Are Emergent Abilities in Large Language Models just In-Context Learning?

0
💬
Sign in to get full access
Overview
- This paper explores the concept of "emergent abilities" in large language models - capabilities that the models develop without being explicitly trained on them.
- The authors argue that these purported emergent abilities are actually the result of a combination of factors, including in-context learning, model memory, and linguistic knowledge.
- The researchers conducted over 1000 experiments to rigorously test their theory and found that language models do not truly exhibit emergent abilities, but rather leverage other mechanisms to excel in certain tasks.
Plain English Explanation
Large language models, such as GPT-3, have amazed researchers with their ability to perform tasks they were not specifically trained for. This has led to discussions about the potential and risks of these models, as they seem to be acquiring "emergent abilities" - skills that arise naturally without explicit training.
However, the authors of this paper argue that these purported emergent abilities are not actually emerging on their own. Instead, they result from a combination of the model's ability to learn from just a few examples (known as in-context learning), its memory of previous information, and its general linguistic knowledge.
To test this theory, the researchers conducted over 1000 experiments. Their findings suggest that language models do not truly have emergent abilities, but rather they are able to excel at certain tasks by leveraging these other mechanisms. This means that the capabilities of these models should not be overestimated, as they are not acquiring new skills entirely on their own.
The paper provides a foundational explanation for how language models achieve their impressive performance, which can help guide their efficient use and provide a better understanding of their limitations.
Technical Explanation
The researchers begin by noting that large language models, which can have billions of parameters and are trained on extensive web-scale data, have been observed to acquire certain capabilities without being explicitly trained on them. These "emergent abilities" have been a significant focus in discussions about the potential and risks of such models.
However, the authors argue that these emergent abilities are confounded by other factors, such as the models' ability to learn from just a few examples (in-context learning) and their general linguistic knowledge and memory. To rigorously test this hypothesis, the researchers conducted over 1000 experiments.
Their findings suggest that the purported emergent abilities are not truly emergent, but rather result from a combination of in-context learning, model memory, and linguistic knowledge. The authors provide a novel theoretical framework to explain this phenomenon and demonstrate that language models do not acquire new skills entirely on their own, but rather leverage these other mechanisms to excel at certain tasks.
This work is an important step in understanding the underlying mechanisms that drive language model performance, which can help guide their efficient use and provide a more nuanced view of their capabilities and limitations.
Critical Analysis
The paper presents a comprehensive and well-designed study that challenges the popular narrative of "emergent abilities" in large language models. The researchers' thorough experimental approach, with over 1000 trials, lends credibility to their findings and the proposed theoretical framework.
One potential limitation of the study is that it focuses primarily on evaluating language model performance on specific tasks, rather than exploring the broader cognitive capabilities of these models. The authors acknowledge this and suggest that further research is needed to quantify the emergence of cognitive intelligence in language models.
Additionally, the paper does not delve into the potential implications of its findings for the evaluation of language model emergence or the confounds that may arise in training and testing tasks. Exploring these aspects could provide valuable insights for the field.
Overall, the paper presents a compelling argument and robust evidence that the "emergent abilities" of language models are not truly emergent, but rather the result of more fundamental mechanisms. This work serves as an important contribution to the ongoing discussions about the capabilities and limitations of large language models.
Conclusion
This research paper provides a significant challenge to the prevalent notion of "emergent abilities" in large language models. The authors present a novel theoretical framework and rigorously demonstrate through extensive experimentation that the purported emergent capabilities are not truly emergent, but rather the product of a combination of in-context learning, model memory, and linguistic knowledge.
This work is a crucial step in understanding the underlying mechanisms that drive language model performance, which can help guide their efficient use and provide a more nuanced view of their capabilities and limitations. By dispelling the myth of emergent abilities, the paper encourages a more realistic and cautious approach to evaluating and deploying these powerful models.
The findings of this research have important implications for the development of cognitive intelligence in language models, the evaluation of their emergence, and the identification of potential confounds in their training and testing. As the field of large language models continues to evolve, this work serves as a valuable foundation for future research and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Are Emergent Abilities in Large Language Models just In-Context Learning?
Sheng Lu, Irina Bigoulaeva, Rachneet Sachdeva, Harish Tayyar Madabushi, Iryna Gurevych
Large language models, comprising billions of parameters and pre-trained on extensive web-scale corpora, have been claimed to acquire certain capabilities without having been specifically trained on them. These capabilities, referred to as emergent abilities, have been a driving force in discussions regarding the potentials and risks of language models. A key challenge in evaluating emergent abilities is that they are confounded by model competencies that arise through alternative prompting techniques, including in-context learning, which is the ability of models to complete a task based on a few examples. We present a novel theory that explains emergent abilities, taking into account their potential confounding factors, and rigorously substantiate this theory through over 1000 experiments. Our findings suggest that purported emergent abilities are not truly emergent, but result from a combination of in-context learning, model memory, and linguistic knowledge. Our work is a foundational step in explaining language model performance, providing a template for their efficient use and clarifying the paradox of their ability to excel in some instances while faltering in others. Thus, we demonstrate that their capabilities should not be overestimated.
Read more7/16/2024
0
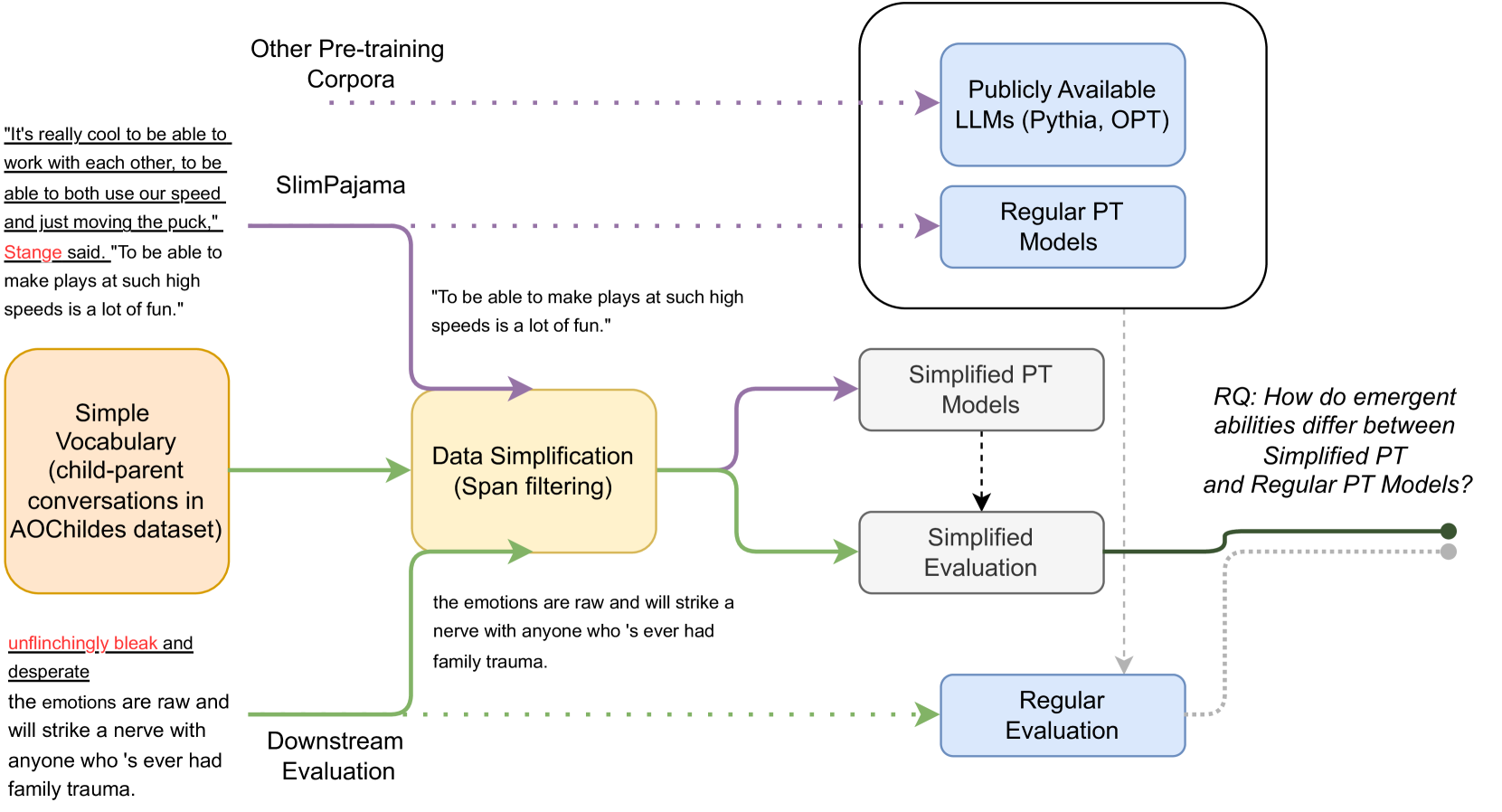
Emergent Abilities in Reduced-Scale Generative Language Models
Sherin Muckatira, Vijeta Deshpande, Vladislav Lialin, Anna Rumshisky
Large language models can solve new tasks without task-specific fine-tuning. This ability, also known as in-context learning (ICL), is considered an emergent ability and is primarily seen in large language models with billions of parameters. This study investigates if such emergent properties are strictly tied to model size or can be demonstrated by smaller models trained on reduced-scale data. To explore this, we simplify pre-training data and pre-train 36 causal language models with parameters varying from 1 million to 165 million parameters. We show that models trained on this simplified pre-training data demonstrate enhanced zero-shot capabilities across various tasks in simplified language, achieving performance comparable to that of pre-trained models six times larger on unrestricted language. This suggests that downscaling the language allows zero-shot learning capabilities to emerge in models with limited size. Additionally, we find that these smaller models pre-trained on simplified data demonstrate a power law relationship between the evaluation loss and the three scaling factors: compute, dataset size, and model size.
Read more4/4/2024
📈
0
A Percolation Model of Emergence: Analyzing Transformers Trained on a Formal Language
Ekdeep Singh Lubana, Kyogo Kawaguchi, Robert P. Dick, Hidenori Tanaka
Increase in data, size, or compute can lead to sudden learning of specific capabilities by a neural network -- a phenomenon often called emergence''. Beyond scientific understanding, establishing the causal factors underlying such emergent capabilities is crucial to enable risk regulation frameworks for AI. In this work, we seek inspiration from study of emergent properties in other fields and propose a phenomenological definition for the concept in the context of neural networks. Our definition implicates the acquisition of general structures underlying the data-generating process as a cause of sudden performance growth for specific, narrower tasks. We empirically investigate this definition by proposing an experimental system grounded in a context-sensitive formal language and find that Transformers trained to perform tasks on top of strings from this language indeed exhibit emergent capabilities. Specifically, we show that once the language's underlying grammar and context-sensitivity inducing structures are learned by the model, performance on narrower tasks suddenly begins to improve. We then analogize our network's learning dynamics with the process of percolation on a bipartite graph, establishing a formal phase transition model that predicts the shift in the point of emergence observed in our experiments when changing the data structure. Overall, our experimental and theoretical frameworks yield a step towards better defining, characterizing, and predicting emergence in neural networks.
Read more9/10/2024
0
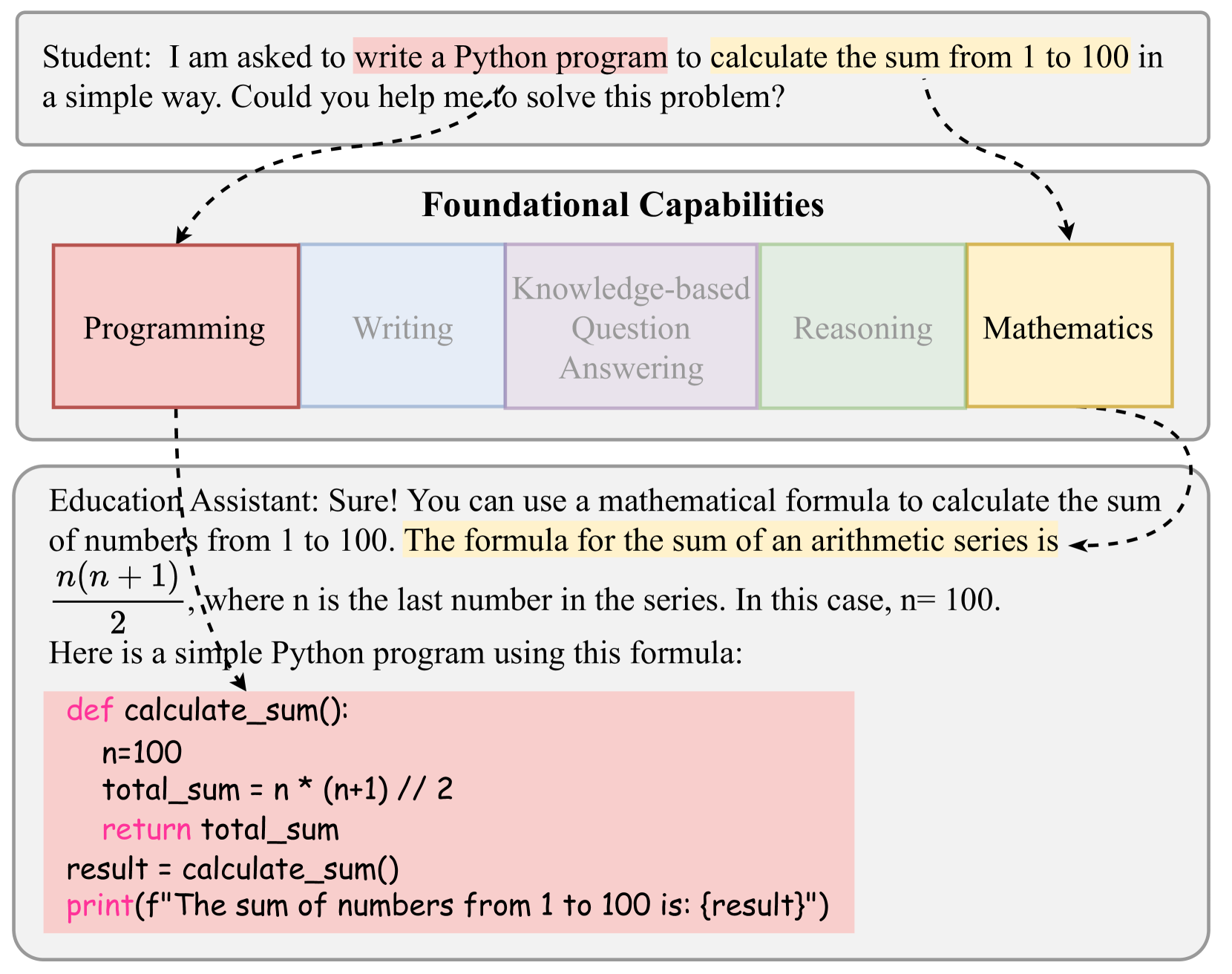
Adapting Large Language Models for Education: Foundational Capabilities, Potentials, and Challenges
Qingyao Li, Lingyue Fu, Weiming Zhang, Xianyu Chen, Jingwei Yu, Wei Xia, Weinan Zhang, Ruiming Tang, Yong Yu
Online education platforms, leveraging the internet to distribute education resources, seek to provide convenient education but often fall short in real-time communication with students. They often struggle to address the diverse obstacles students encounter throughout their learning journey. Solving the problems encountered by students poses a significant challenge for traditional deep learning models, as it requires not only a broad spectrum of subject knowledge but also the ability to understand what constitutes a student's individual difficulties. It's challenging for traditional machine learning models, as they lack the capacity to comprehend students' personalized needs. Recently, the emergence of large language models (LLMs) offers the possibility for resolving this issue by comprehending individual requests. Although LLMs have been successful in various fields, creating an LLM-based education system is still challenging for the wide range of educational skills required. This paper reviews the recently emerged LLM research related to educational capabilities, including mathematics, writing, programming, reasoning, and knowledge-based question answering, with the aim to explore their potential in constructing the next-generation intelligent education system. Specifically, for each capability, we focus on investigating two aspects. Firstly, we examine the current state of LLMs regarding this capability: how advanced they have become, whether they surpass human abilities, and what deficiencies might exist. Secondly, we evaluate whether the development methods for LLMs in this area are generalizable, that is, whether these methods can be applied to construct a comprehensive educational supermodel with strengths across various capabilities, rather than being effective in only a singular aspect.
Read more4/29/2024