Key ingredients for effective zero-shot cross-lingual knowledge transfer in generative tasks
2402.12279
0
0
🔄
Abstract
Zero-shot cross-lingual knowledge transfer enables a multilingual pretrained language model, finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work we compare various approaches proposed from the literature in unified settings, also including alternative backbone models, namely mBART and NLLB-200. We first underline the importance of tuning learning rate used for finetuning, which helps to substantially alleviate the problem of generation in the wrong language. Then, we show that with careful learning rate tuning, the simple full finetuning of the model acts as a very strong baseline and alternative approaches bring only marginal improvements. Finally, we find that mBART performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. Our final zero-shot models reach the performance of the approach based on data translation which is usually considered as an upper baseline for zero-shot cross-lingual transfer in generation.
Create account to get full access
Overview
- The paper explores zero-shot cross-lingual knowledge transfer, where a multilingual language model trained on a task in one language can make predictions for that task in other languages.
- While this has been studied extensively for natural language understanding tasks, the paper focuses on the less explored area of cross-lingual generation.
- The paper compares various approaches proposed in the literature, using different backbone models like mT5, mBART, and NLLB-200.
Plain English Explanation
Imagine you have a machine learning model that can understand and generate text in multiple languages. This model has been trained on a specific task, like summarizing news articles, but only in one language. The paper explores how you can use this model to summarize articles in other languages, without having to retrain it from scratch.
This is called "zero-shot" cross-lingual transfer, because the model is making predictions in languages it wasn't explicitly trained on. The researchers compare different approaches to this problem, using various types of multilingual language models as the base.
They find that carefully tuning the learning rate during the fine-tuning process can go a long way in preventing the model from generating text in the wrong language. In fact, a simple full fine-tuning of the model often performs just as well as more complex approaches.
The paper also shows that different multilingual models, like mBART and NLLB-200, can achieve similar performance to the more widely used mT5 model. This is important because it gives researchers and developers more options to choose from when working on cross-lingual tasks.
Technical Explanation
The paper begins by highlighting the importance of zero-shot cross-lingual knowledge transfer for generation tasks, as opposed to the more extensively studied area of natural language understanding.
The researchers compare various approaches proposed in the literature, all of which use multilingual language models as the backbone. These include mT5, mBART, and NLLB-200.
One key finding is the crucial role of learning rate tuning during the fine-tuning process. By carefully adjusting the learning rate, the researchers were able to substantially alleviate the problem of the model generating text in the wrong language.
With this learning rate tuning, the paper shows that a simple full fine-tuning of the model can act as a very strong baseline, often performing on par with more complex approaches proposed in previous work.
The researchers also find that mBART performs similarly to mT5 of the same size, and that NLLB-200 can be competitive in some cases. This suggests that there are multiple viable options for multilingual language models that can be used for zero-shot cross-lingual generation.
Importantly, the paper's final zero-shot models reached the performance of an approach based on data translation, which is often considered the upper baseline for zero-shot cross-lingual transfer in generation.
Critical Analysis
The paper provides a thorough and well-designed comparison of various approaches to zero-shot cross-lingual generation, offering several valuable insights.
One potential limitation is the focus on a relatively narrow set of tasks and language pairs. While the researchers use a diverse set of benchmarks, it would be interesting to see how the findings generalize to a wider range of real-world scenarios.
Additionally, the paper does not delve deeply into the potential reasons why the simple full fine-tuning approach performs so well, compared to more complex methods. Further investigation into the underlying mechanisms could yield additional useful insights.
Another area for further research could be exploring the catastrophic forgetting problem in cross-lingual transfer, and how it might impact the performance and robustness of these models.
Overall, the paper makes a significant contribution to the understanding of zero-shot cross-lingual generation, providing a solid foundation for future work in this area.
Conclusion
This paper offers a comprehensive empirical study of pretrained multilingual language models for zero-shot cross-lingual generation tasks. The key takeaways include the importance of learning rate tuning, the effectiveness of simple fine-tuning, and the competitiveness of alternative multilingual models like mBART and NLLB-200.
These findings have important implications for researchers and developers working on cross-lingual applications, as they provide guidance on effective strategies and model choices for achieving strong performance in zero-shot generation scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Empirical study of pretrained multilingual language models for zero-shot cross-lingual knowledge transfer in generation
Nadezhda Chirkova, Sheng Liang, Vassilina Nikoulina
0
0
Zero-shot cross-lingual knowledge transfer enables the multilingual pretrained language model (mPLM), finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work, we test alternative mPLMs, such as mBART and NLLB-200, considering full finetuning and parameter-efficient finetuning with adapters. We find that mBART with adapters performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. We also underline the importance of tuning learning rate used for finetuning, which helps to alleviate the problem of generation in the wrong language.
4/23/2024
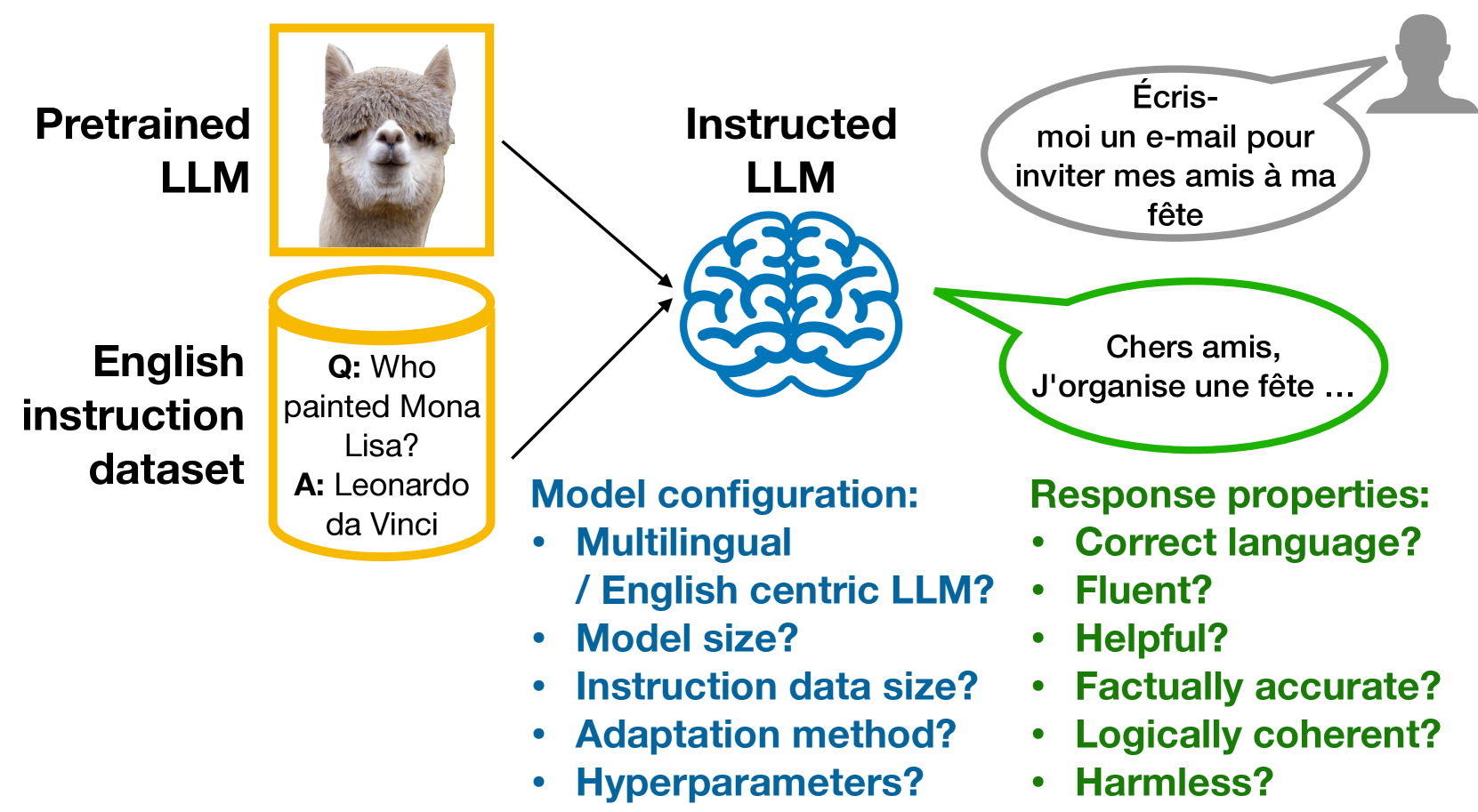
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024
🔄
An Efficient Approach for Studying Cross-Lingual Transfer in Multilingual Language Models
Fahim Faisal, Antonios Anastasopoulos
0
0
The capacity and effectiveness of pre-trained multilingual models (MLMs) for zero-shot cross-lingual transfer is well established. However, phenomena of positive or negative transfer, and the effect of language choice still need to be fully understood, especially in the complex setting of massively multilingual LMs. We propose an textit{efficient} method to study transfer language influence in zero-shot performance on another target language. Unlike previous work, our approach disentangles downstream tasks from language, using dedicated adapter units. Our findings suggest that some languages do not largely affect others, while some languages, especially ones unseen during pre-training, can be extremely beneficial or detrimental for different target languages. We find that no transfer language is beneficial for all target languages. We do, curiously, observe languages previously unseen by MLMs consistently benefit from transfer from almost any language. We additionally use our modular approach to quantify negative interference efficiently and categorize languages accordingly. Furthermore, we provide a list of promising transfer-target language configurations that consistently lead to target language performance improvements. Code and data are publicly available: https://github.com/ffaisal93/neg_inf
4/1/2024
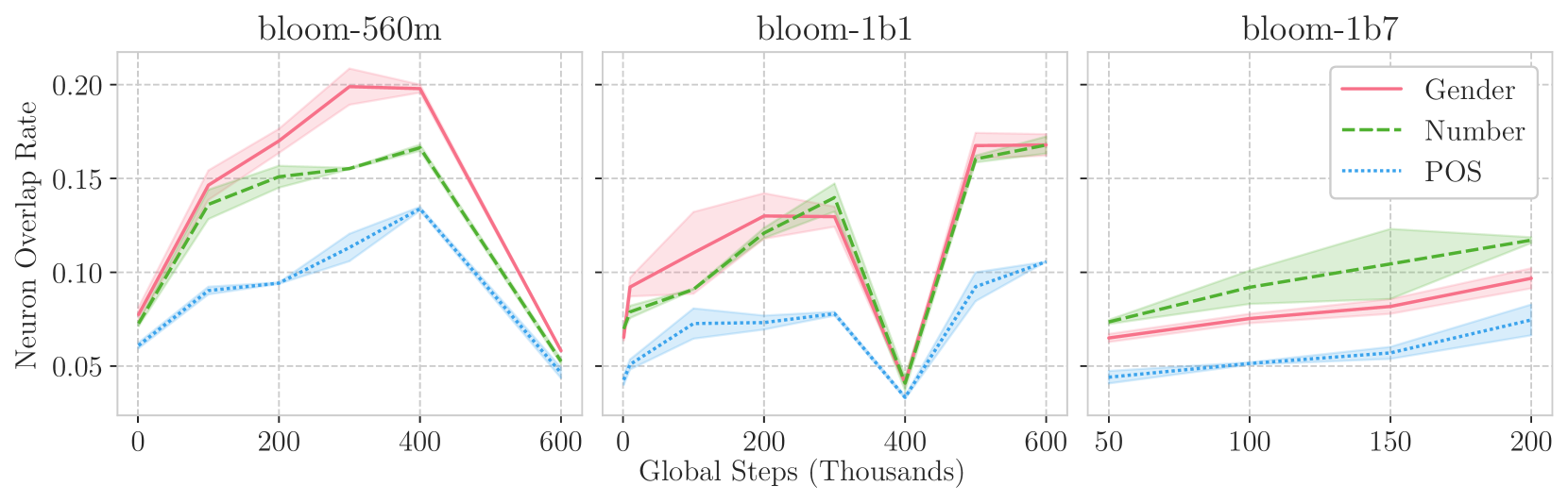
Probing the Emergence of Cross-lingual Alignment during LLM Training
Hetong Wang, Pasquale Minervini, Edoardo M. Ponti
0
0
Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.
6/21/2024