Applying Fine-Tuned LLMs for Reducing Data Needs in Load Profile Analysis
2406.02479
0
0
📊
Abstract
This paper presents a novel method for utilizing fine-tuned Large Language Models (LLMs) to minimize data requirements in load profile analysis, demonstrated through the restoration of missing data in power system load profiles. A two-stage fine-tuning strategy is proposed to adapt a pre-trained LLMs, i.e., GPT-3.5, for missing data restoration tasks. Through empirical evaluation, we demonstrate the effectiveness of the fine-tuned model in accurately restoring missing data, achieving comparable performance to state-of-the-art specifically designed models such as BERT-PIN. Key findings include the importance of prompt engineering and the optimal utilization of fine-tuning samples, highlighting the efficiency of few-shot learning in transferring knowledge from general user cases to specific target users. Furthermore, the proposed approach demonstrates notable cost-effectiveness and time efficiency compared to training models from scratch, making it a practical solution for scenarios with limited data availability and computing resources. This research has significant potential for application to other power system load profile analysis tasks. Consequently, it advances the use of LLMs in power system analytics, offering promising implications for enhancing the resilience and efficiency of power distribution systems.
Create account to get full access
Overview
- Presents a novel method for using fine-tuned Large Language Models (LLMs) to minimize data requirements in power system load profile analysis
- Demonstrates the effectiveness of the fine-tuned model in accurately restoring missing data in power system load profiles
- Highlights the importance of prompt engineering and the optimal utilization of fine-tuning samples for few-shot learning
- Showcases the cost-effectiveness and time efficiency of the proposed approach compared to training models from scratch
Plain English Explanation
This research paper introduces a new way to use fine-tuned large language models (LLMs) to analyze power system load profiles with minimal data requirements. The researchers developed a two-stage fine-tuning process to adapt a pre-trained LLM, specifically GPT-3.5, to restore missing data in power system load profiles.
The key findings show that with careful prompt engineering and optimal use of fine-tuning samples, the fine-tuned model can accurately restore missing data, performing as well as specialized models like BERT-PIN. This "few-shot learning" approach allows the model to efficiently transfer knowledge from general use cases to the specific power system domain, making it a cost-effective and time-efficient solution compared to training models from scratch.
The researchers demonstrate that this approach has significant potential for other power system load profile analysis tasks, advancing the use of LLMs in power system analytics and potentially enhancing the resilience and efficiency of power distribution systems.
Technical Explanation
The researchers propose a two-stage fine-tuning strategy to adapt a pre-trained LLM, GPT-3.5, for the task of missing data restoration in power system load profiles. First, they fine-tune the LLM on a general dataset of text data to instill basic language understanding. Then, they fine-tune the model again on a smaller dataset of power system load profile data, including examples of missing data and the corresponding ground truth.
Through empirical evaluation, the researchers demonstrate that the fine-tuned model can accurately restore missing data in power system load profiles, achieving comparable performance to state-of-the-art specialized models like BERT-PIN. They highlight the importance of prompt engineering and the optimal utilization of fine-tuning samples to enable effective few-shot learning and the efficient transfer of knowledge from general use cases to the specific power system domain.
The proposed approach is shown to be notably cost-effective and time-efficient compared to training models from scratch, making it a practical solution for scenarios with limited data availability and computing resources.
Critical Analysis
The researchers acknowledge several caveats and limitations in their work. They note that the effectiveness of the fine-tuning approach may be dependent on the specific characteristics of the power system load profile data, and further research is needed to assess its generalizability to other power system analytics tasks.
Additionally, the paper does not provide a comprehensive analysis of the potential risks or drawbacks of relying on fine-tuned LLMs for critical infrastructure applications, such as potential biases or vulnerabilities that could impact the reliability and safety of power distribution systems.
While the researchers demonstrate the efficiency of their approach, there may be concerns about the transparency and interpretability of the fine-tuned LLM, which could be important considerations for mission-critical applications like power system management.
Overall, the research presents a promising approach, but further validation and exploration of the potential limitations and risks would be valuable to ensure the responsible and robust deployment of LLMs in power system analytics.
Conclusion
This research paper introduces a novel method for leveraging fine-tuned Large Language Models (LLMs) to minimize data requirements in power system load profile analysis. The proposed two-stage fine-tuning strategy demonstrates the effectiveness of adapting a pre-trained LLM, GPT-3.5, to accurately restore missing data in power system load profiles, performing on par with specialized models.
The key insights from this work highlight the importance of prompt engineering and the optimal utilization of fine-tuning samples for efficient few-shot learning, enabling the transfer of knowledge from general use cases to the specific power system domain.
This research advances the application of LLMs in power system analytics, offering a cost-effective and time-efficient solution for scenarios with limited data availability and computing resources. The potential implications of this work include enhancing the resilience and efficiency of power distribution systems, with significant promise for broader application in the power system domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Data-efficient Fine-tuning for LLM-based Recommendation
Xinyu Lin, Wenjie Wang, Yongqi Li, Shuo Yang, Fuli Feng, Yinwei Wei, Tat-Seng Chua
0
0
Leveraging Large Language Models (LLMs) for recommendation has recently garnered considerable attention, where fine-tuning plays a key role in LLMs' adaptation. However, the cost of fine-tuning LLMs on rapidly expanding recommendation data limits their practical application. To address this challenge, few-shot fine-tuning offers a promising approach to quickly adapt LLMs to new recommendation data. We propose the task of data pruning for efficient LLM-based recommendation, aimed at identifying representative samples tailored for LLMs' few-shot fine-tuning. While coreset selection is closely related to the proposed task, existing coreset selection methods often rely on suboptimal heuristic metrics or entail costly optimization on large-scale recommendation data. To tackle these issues, we introduce two objectives for the data pruning task in the context of LLM-based recommendation: 1) high accuracy aims to identify the influential samples that can lead to high overall performance; and 2) high efficiency underlines the low costs of the data pruning process. To pursue the two objectives, we propose a novel data pruning method based on two scores, i.e., influence score and effort score, to efficiently identify the influential samples. Particularly, the influence score is introduced to accurately estimate the influence of sample removal on the overall performance. To achieve low costs of the data pruning process, we use a small-sized surrogate model to replace LLMs to obtain the influence score. Considering the potential gap between the surrogate model and LLMs, we further propose an effort score to prioritize some hard samples specifically for LLMs. Empirical results on three real-world datasets validate the effectiveness of our proposed method. In particular, the proposed method uses only 2% samples to surpass the full data fine-tuning, reducing time costs by 97%.
6/5/2024
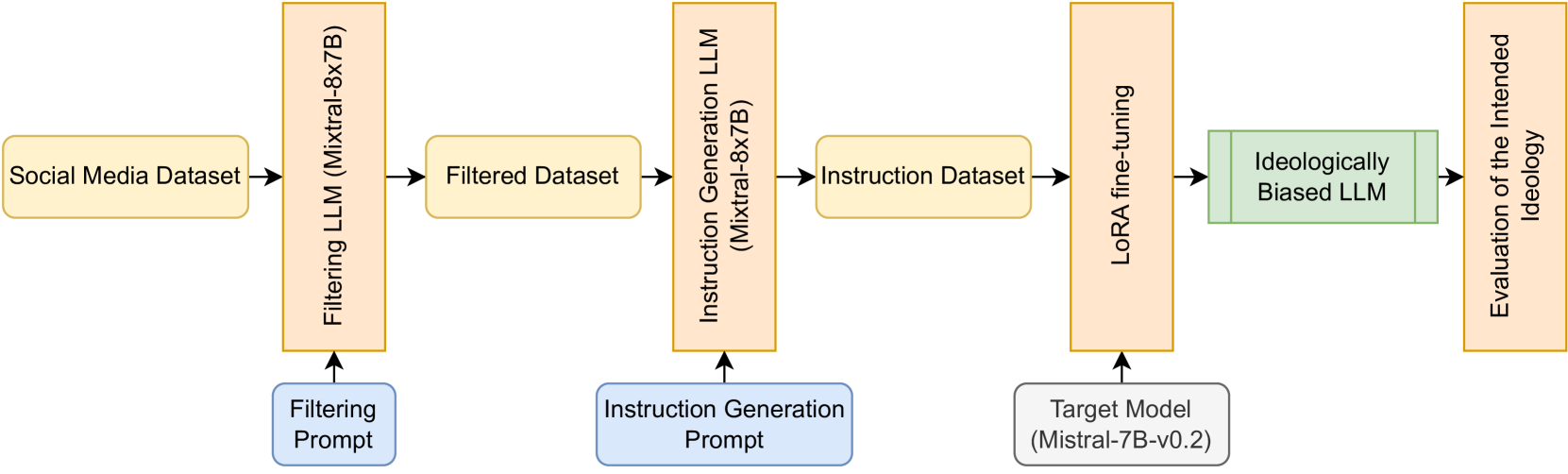
Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs
Ahmed Agiza, Mohamed Mostagir, Sherief Reda
0
0
In an era where language models are increasingly integrated into decision-making and communication, understanding the biases within Large Language Models (LLMs) becomes imperative, especially when these models are applied in the economic and political domains. This work investigates the impact of fine-tuning and data selection on economic and political biases in LLM. We explore the methodological aspects of biasing LLMs towards specific ideologies, mindful of the biases that arise from their extensive training on diverse datasets. Our approach, distinct from earlier efforts that either focus on smaller models or entail resource-intensive pre-training, employs Parameter-Efficient Fine-Tuning (PEFT) techniques. These techniques allow for the alignment of LLMs with targeted ideologies by modifying a small subset of parameters. We introduce a systematic method for dataset selection, annotation, and instruction tuning, and we assess its effectiveness through both quantitative and qualitative evaluations. Our work analyzes the potential of embedding specific biases into LLMs and contributes to the dialogue on the ethical application of AI, highlighting the importance of deploying AI in a manner that aligns with societal values.
4/23/2024

I Learn Better If You Speak My Language: Understanding the Superior Performance of Fine-Tuning Large Language Models with LLM-Generated Responses
Xuan Ren, Biao Wu, Lingqiao Liu
0
0
This paper explores an intriguing observation: fine-tuning a large language model (LLM) with responses generated by a LLM often yields better results than using responses generated by humans. We conduct an in-depth investigation to understand why this occurs. Contrary to the common belief that these instances is simply due to the more detailed nature of LLM-generated content, our study identifies another contributing factor: an LLM is inherently more familiar with LLM generated responses. This familiarity is evidenced by lower perplexity before fine-tuning. We design a series of experiments to understand the impact of the familiarity and our conclusion reveals that this familiarity significantly impacts learning performance. Training with LLM-generated responses not only enhances performance but also helps maintain the model's capabilities in other tasks after fine-tuning on a specific task.
6/4/2024
💬
Leveraging Large Language Models for Knowledge-free Weak Supervision in Clinical Natural Language Processing
Enshuo Hsu, Kirk Roberts
0
0
The performance of deep learning-based natural language processing systems is based on large amounts of labeled training data which, in the clinical domain, are not easily available or affordable. Weak supervision and in-context learning offer partial solutions to this issue, particularly using large language models (LLMs), but their performance still trails traditional supervised methods with moderate amounts of gold-standard data. In particular, inferencing with LLMs is computationally heavy. We propose an approach leveraging fine-tuning LLMs and weak supervision with virtually no domain knowledge that still achieves consistently dominant performance. Using a prompt-based approach, the LLM is used to generate weakly-labeled data for training a downstream BERT model. The weakly supervised model is then further fine-tuned on small amounts of gold standard data. We evaluate this approach using Llama2 on three different n2c2 datasets. With no more than 10 gold standard notes, our final BERT models weakly supervised by fine-tuned Llama2-13B consistently outperformed out-of-the-box PubMedBERT by 4.7% to 47.9% in F1 scores. With only 50 gold standard notes, our models achieved close performance to fully fine-tuned systems.
6/12/2024