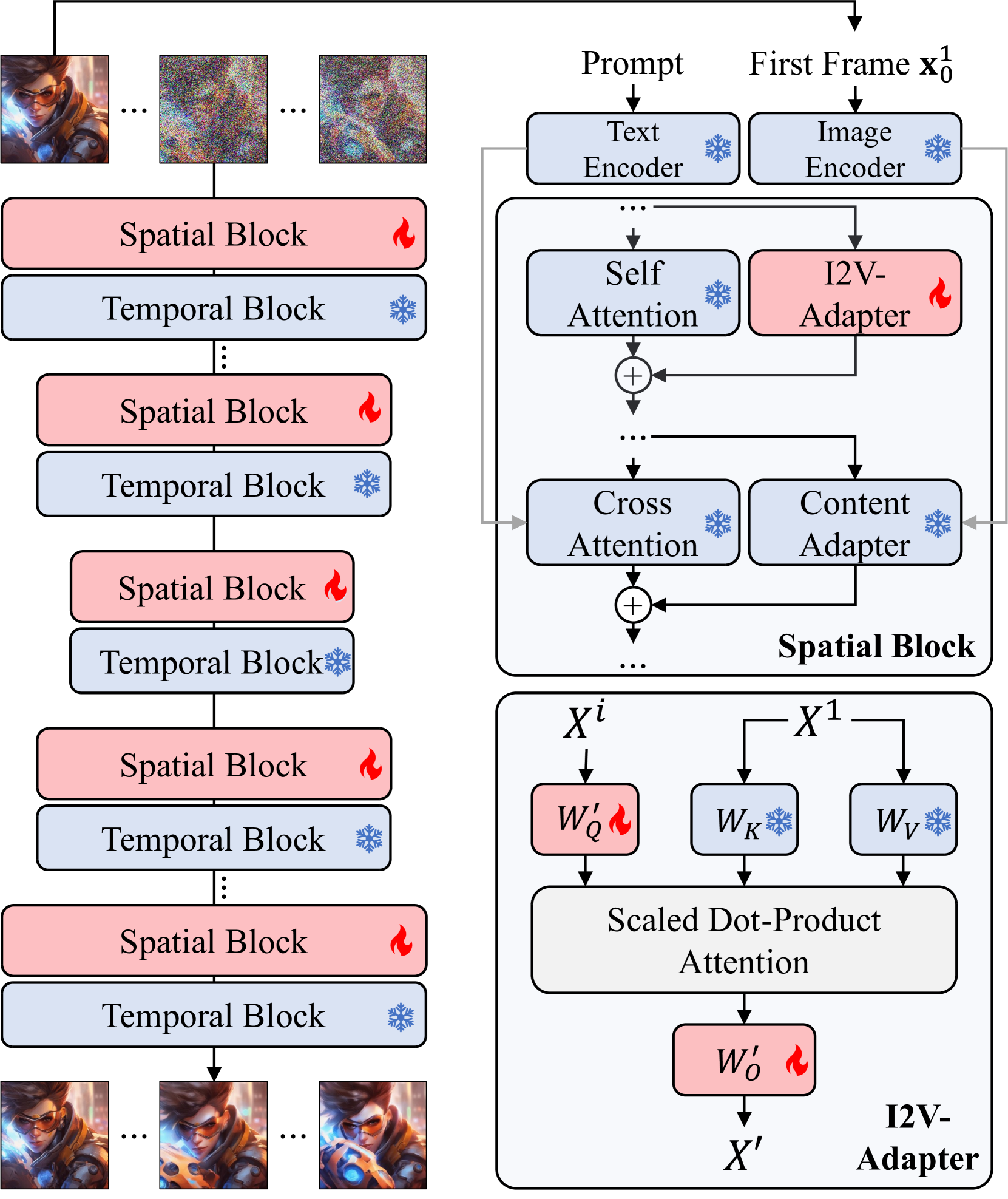
The core of this work is the I2V (Image-to-Video) Adapter, a novel module that can be integrated into various video diffusion models to enable image-to-video generation. The authors demonstrate the application of the I2V Adapter on top of the BiVDiff video diffusion model, as well as the MV-Adapter model.
The I2V Adapter consists of several key components:
- Image Encoder: This module encodes the input image into a compact latent representation, which can then be used to condition the video generation process.
- Temporal Adapter: This component introduces temporal information into the image latent representation, allowing the video diffusion model to generate dynamic video content.
- Diffusion Conditioning: The adapted image latent is then used to condition the video diffusion process, enabling the generation of videos that are well-aligned with the input image.
The authors evaluate their I2V Adapter on several benchmark datasets, including GenVideo and PoseAnimate. Their results demonstrate that the I2V Adapter can effectively bridge the gap between static images and dynamic video generation, producing high-quality videos that are closely tied to the input image content.
Critical Analysis
The I2V Adapter presented in this paper represents a significant advancement in the field of generative video modeling, addressing the challenge of conditioning video generation on static input images. The authors have shown the versatility of their approach by integrating the I2V Adapter with different video diffusion models, suggesting that it can be a general-purpose solution.
One potential limitation of the I2V Adapter is its reliance on the performance of the underlying video diffusion model. If the video diffusion model struggles to generate high-quality videos, the I2V Adapter may not be able to fully compensate for this limitation. Additionally, the authors do not provide a detailed analysis of the computational and memory requirements of the I2V Adapter, which could be an important consideration for real-world applications.
Further research could explore ways to improve the efficiency and scalability of the I2V Adapter, as well as investigate its performance on more diverse video datasets and generation tasks. Exploring the potential of the I2V Adapter in applications such as video editing, animation, and content creation could also be a fruitful area of investigation.
Conclusion
The I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models presented in this paper represents a significant advancement in the field of generative video modeling. By introducing a versatile adapter module that can be integrated with various video diffusion models, the authors have enabled the generation of high-quality videos conditioned on static input images.
This research builds upon and combines several key developments in areas such as text-to-image generation, video diffusion models, and multimodal video transfer learning. The successful demonstration of the I2V Adapter on benchmark datasets suggests that it can be a valuable tool for a wide range of applications, from video editing and animation to content creation and beyond.
As the field of generative AI continues to evolve, innovations like the I2V Adapter will play an increasingly important role in unlocking new possibilities for dynamic, image-driven video generation. The authors' work lays the groundwork for further advancements in this exciting and rapidly growing area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, Haibin Huang, Chongyang Ma
Text-guided image-to-video (I2V) generation aims to generate a coherent video that preserves the identity of the input image and semantically aligns with the input prompt. Existing methods typically augment pretrained text-to-video (T2V) models by either concatenating the image with noised video frames channel-wise before being fed into the model or injecting the image embedding produced by pretrained image encoders in cross-attention modules. However, the former approach often necessitates altering the fundamental weights of pretrained T2V models, thus restricting the model's compatibility within the open-source communities and disrupting the model's prior knowledge. Meanwhile, the latter typically fails to preserve the identity of the input image. We present I2V-Adapter to overcome such limitations. I2V-Adapter adeptly propagates the unnoised input image to subsequent noised frames through a cross-frame attention mechanism, maintaining the identity of the input image without any changes to the pretrained T2V model. Notably, I2V-Adapter only introduces a few trainable parameters, significantly alleviating the training cost and also ensures compatibility with existing community-driven personalized models and control tools. Moreover, we propose a novel Frame Similarity Prior to balance the motion amplitude and the stability of generated videos through two adjustable control coefficients. Our experimental results demonstrate that I2V-Adapter is capable of producing high-quality videos. This performance, coupled with its agility and adaptability, represents a substantial advancement in the field of I2V, particularly for personalized and controllable applications.
Read more6/28/2024

0
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
Read more5/28/2024
🖼️
0
ZeroI2V: Zero-Cost Adaptation of Pre-trained Transformers from Image to Video
Xinhao Li, Yuhan Zhu, Limin Wang
Adapting image models to the video domain has emerged as an efficient paradigm for solving video recognition tasks. Due to the huge number of parameters and effective transferability of image models, performing full fine-tuning is less efficient and even unnecessary. Thus, recent research is shifting its focus toward parameter-efficient image-to-video adaptation. However, these adaptation strategies inevitably introduce extra computational costs to deal with the domain gap and temporal modeling in videos. In this paper, we present a new adaptation paradigm (ZeroI2V) to transfer the image transformers to video recognition tasks (i.e., introduce zero extra cost to the original models during inference). To achieve this goal, we present two core designs. First, to capture the dynamics in videos and reduce the difficulty of image-to-video adaptation, we exploit the flexibility of self-attention and introduce spatial-temporal dual-headed attention (STDHA). This approach efficiently endows the image transformers with temporal modeling capability at zero extra parameters and computation. Second, to handle the domain gap between images and videos, we propose a linear adaption strategy that utilizes lightweight densely placed linear adapters to fully transfer the frozen image models to video recognition. Thanks to the customized linear design, all newly added adapters could be easily merged with the original modules through structural reparameterization after training, enabling zero extra cost during inference. Extensive experiments on representative fully-supervised and few-shot video recognition benchmarks showcase that ZeroI2V can match or even outperform previous state-of-the-art methods while enjoying superior parameter and inference efficiency.
Read more7/12/2024

0
AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
Zhen Xing, Qi Dai, Zejia Weng, Zuxuan Wu, Yu-Gang Jiang
Text-guided video prediction (TVP) involves predicting the motion of future frames from the initial frame according to an instruction, which has wide applications in virtual reality, robotics, and content creation. Previous TVP methods make significant breakthroughs by adapting Stable Diffusion for this task. However, they struggle with frame consistency and temporal stability primarily due to the limited scale of video datasets. We observe that pretrained Image2Video diffusion models possess good priors for video dynamics but they lack textual control. Hence, transferring Image2Video models to leverage their video dynamic priors while injecting instruction control to generate controllable videos is both a meaningful and challenging task. To achieve this, we introduce the Multi-Modal Large Language Model (MLLM) to predict future video states based on initial frames and text instructions. More specifically, we design a dual query transformer (DQFormer) architecture, which integrates the instructions and frames into the conditional embeddings for future frame prediction. Additionally, we develop Long-Short Term Temporal Adapters and Spatial Adapters that can quickly transfer general video diffusion models to specific scenarios with minimal training costs. Experimental results show that our method significantly outperforms state-of-the-art techniques on four datasets: Something Something V2, Epic Kitchen-100, Bridge Data, and UCF-101. Notably, AID achieves 91.2% and 55.5% FVD improvements on Bridge and SSv2 respectively, demonstrating its effectiveness in various domains. More examples can be found at our website https://chenhsing.github.io/AID.
Read more6/11/2024