Model-agnostic Origin Attribution of Generated Images with Few-shot Examples

0
Sign in to get full access
Overview
- This paper proposes a novel approach for attributing the origin of generated images to the model that created them, using only a few example images.
- The method is "model-agnostic", meaning it can work with different types of generative models without requiring access to the model architecture or training process.
- The approach leverages CLIP, a powerful vision-language model, to classify the generated images based on their similarity to the few-shot examples.
Plain English Explanation
Imagine you have a collection of images, and you want to figure out which ones were created by different AI models. This can be useful for detecting fake or manipulated images, or for understanding the unique "styles" of various generative models.
The researchers developed a clever way to do this without needing detailed information about the inner workings of the AI models. They use a tool called CLIP, which is trained to understand the relationship between images and the language used to describe them.
By showing CLIP just a few example images from each model, the researchers can train it to recognize the unique "fingerprint" of that model. Then, when presented with a new generated image, CLIP can analyze it and determine which model is most likely to have created it.
This is a powerful technique because it doesn't require access to the actual AI models themselves. It can work with any type of generative model, whether it's a simple algorithm or a complex deep learning system. The key is in leveraging the capabilities of CLIP to make these attributions.
Technical Explanation
The core of the researchers' approach is to use CLIP, a state-of-the-art vision-language model, to classify generated images based on their similarity to few-shot examples. CLIP is trained on a large dataset of image-text pairs, allowing it to learn rich representations that capture the semantic and visual relationships between images and language.
The researchers fine-tune CLIP on a small set of example images from each generative model they want to analyze. This teaches CLIP to recognize the unique "style" of each model, based on subtle visual cues that distinguish the generated outputs.
Then, when presented with a new generated image, CLIP can analyze it and predict which model is most likely to have created it. This is done by measuring the similarity between the input image and the fine-tuned CLIP representations for each model.
The key advantage of this approach is that it is completely model-agnostic - it doesn't require any internal information about the generative models, such as their architecture or training process. As long as the researchers have access to a few example outputs from each model, the CLIP-based classification can be applied.
Critical Analysis
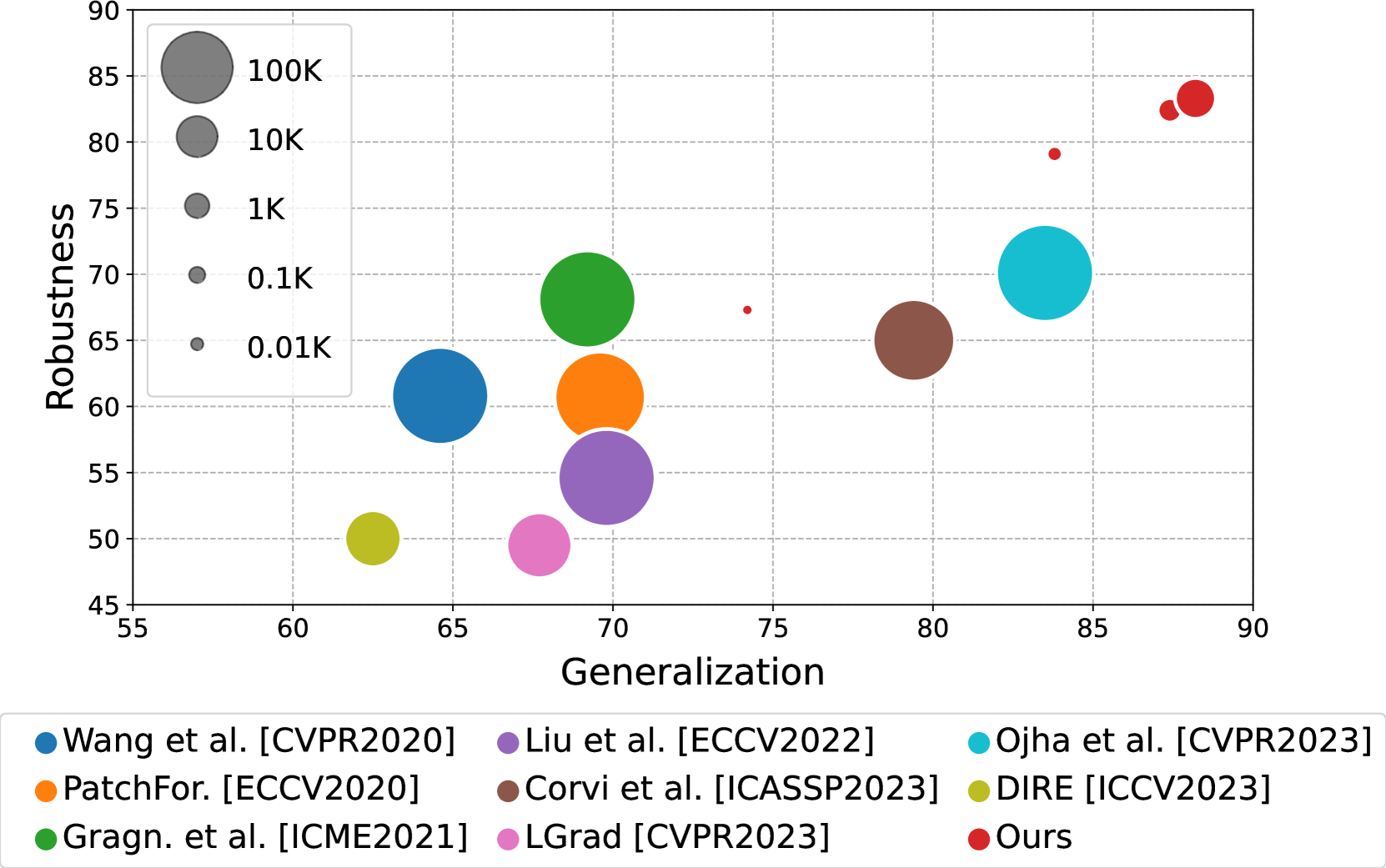
The researchers demonstrate the effectiveness of their approach through extensive experiments on a variety of generative models, including StyleGAN, Stable Diffusion, and DALL-E 2. The results show that the CLIP-based classification can accurately attribute generated images to their source models, even when using just a handful of example images for fine-tuning.
However, the paper does acknowledge some limitations. The performance of the method can be affected by factors such as the diversity and quality of the few-shot examples, as well as the inherent similarities between different generative models. Additionally, the approach may not be as effective in situations where the generated images have been heavily manipulated or edited after creation.
Further research could explore ways to address these limitations, such as investigating more advanced few-shot learning techniques or developing methods to better capture the unique characteristics of different generative models. It would also be interesting to see how this approach could be applied in practical scenarios, such as detecting and mitigating the spread of AI-generated disinformation or deepfakes.
Conclusion
This paper presents a novel, model-agnostic approach for attributing the origin of generated images to the specific AI models that created them. By leveraging the power of CLIP, the researchers have developed a flexible and effective way to analyze the unique "fingerprints" of different generative models, using only a small set of example images.
This work has important implications for understanding and controlling the proliferation of synthetic media, as well as for advancing the field of generative AI research more broadly. The ability to accurately attribute generated content to its source can be a valuable tool for a wide range of applications, from content moderation to forensic analysis.
Overall, this paper represents an exciting step forward in the quest to develop robust and practical methods for understanding and managing the rapidly evolving landscape of generative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Model-agnostic Origin Attribution of Generated Images with Few-shot Examples
Fengyuan Liu, Haochen Luo, Yiming Li, Philip Torr, Jindong Gu
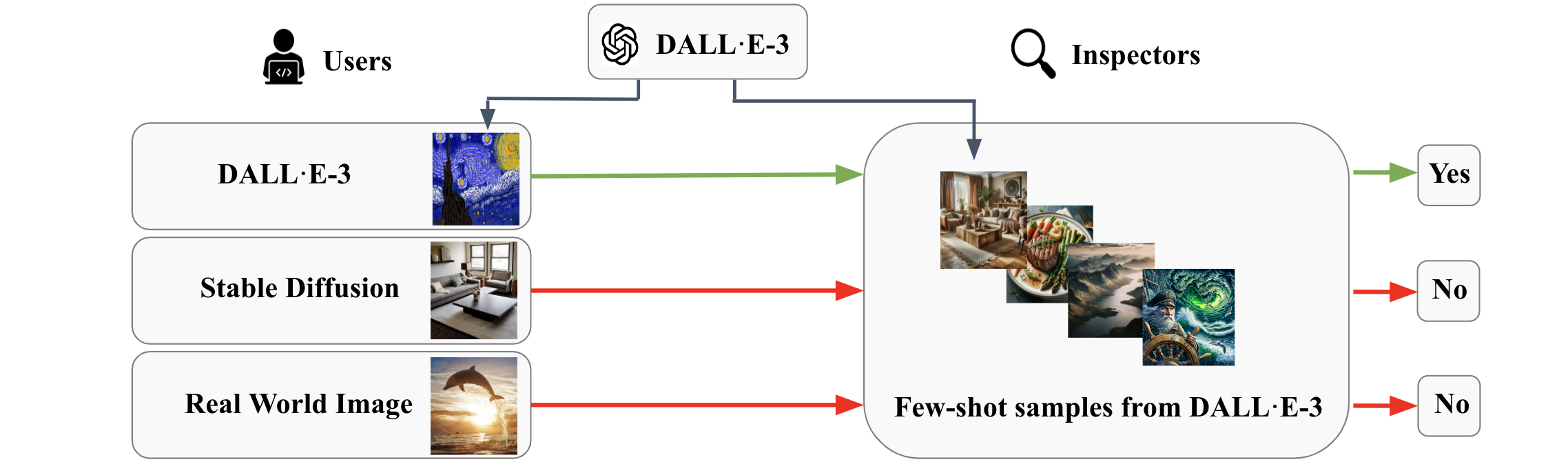
Recent progress in visual generative models enables the generation of high-quality images. To prevent the misuse of generated images, it is important to identify the origin model that generates them. In this work, we study the origin attribution of generated images in a practical setting where only a few images generated by a source model are available and the source model cannot be accessed. The goal is to check if a given image is generated by the source model. We first formulate this problem as a few-shot one-class classification task. To solve the task, we propose OCC-CLIP, a CLIP-based framework for few-shot one-class classification, enabling the identification of an image's source model, even among multiple candidates. Extensive experiments corresponding to various generative models verify the effectiveness of our OCC-CLIP framework. Furthermore, an experiment based on the recently released DALL-E 3 API verifies the real-world applicability of our solution.
Read more7/19/2024

0
Are CLIP features all you need for Universal Synthetic Image Origin Attribution?
Dario Cioni, Christos Tzelepis, Lorenzo Seidenari, Ioannis Patras
The steady improvement of Diffusion Models for visual synthesis has given rise to many new and interesting use cases of synthetic images but also has raised concerns about their potential abuse, which poses significant societal threats. To address this, fake images need to be detected and attributed to their source model, and given the frequent release of new generators, realistic applications need to consider an Open-Set scenario where some models are unseen at training time. Existing forensic techniques are either limited to Closed-Set settings or to GAN-generated images, relying on fragile frequency-based fingerprint features. By contrast, we propose a simple yet effective framework that incorporates features from large pre-trained foundation models to perform Open-Set origin attribution of synthetic images produced by various generative models, including Diffusion Models. We show that our method leads to remarkable attribution performance, even in the low-data regime, exceeding the performance of existing methods and generalizes better on images obtained from a diverse set of architectures. We make the code publicly available at: https://github.com/ciodar/UniversalAttribution.
Read more8/20/2024

0
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Zihan Liu, Hanyi Wang, Yaoyu Kang, Shilin Wang
Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
Read more4/9/2024
0
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
Read more4/30/2024