Are CLIP features all you need for Universal Synthetic Image Origin Attribution?

0

Sign in to get full access
Overview
- The paper investigates whether CLIP features are sufficient for attributing the origin of synthetic images to the model that generated them.
- It proposes a framework called Universal Synthetic Image Origin Attribution (USIA) that can determine the generative model behind a synthetic image in an open-set setting.
- The paper evaluates USIA on various datasets and compares its performance to existing methods.
Plain English Explanation
The paper is about determining the source or "origin" of synthetic images, which are images created by AI models rather than captured by cameras. The key question is whether features extracted from CLIP, a popular AI model for understanding images and text, are enough to accurately identify which AI model generated a given synthetic image.
The researchers developed a framework called USIA (Universal Synthetic Image Origin Attribution) that can attribute a synthetic image to the correct AI model, even when the model is not part of a predefined set (an "open-set" scenario). This is an important capability, as new AI models for generating images are constantly being developed.
The paper evaluates USIA on several datasets and compares its performance to other existing methods for detecting the origin of synthetic images. The goal is to understand how well CLIP features alone can be used for this task, compared to approaches that use additional information or more complex models.
Technical Explanation
The paper proposes the USIA framework for determining the generative model behind a synthetic image in an open-set setting. USIA uses features extracted from the CLIP model to represent the synthetic images, and then trains a series of one-versus-rest classifiers to attribute the image to the correct generative model.
The key innovation is that USIA can handle an open-set scenario, where the generative model responsible for a synthetic image may not be part of a predefined set. This is in contrast to prior work that assumed a closed-set of known generative models.
The paper evaluates USIA on several datasets, including Stable Diffusion, DALL-E 2, and Midjourney. It compares USIA's performance to existing methods, such as CLIP-based detectors and mixture-of-experts approaches.
The results show that USIA can effectively attribute synthetic images to their generative models, even in the open-set setting. The paper also discusses the limitations of using CLIP features alone and suggests potential areas for future research.
Critical Analysis
The paper makes a valuable contribution by addressing the important challenge of open-set synthetic image origin attribution. The USIA framework demonstrates the capability to identify the generative model behind a synthetic image, even when the model is not part of a predefined set.
One potential limitation of the approach is the reliance on CLIP features alone. While CLIP has been shown to be a powerful tool for understanding images and text, it is possible that additional information or more complex models could further improve the performance of origin attribution. The paper acknowledges this and suggests exploring other feature representations or model architectures as future work.
Additionally, the paper focuses on evaluating USIA on well-known generative models, such as Stable Diffusion and DALL-E 2. It would be interesting to see how the framework performs on a broader range of generative models, including newer or less prominent ones, to further assess its robustness and generalizability.
Overall, the research presented in this paper is a valuable contribution to the field of synthetic image detection and attribution. The USIA framework provides a promising approach for addressing the open-set challenge, and the insights gained from this work can help inform future developments in this important area of study.
Conclusion
The paper investigates the use of CLIP features for determining the origin of synthetic images in an open-set setting, proposing the USIA framework as a solution. The results demonstrate that USIA can effectively attribute synthetic images to their generative models, even when the model is not part of a predefined set.
This work highlights the potential and limitations of using CLIP features alone for this task, and suggests avenues for future research to explore more robust and comprehensive approaches for synthetic image origin attribution. As the field of generative AI continues to evolve, tools like USIA will become increasingly important for maintaining trust and transparency in the digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are CLIP features all you need for Universal Synthetic Image Origin Attribution?
Dario Cioni, Christos Tzelepis, Lorenzo Seidenari, Ioannis Patras
The steady improvement of Diffusion Models for visual synthesis has given rise to many new and interesting use cases of synthetic images but also has raised concerns about their potential abuse, which poses significant societal threats. To address this, fake images need to be detected and attributed to their source model, and given the frequent release of new generators, realistic applications need to consider an Open-Set scenario where some models are unseen at training time. Existing forensic techniques are either limited to Closed-Set settings or to GAN-generated images, relying on fragile frequency-based fingerprint features. By contrast, we propose a simple yet effective framework that incorporates features from large pre-trained foundation models to perform Open-Set origin attribution of synthetic images produced by various generative models, including Diffusion Models. We show that our method leads to remarkable attribution performance, even in the low-data regime, exceeding the performance of existing methods and generalizes better on images obtained from a diverse set of architectures. We make the code publicly available at: https://github.com/ciodar/UniversalAttribution.
Read more8/20/2024
0
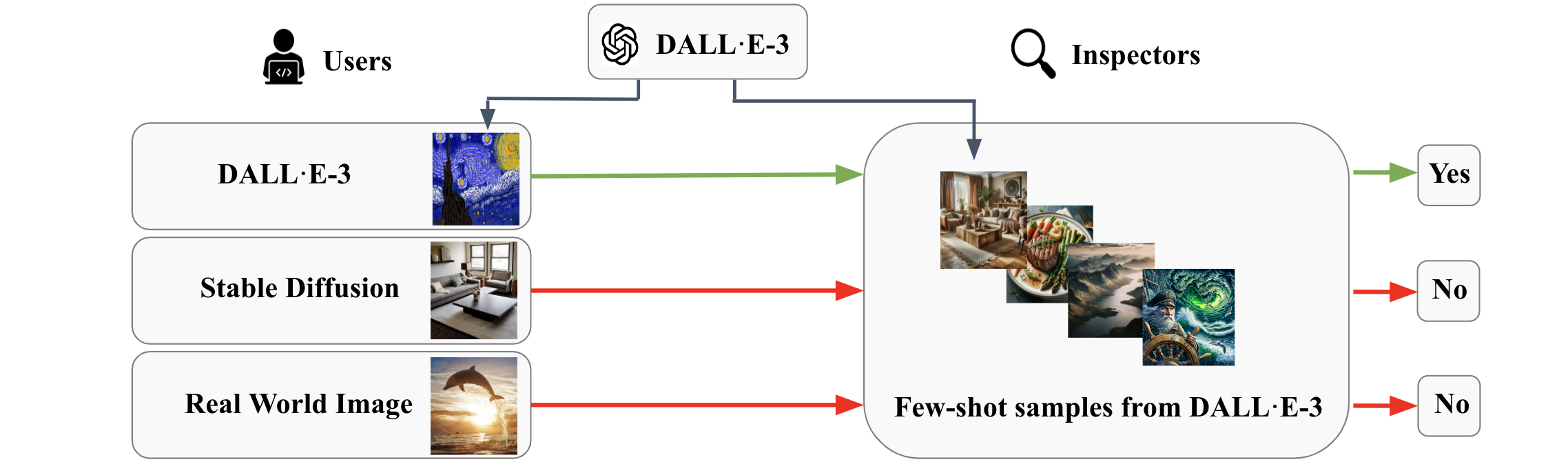
Model-agnostic Origin Attribution of Generated Images with Few-shot Examples
Fengyuan Liu, Haochen Luo, Yiming Li, Philip Torr, Jindong Gu
Recent progress in visual generative models enables the generation of high-quality images. To prevent the misuse of generated images, it is important to identify the origin model that generates them. In this work, we study the origin attribution of generated images in a practical setting where only a few images generated by a source model are available and the source model cannot be accessed. The goal is to check if a given image is generated by the source model. We first formulate this problem as a few-shot one-class classification task. To solve the task, we propose OCC-CLIP, a CLIP-based framework for few-shot one-class classification, enabling the identification of an image's source model, even among multiple candidates. Extensive experiments corresponding to various generative models verify the effectiveness of our OCC-CLIP framework. Furthermore, an experiment based on the recently released DALL-E 3 API verifies the real-world applicability of our solution.
Read more7/19/2024

0
Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields. However, their ability to create hyper-realistic images poses significant challenges in distinguishing between real and synthetic content, raising concerns about digital authenticity and potential misuse in creating deepfakes. This work introduces a robust detection framework that integrates image and text features extracted by CLIP model with a Multilayer Perceptron (MLP) classifier. We propose a novel loss that can improve the detector's robustness and handle imbalanced datasets. Additionally, we flatten the loss landscape during the model training to improve the detector's generalization capabilities. The effectiveness of our method, which outperforms traditional detection techniques, is demonstrated through extensive experiments, underscoring its potential to set a new state-of-the-art approach in DM-generated image detection. The code is available at https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection.
Read more9/10/2024
0
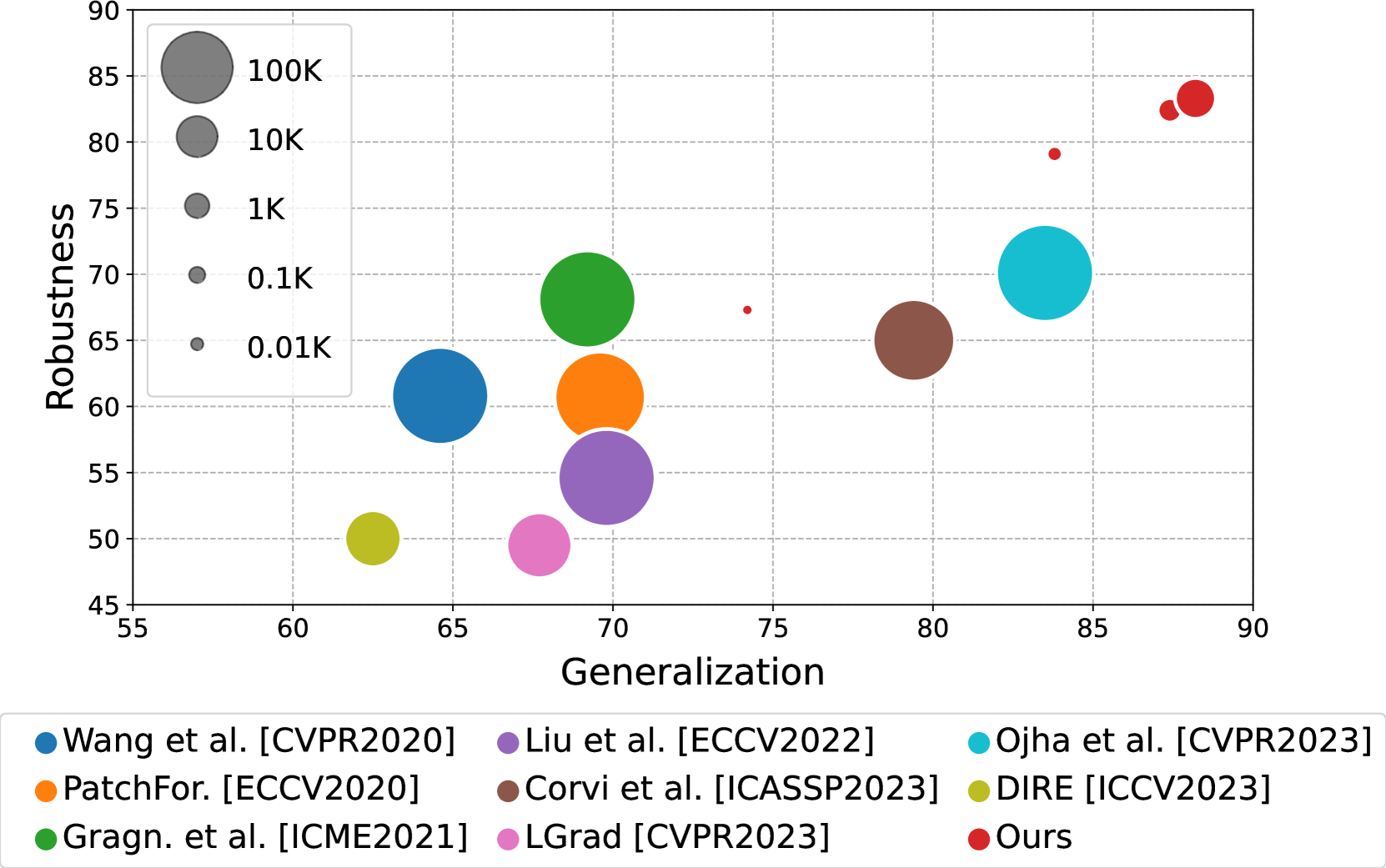
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
Read more4/30/2024