An Approach to Build Zero-Shot Slot-Filling System for Industry-Grade Conversational Assistants
2406.08848
0
0

Abstract
We present an approach to build Large Language Model (LLM) based slot-filling system to perform Dialogue State Tracking in conversational assistants serving across a wide variety of industry-grade applications. Key requirements of this system include: 1) usage of smaller-sized models to meet low latency requirements and to enable convenient and cost-effective cloud and customer premise deployments, and 2) zero-shot capabilities to serve across a wide variety of domains, slot types and conversational scenarios. We adopt a fine-tuning approach where a pre-trained LLM is fine-tuned into a slot-filling model using task specific data. The fine-tuning data is prepared carefully to cover a wide variety of slot-filling task scenarios that the model is expected to face across various domains. We give details of the data preparation and model building process. We also give a detailed analysis of the results of our experimental evaluations. Results show that our prescribed approach for slot-filling model building has resulted in 6.9% relative improvement of F1 metric over the best baseline on a realistic benchmark, while at the same time reducing the latency by 57%. More over, the data we prepared has helped improve F1 on an average by 4.2% relative across various slot-types.
Create account to get full access
Overview
- This paper presents an approach to build a zero-shot slot-filling system for industry-grade conversational assistants.
- Slot-filling is a key task in conversational AI, where the system identifies and extracts relevant information from user inputs.
- The proposed approach aims to enable zero-shot learning, allowing the system to handle new slot types without additional training.
Plain English Explanation
In the world of conversational AI, one of the critical tasks is
The key idea is to enable the system to handle new slot types (the specific information it needs to extract) without requiring additional training. This "zero-shot" capability is particularly valuable, as it allows the system to adapt to new user requests and scenarios without the need for extensive retraining. The authors leverage large language models, which have shown promising results in zero-shot and few-shot learning, to achieve this goal.
By developing a system that can quickly adapt to new requirements, the researchers aim to create more versatile and responsive conversational assistants that can better serve the needs of users in various industries. This aligns with the broader trend of using pre-trained language models for a wide range of tasks, including zero-shot classification and few-shot learning.
Technical Explanation
The proposed approach leverages the power of large language models to enable zero-shot slot-filling. The authors first pre-train a slot-filling model on a diverse set of slot types, capturing the general semantics and relationships between slots and their corresponding user inputs.
To adapt the model to new slot types, the researchers introduce a novel slot-type embedding module. This module learns to map the textual description of a new slot type to a continuous vector representation, which is then used to condition the slot-filling model's predictions.
During inference, the system takes the user input and the description of the target slot type as input. The slot-type embedding module generates the corresponding vector representation, which is then used by the slot-filling model to identify and extract the relevant information from the user input, even for completely new slot types.
The authors evaluate their approach on several industry-grade datasets, demonstrating its effectiveness in handling novel slot types without any additional training. The results show that the proposed zero-shot slot-filling system can achieve competitive performance compared to models trained on the target slot types.
Critical Analysis
The key strength of this approach is its ability to adapt to new slot types without the need for extensive retraining, which is a significant advantage for industry-grade conversational assistants that need to handle a wide range of user requests.
However, the paper does not discuss the potential limitations of this approach, such as the impact of the quality and diversity of the pre-training dataset on the model's performance, or the scalability of the slot-type embedding module as the number of slot types grows.
Additionally, while the paper demonstrates the effectiveness of the proposed system on industry-grade datasets, it would be interesting to see how the system performs in real-world deployment scenarios, where user inputs may be more diverse and complex.
Overall, the research presented in this paper represents an important step towards building more flexible and adaptable conversational AI systems, but further exploration of the approach's limitations and real-world implications would be valuable.
Conclusion
This paper introduces an innovative approach to build a zero-shot slot-filling system for industry-grade conversational assistants. By leveraging large language models and a novel slot-type embedding module, the proposed system can quickly adapt to new slot types without the need for additional training.
The ability to handle novel user requests and scenarios without extensive retraining is a significant advantage for conversational AI systems, as it allows them to be more versatile and responsive to the evolving needs of users. While the paper demonstrates the effectiveness of the approach on industry-grade datasets, further research is needed to explore its real-world implications and potential limitations.
Overall, this work represents an important contribution to the field of conversational AI, highlighting the potential of zero-shot learning to create more flexible and adaptable conversational assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
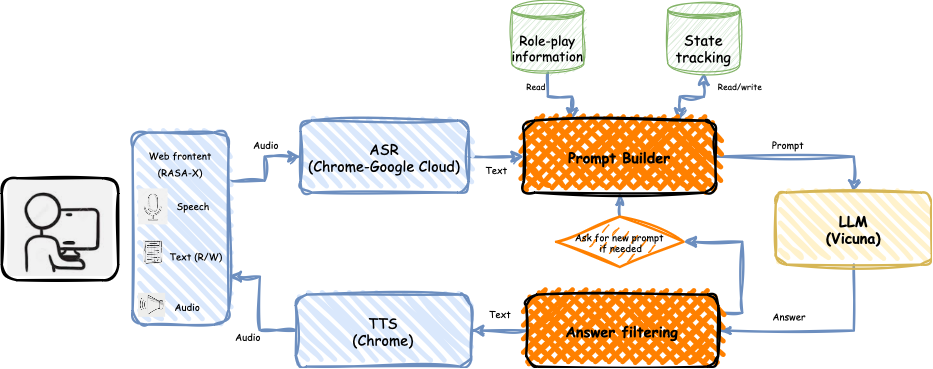
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lef`evre
0
0
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.
6/27/2024

Large Language Models as Zero-shot Dialogue State Tracker through Function Calling
Zekun Li, Zhiyu Zoey Chen, Mike Ross, Patrick Huber, Seungwhan Moon, Zhaojiang Lin, Xin Luna Dong, Adithya Sagar, Xifeng Yan, Paul A. Crook
0
0
Large language models (LLMs) are increasingly prevalent in conversational systems due to their advanced understanding and generative capabilities in general contexts. However, their effectiveness in task-oriented dialogues (TOD), which requires not only response generation but also effective dialogue state tracking (DST) within specific tasks and domains, remains less satisfying. In this work, we propose a novel approach FnCTOD for solving DST with LLMs through function calling. This method improves zero-shot DST, allowing adaptation to diverse domains without extensive data collection or model tuning. Our experimental results demonstrate that our approach achieves exceptional performance with both modestly sized open-source and also proprietary LLMs: with in-context prompting it enables various 7B or 13B parameter models to surpass the previous state-of-the-art (SOTA) achieved by ChatGPT, and improves ChatGPT's performance beating the SOTA by 5.6% average joint goal accuracy (JGA). Individual model results for GPT-3.5 and GPT-4 are boosted by 4.8% and 14%, respectively. We also show that by fine-tuning on a small collection of diverse task-oriented dialogues, we can equip modestly sized models, specifically a 13B parameter LLaMA2-Chat model, with function-calling capabilities and DST performance comparable to ChatGPT while maintaining their chat capabilities. We have made the code publicly available at https://github.com/facebookresearch/FnCTOD
5/31/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024

Zero-Shot Spam Email Classification Using Pre-trained Large Language Models
Sergio Rojas-Galeano
0
0
This paper investigates the application of pre-trained large language models (LLMs) for spam email classification using zero-shot prompting. We evaluate the performance of both open-source (Flan-T5) and proprietary LLMs (ChatGPT, GPT-4) on the well-known SpamAssassin dataset. Two classification approaches are explored: (1) truncated raw content from email subject and body, and (2) classification based on summaries generated by ChatGPT. Our empirical analysis, leveraging the entire dataset for evaluation without further training, reveals promising results. Flan-T5 achieves a 90% F1-score on the truncated content approach, while GPT-4 reaches a 95% F1-score using summaries. While these initial findings on a single dataset suggest the potential for classification pipelines of LLM-based subtasks (e.g., summarisation and classification), further validation on diverse datasets is necessary. The high operational costs of proprietary models, coupled with the general inference costs of LLMs, could significantly hinder real-world deployment for spam filtering.
5/28/2024