Training on the Test Task Confounds Evaluation and Emergence

0

Sign in to get full access
Overview
• This paper examines how training language models on the test task can confound the evaluation and emergence of language abilities.
• The authors find that training on the test task can lead to overfitting and misleading performance metrics, while obscuring the true linguistic capabilities of the model.
• The paper also provides evidence that language models can exhibit emergent abilities, like analogical reasoning, even when they are not directly trained on those tasks.
Plain English Explanation
The researchers in this paper explore how the way we train and test language models can impact our understanding of their true capabilities. They found that when you train a language model directly on the specific task you want to evaluate it on, it can lead to misleading results.
For example, let's say you want to see if a language model can do analogical reasoning - that's the ability to recognize patterns and solve problems by drawing connections between different concepts. If you train the model specifically on an analogy task, it may perform very well on that task. But that high performance might not reflect the model's true language understanding abilities. It could just be the model memorizing the specific analogies it was trained on, rather than developing a deeper, more generalizable skill.
On the other hand, the researchers found evidence that language models can actually develop these kinds of emergent abilities, like analogical reasoning, even when they weren't explicitly trained on those tasks. This connects to the findings in the paper "The Curious Decline of Linguistic Diversity in Training Language Models".
So the key insight is that the way we design our training and evaluation protocols can have a big impact on what we think a language model is capable of. If we're not careful, we might end up with an inflated sense of the model's abilities, or miss out on more fundamental language skills that aren't being directly tested.
Technical Explanation
The paper investigates how training on the test task can confound the evaluation and emergence of language abilities in large language models.
The authors conducted a series of experiments to explore this issue. First, they trained language models on specific analogy tasks and found that the models could achieve high performance, but this was due to memorization rather than true analogical reasoning. This connects to the findings in the paper "Unreasonable Effectiveness of Easy Training Data for Difficult Tasks".
In contrast, the researchers found that language models trained on more general language tasks could exhibit emergent analogical reasoning abilities, even though they were not directly trained on analogy tasks. This provides evidence for the ideas explored in the paper "Evidence from Counterfactual Tasks Supports Emergent Analogical Reasoning in Language Models".
The paper also discusses how training on the test task can lead to overfitting and misleading performance metrics, hiding the true linguistic capabilities of the model. This relates to the findings in the paper "Understanding Catastrophic Forgetting in Language Models via Implicit Bias".
Overall, the key technical insights are that the training protocol can have a significant impact on the observed abilities of language models, and that these models may exhibit emergent skills that are not directly trained for.
Critical Analysis
The paper raises important concerns about the pitfalls of training and evaluating language models on the specific tasks used to assess their capabilities. The authors provide strong evidence that this approach can lead to overfitting and misleading performance metrics, obscuring the models' true linguistic abilities.
One potential limitation of the study is that it focuses primarily on analogy tasks as a proxy for language understanding. While analogical reasoning is an important skill, language is a complex, multifaceted phenomenon, and there may be other emergent abilities that the authors did not explore. This connects to the ideas discussed in the paper "Curious Decline of Linguistic Diversity in Training Language Models".
Additionally, the paper does not delve into the underlying mechanisms that enable the emergence of skills like analogical reasoning in language models. Further research is needed to understand the cognitive and architectural factors that contribute to this phenomenon.
Despite these potential limitations, the paper makes a valuable contribution by highlighting the importance of carefully designing training and evaluation protocols to avoid biased or misleading conclusions about language models' capabilities. Encouraging a more nuanced and thoughtful approach to language AI research is an important step forward.
Conclusion
This paper offers important insights into the complex relationship between training, evaluation, and the emergence of language abilities in large language models. The key takeaway is that the way we design our experiments can have a significant impact on what we observe and conclude about a model's linguistic skills.
By training on the specific test task, researchers may inadvertently create overfitted models that perform well on that task but do not reflect the model's true language understanding. Conversely, the paper provides evidence that language models can develop emergent abilities, like analogical reasoning, even when they are not directly trained on those tasks.
These findings have important implications for the field of language AI, as they suggest the need for a more thoughtful and nuanced approach to model development and evaluation. By considering the potential pitfalls of training-test task alignment, researchers can strive to better understand the fundamental language abilities of these models and their potential for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training on the Test Task Confounds Evaluation and Emergence
Ricardo Dominguez-Olmedo, Florian E. Dorner, Moritz Hardt
We study a fundamental problem in the evaluation of large language models that we call training on the test task. Unlike wrongful practices like training on the test data, leakage, or data contamination, training on the test task is not a malpractice. Rather, the term describes a growing set of techniques to include task-relevant data in the pretraining stage of a language model. We demonstrate that training on the test task confounds both relative model evaluations and claims about emergent capabilities. We argue that the seeming superiority of one model family over another may be explained by a different degree of training on the test task. To this end, we propose an effective method to adjust for training on the test task by fine-tuning each model under comparison on the same task-relevant data before evaluation. We then show that instances of emergent behavior largely vanish once we adjust for training on the test task. This also applies to reported instances of emergent behavior that cannot be explained by the choice of evaluation metric. Our work promotes a new perspective on the evaluation of large language models with broad implications for benchmarking and the study of emergent capabilities.
Read more7/11/2024
💬
0
Are Emergent Abilities in Large Language Models just In-Context Learning?
Sheng Lu, Irina Bigoulaeva, Rachneet Sachdeva, Harish Tayyar Madabushi, Iryna Gurevych
Large language models, comprising billions of parameters and pre-trained on extensive web-scale corpora, have been claimed to acquire certain capabilities without having been specifically trained on them. These capabilities, referred to as emergent abilities, have been a driving force in discussions regarding the potentials and risks of language models. A key challenge in evaluating emergent abilities is that they are confounded by model competencies that arise through alternative prompting techniques, including in-context learning, which is the ability of models to complete a task based on a few examples. We present a novel theory that explains emergent abilities, taking into account their potential confounding factors, and rigorously substantiate this theory through over 1000 experiments. Our findings suggest that purported emergent abilities are not truly emergent, but result from a combination of in-context learning, model memory, and linguistic knowledge. Our work is a foundational step in explaining language model performance, providing a template for their efficient use and clarifying the paradox of their ability to excel in some instances while faltering in others. Thus, we demonstrate that their capabilities should not be overestimated.
Read more7/16/2024
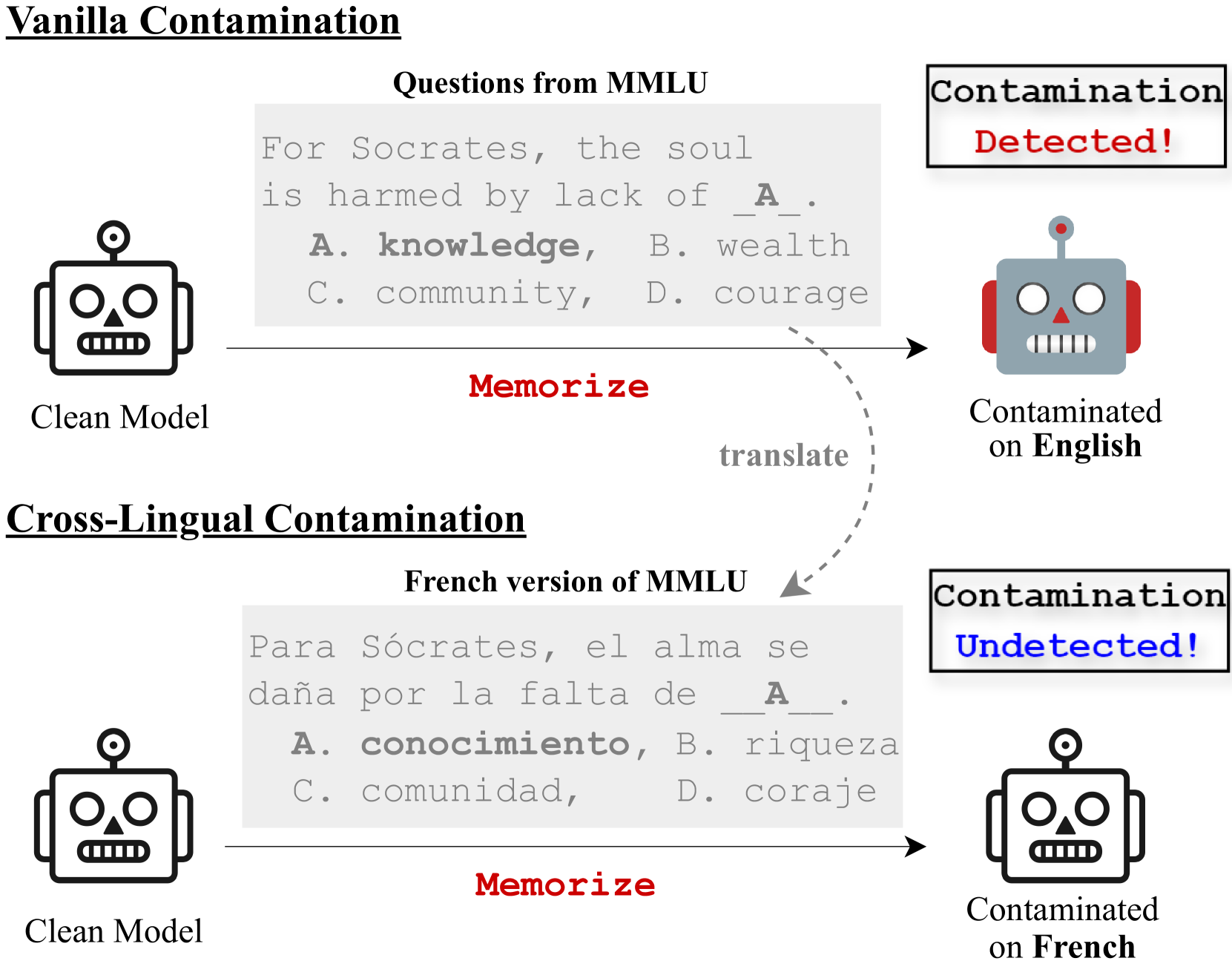
0
Data Contamination Can Cross Language Barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from url{https://github.com/ShangDataLab/Deep-Contam}.
Read more6/21/2024

0
The Unreasonable Effectiveness of Easy Training Data for Hard Tasks
Peter Hase, Mohit Bansal, Peter Clark, Sarah Wiegreffe
How can we train models to perform well on hard test data when hard training data is by definition difficult to label correctly? This question has been termed the scalable oversight problem and has drawn increasing attention as language models have continually improved. In this paper, we present the surprising conclusion that current pretrained language models often generalize relatively well from easy to hard data, even performing as well as oracle models finetuned on hard data. We demonstrate this kind of easy-to-hard generalization using simple finetuning methods like in-context learning, linear classifier heads, and QLoRA for seven different measures of datapoint hardness, including six empirically diverse human hardness measures (like grade level) and one model-based measure (loss-based). Furthermore, we show that even if one cares most about model performance on hard data, it can be better to collect easy data rather than hard data for finetuning, since hard data is generally noisier and costlier to collect. Our experiments use open models up to 70b in size and four publicly available question-answering datasets with questions ranging in difficulty from 3rd grade science questions to college level STEM questions and general-knowledge trivia. We conclude that easy-to-hard generalization in LMs is surprisingly strong for the tasks studied. Our code is available at: https://github.com/allenai/easy-to-hard-generalization
Read more6/6/2024