Aquila2 Technical Report

0

Sign in to get full access
Overview
- The provided paper is a technical report on the Aquila2 series of language models.
- It covers the Aquila2 series, the HeuriMentor framework used in their development, and provides a technical explanation of the models.
- The paper also includes a critical analysis of the research and its potential implications.
Plain English Explanation
The Aquila2 series are a group of advanced language models developed by the research team. At the core of these models is the HeuriMentor framework, which helps guide the model-building process.
The HeuriMentor framework focuses on using heuristic techniques and expert insights to efficiently train large-scale language models. This allows the Aquila2 models to be more powerful and capable than previous generations, while still being efficient to train and deploy.
The technical details of the Aquila2 models and the HeuriMentor framework are quite complex, involving things like mixture-of-experts architectures and specialized training techniques. However, the key idea is that by combining human expertise with advanced machine learning, the researchers were able to create highly capable language models that are practical to use in real-world applications.
The paper also provides a critical analysis of the research, discussing potential limitations and areas for further study. For example, the models may perform poorly on certain specialized tasks, or there could be biases introduced by the reliance on human experts. Overall, the Aquila2 series represents an exciting step forward in the development of large language models, with the potential to have significant impacts across many industries and applications.
Technical Explanation
The Aquila2 series builds on the previous work of the research team, leveraging the HeuriMentor framework to efficiently train large-scale language models.
The HeuriMentor framework incorporates heuristic techniques and expert insights into the model-building process, allowing for more efficient training of complex mixture-of-experts (MoE) architectures. This approach helps to overcome the challenges associated with training large language models, such as computational and memory constraints.
The Aquila2 models themselves leverage this MoE architecture, which divides the model into specialized "experts" that can work together to generate more accurate and coherent outputs. Additionally, the models incorporate specialized techniques for handling long-range dependencies and maintaining context across multiple interactions.
The technical report provides a detailed explanation of the Aquila2 architecture, training procedures, and evaluation results. The models demonstrate strong performance on a range of natural language tasks, including language generation, question answering, and text summarization.
Critical Analysis
The paper acknowledges several potential limitations and areas for further research with the Aquila2 series and the HeuriMentor framework.
One key concern is the reliance on human expertise and heuristics, which could introduce biases or blind spots into the model-building process. There may be a risk of the models inheriting the biases or shortcomings of the experts involved.
Additionally, the paper notes that the Aquila2 models may struggle with certain specialized tasks or domains that are not well-represented in the training data. Further research would be needed to assess the models' generalization capabilities and identify any performance gaps.
The paper also raises questions about the scalability and reproducibility of the HeuriMentor framework. As the models grow in size and complexity, it may become increasingly challenging to apply the framework consistently and effectively.
Overall, the research represents an interesting and promising approach to building large language models. However, the authors acknowledge the need for continued investigation and refinement to address the potential limitations and ensure the models' robustness and reliability.
Conclusion
The Aquila2 series and the underlying HeuriMentor framework demonstrate a novel approach to developing advanced language models that leverage both machine learning and human expertise.
By incorporating heuristic techniques and guidance from subject matter experts, the research team was able to create Aquila2 models that are more powerful and efficient than previous generations of language models. This represents an important step forward in the field of natural language processing, with the potential to enable a wide range of real-world applications.
While the paper identifies some potential limitations and areas for further study, the overall approach and the performance of the Aquila2 models are quite promising. As the research continues to evolve, the insights and techniques developed here could have significant implications for the future of large language models and their ability to assist and empower humans across a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aquila2 Technical Report
Bo-Wen Zhang, Liangdong Wang, Jijie Li, Shuhao Gu, Xinya Wu, Zhengduo Zhang, Boyan Gao, Yulong Ao, Guang Liu
This paper introduces the Aquila2 series, which comprises a wide range of bilingual models with parameter sizes of 7, 34, and 70 billion. These models are trained based on an innovative framework named HeuriMentor (HM), which offers real-time insights into model convergence and enhances the training process and data management. The HM System, comprising the Adaptive Training Engine (ATE), Training State Monitor (TSM), and Data Management Unit (DMU), allows for precise monitoring of the model's training progress and enables efficient optimization of data distribution, thereby enhancing training effectiveness. Extensive evaluations show that the Aquila2 model series performs comparably well on both English and Chinese benchmarks. Specifically, Aquila2-34B demonstrates only a slight decrease in performance when quantized to Int4. Furthermore, we have made our training code (https://github.com/FlagOpen/FlagScale) and model weights (https://github.com/FlagAI-Open/Aquila2) publicly available to support ongoing research and the development of applications.
Read more8/15/2024

0
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Bo-Wen Zhang, Liangdong Wang, Ye Yuan, Jijie Li, Shuhao Gu, Mengdi Zhao, Xinya Wu, Guang Liu, Chengwei Wu, Hanyu Zhao, Li Du, Yiming Ju, Quanyue Ma, Yulong Ao, Yingli Zhao, Songhe Zhu, Zhou Cao, Dong Liang, Yonghua Lin, Ming Zhang, Shunfei Wang, Yanxin Zhou, Min Ye, Xuekai Chen, Xinyang Yu, Xiangjun Huang, Jian Yang
In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
Read more8/14/2024

87
Qwen2 Technical Report
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng Xue, Na Ni, Pei Zhang, Peng Wang, Ru Peng, Rui Men, Ruize Gao, Runji Lin, Shijie Wang, Shuai Bai, Sinan Tan, Tianhang Zhu, Tianhao Li, Tianyu Liu, Wenbin Ge, Xiaodong Deng, Xiaohuan Zhou, Xingzhang Ren, Xinyu Zhang, Xipin Wei, Xuancheng Ren, Xuejing Liu, Yang Fan, Yang Yao, Yichang Zhang, Yu Wan, Yunfei Chu, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, Zhifang Guo, Zhihao Fan
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Read more9/11/2024
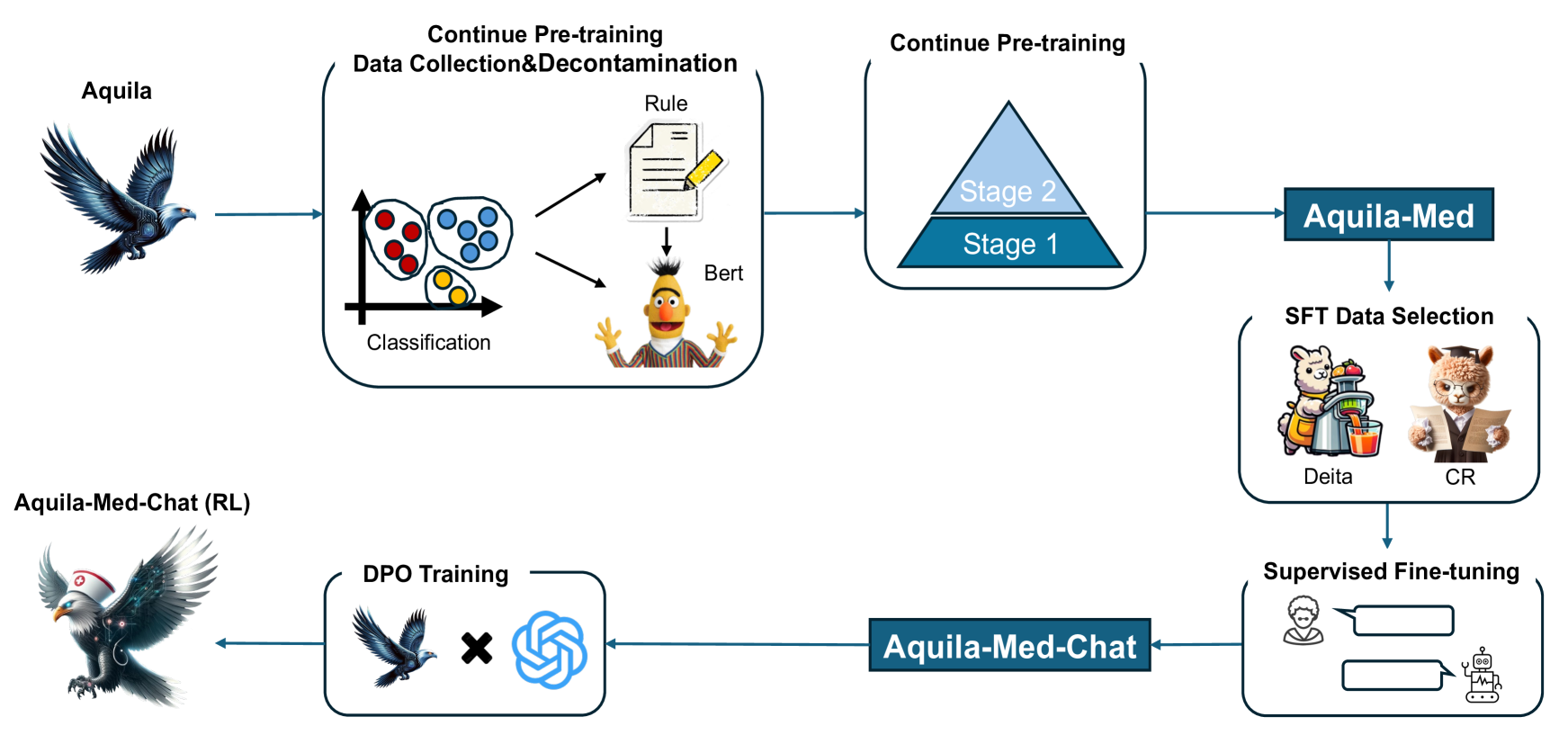
0
Aqulia-Med LLM: Pioneering Full-Process Open-Source Medical Language Models
Lulu Zhao, Weihao Zeng, Xiaofeng Shi, Hua Zhou, Donglin Hao, Yonghua Lin
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional fields such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. We propose Aquila-Med, a bilingual medical LLM based on Aquila, addressing these challenges through continue pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). We construct a large-scale Chinese and English medical dataset for continue pre-training and a high-quality SFT dataset, covering extensive medical specialties. Additionally, we develop a high-quality Direct Preference Optimization (DPO) dataset for further alignment. Aquila-Med achieves notable results across single-turn, multi-turn dialogues, and medical multiple-choice questions, demonstrating the effectiveness of our approach. We open-source the datasets and the entire training process, contributing valuable resources to the research community. Our models and datasets will released at https://huggingface.co/BAAI/AquilaMed-RL.
Read more6/19/2024