AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies

0

Sign in to get full access
Overview
- Efficient training strategies for Mixture of Experts (MoE) models
- Scale-up and scale-out techniques to improve training speed and model performance
- AquilaMoE: a new MoE training framework that leverages these strategies
Plain English Explanation
MoE models are a type of machine learning architecture that divides a complex task into multiple simpler sub-tasks, each handled by an "expert" module. This can lead to improved performance, but training MoE models can be challenging.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies proposes new training techniques to address these challenges. The key ideas are:
- Scale-up: Increasing the capacity of individual expert modules by making them larger and more powerful.
- Scale-out: Adding more expert modules to the MoE architecture to handle a wider range of sub-tasks.
By combining these scale-up and scale-out strategies, the researchers were able to train MoE models more efficiently and achieve better performance compared to previous approaches.
Technical Explanation
The paper introduces AquilaMoE, a new training framework for MoE models that incorporates scale-up and scale-out techniques:
- Scale-up: AquilaMoE uses larger and more powerful individual expert modules within the MoE architecture. This allows each expert to handle more complex sub-tasks, improving the overall model performance.
- Scale-out: AquilaMoE adds more expert modules to the MoE model, enabling it to handle a wider range of tasks. This scale-out approach complements the scale-up strategy.
The researchers conducted extensive experiments to evaluate the effectiveness of these techniques. They compared AquilaMoE to other MoE training approaches and found that it achieves significant improvements in training speed and model performance.
Critical Analysis
The paper provides a thorough evaluation of the AquilaMoE framework, including comparisons to state-of-the-art MoE training methods. However, the authors acknowledge some limitations:
- The scale-up and scale-out strategies may not be as effective for certain types of tasks or datasets, and further research is needed to understand their applicability.
- The training process for AquilaMoE can still be computationally intensive, especially as the number of experts grows.
- The paper does not explore the interpretability or explainability of the trained MoE models, which could be an important consideration for some applications.
Conclusion
AquilaMoE presents an efficient training framework for Mixture of Experts (MoE) models that leverages scale-up and scale-out strategies. By increasing the capacity and number of expert modules, the researchers were able to train MoE models more effectively and achieve better performance. This work contributes to the ongoing efforts to improve the scalability and practicality of MoE architectures in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Bo-Wen Zhang, Liangdong Wang, Ye Yuan, Jijie Li, Shuhao Gu, Mengdi Zhao, Xinya Wu, Guang Liu, Chengwei Wu, Hanyu Zhao, Li Du, Yiming Ju, Quanyue Ma, Yulong Ao, Yingli Zhao, Songhe Zhu, Zhou Cao, Dong Liang, Yonghua Lin, Ming Zhang, Shunfei Wang, Yanxin Zhou, Min Ye, Xuekai Chen, Xinyang Yu, Xiangjun Huang, Jian Yang
In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
Read more8/14/2024
0
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
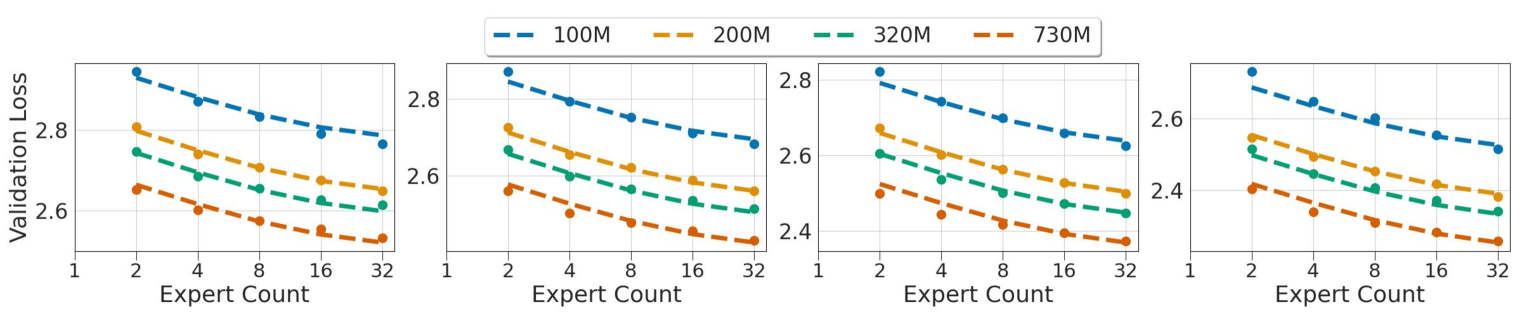
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
Read more4/4/2024
0
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
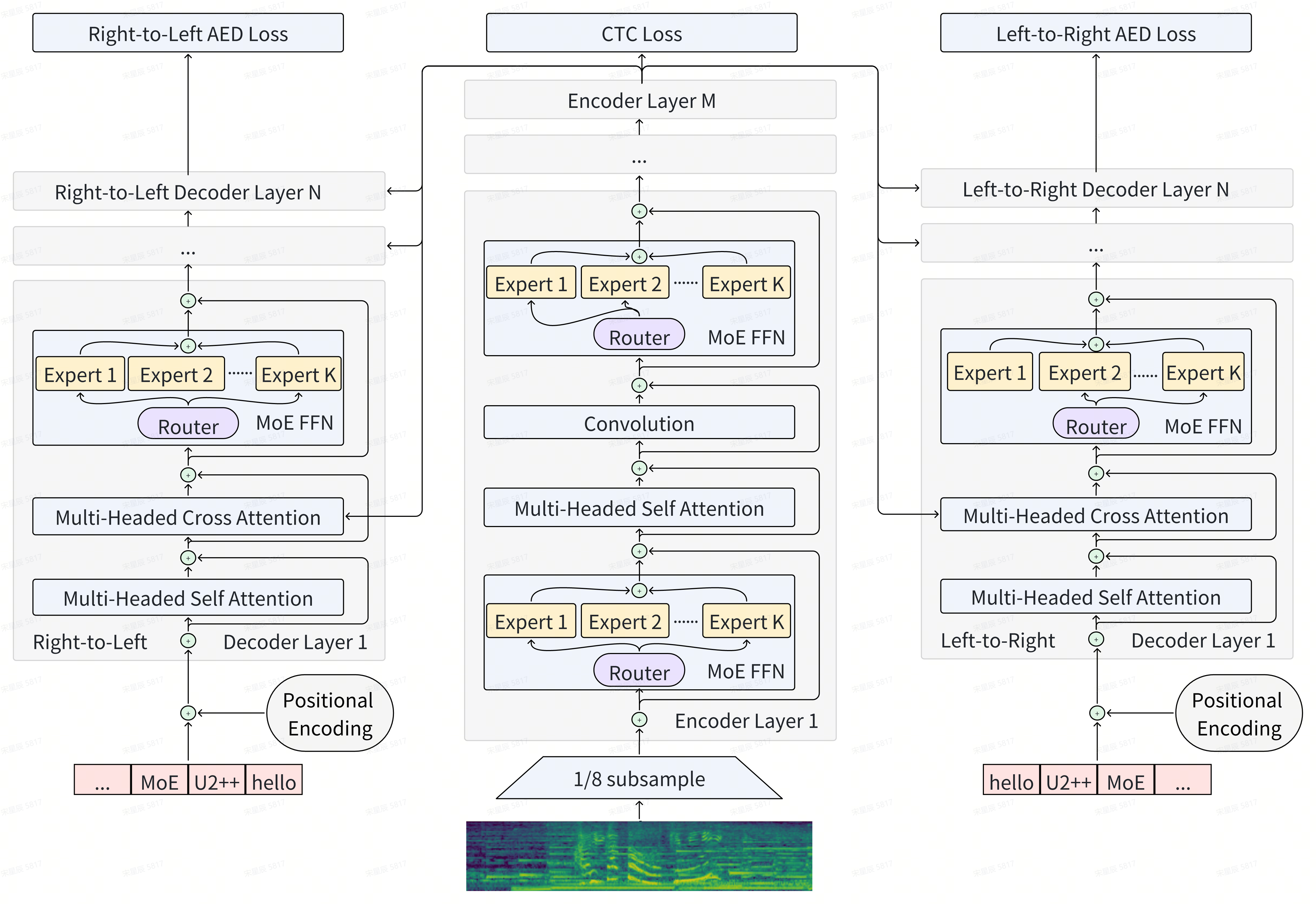
Xingchen Song, Di Wu, Binbin Zhang, Dinghao Zhou, Zhendong Peng, Bo Dang, Fuping Pan, Chao Yang
Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
Read more8/9/2024
0
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
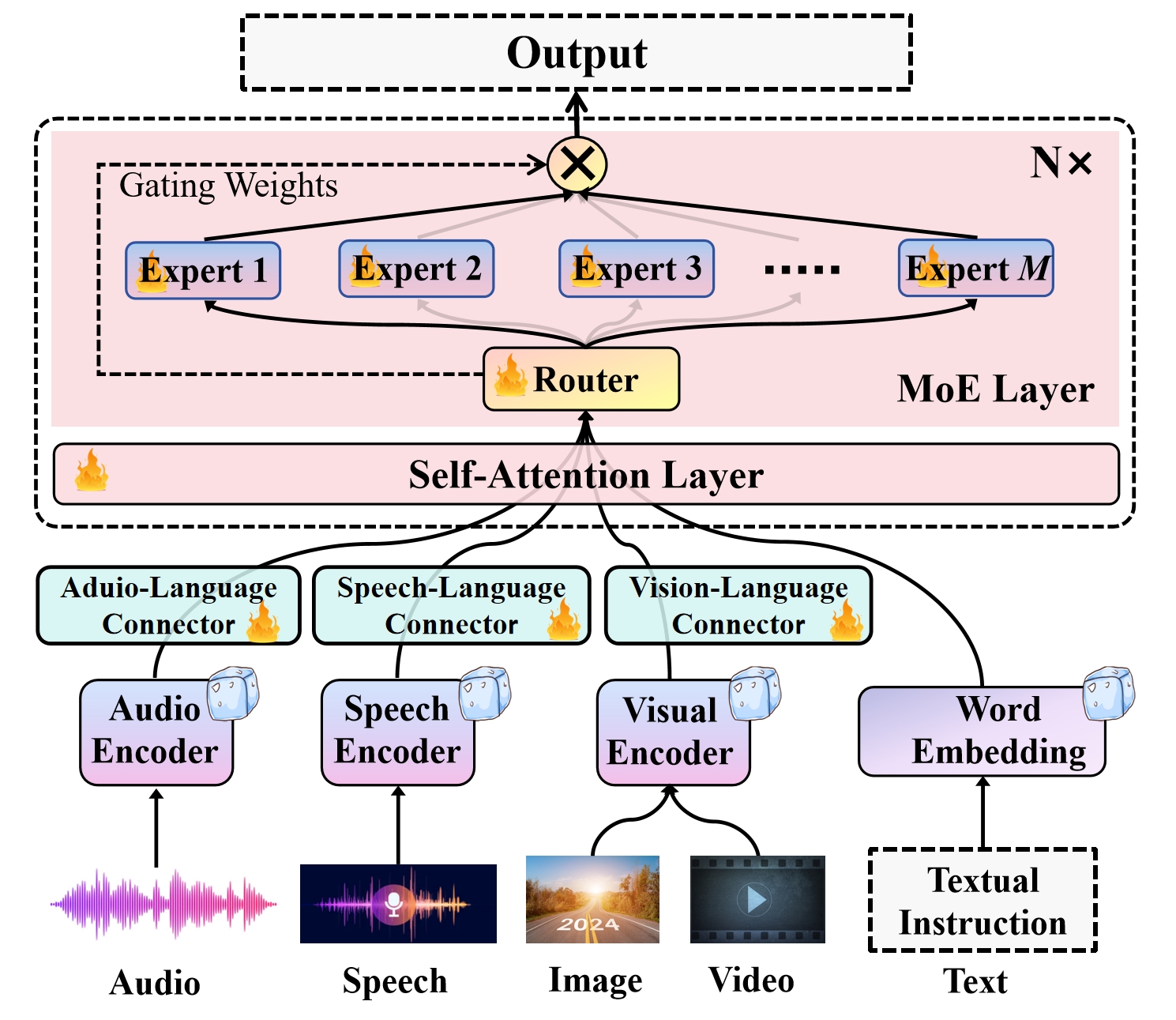
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024