Do Large Language Models Exhibit Cognitive Dissonance? Studying the Difference Between Revealed Beliefs and Stated Answers
2406.14986
0
0
Abstract
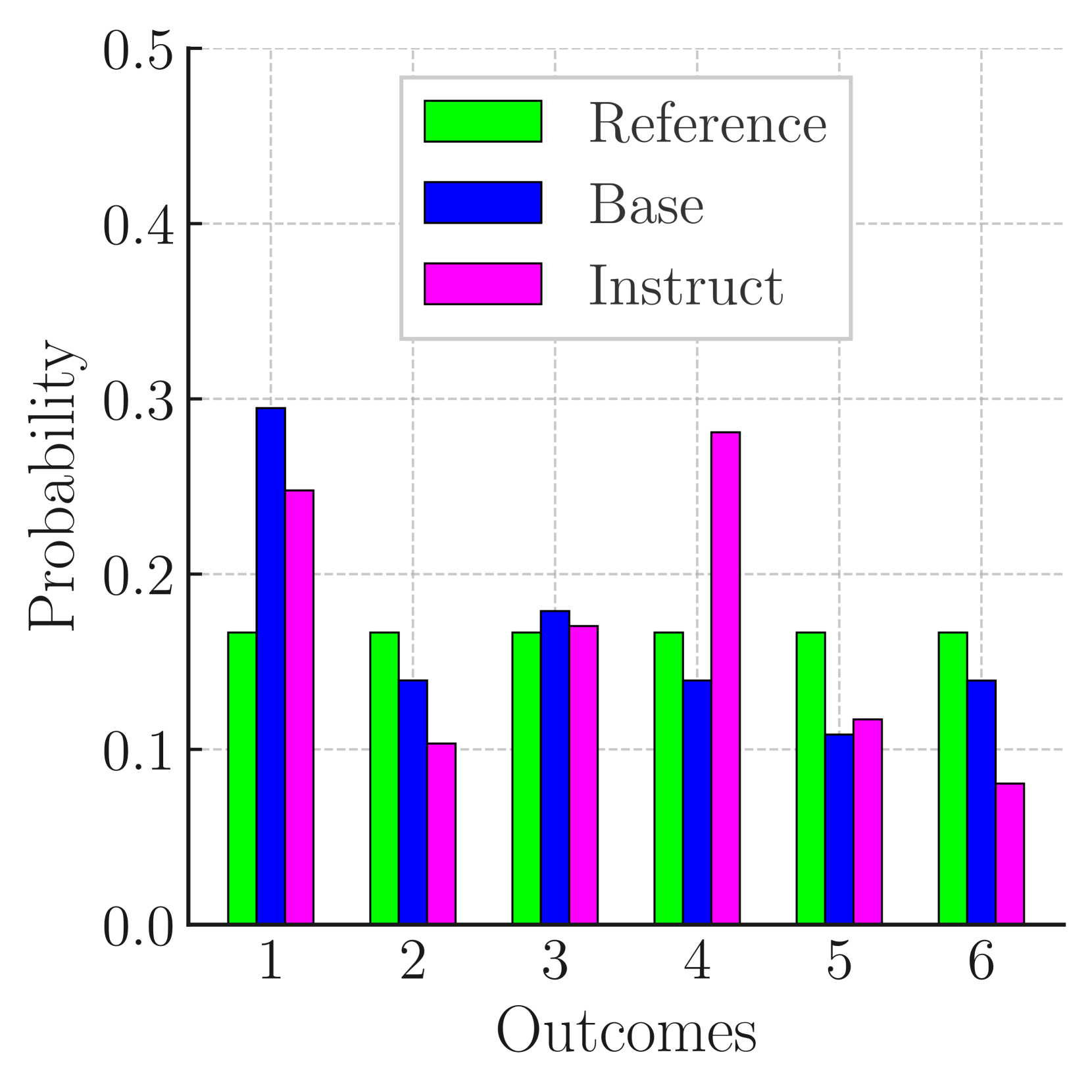
Prompting and Multiple Choices Questions (MCQ) have become the preferred approach to assess the capabilities of Large Language Models (LLMs), due to their ease of manipulation and evaluation. Such experimental appraisals have pointed toward the LLMs' apparent ability to perform causal reasoning or to grasp uncertainty. In this paper, we investigate whether these abilities are measurable outside of tailored prompting and MCQ by reformulating these issues as direct text completion - the foundation of LLMs. To achieve this goal, we define scenarios with multiple possible outcomes and we compare the prediction made by the LLM through prompting (their Stated Answer) to the probability distributions they compute over these outcomes during next token prediction (their Revealed Belief). Our findings suggest that the Revealed Belief of LLMs significantly differs from their Stated Answer and hint at multiple biases and misrepresentations that their beliefs may yield in many scenarios and outcomes. As text completion is at the core of LLMs, these results suggest that common evaluation methods may only provide a partial picture and that more research is needed to assess the extent and nature of their capabilities.
Create account to get full access
Overview
- This paper investigates whether large language models exhibit cognitive dissonance by studying the differences between their revealed beliefs and stated answers.
- The researchers designed experiments to probe the models' responses on sensitive topics and compared their stated answers to their revealed beliefs.
- The findings suggest that large language models can sometimes express beliefs that conflict with their stated answers, potentially indicating a form of cognitive dissonance.
Plain English Explanation
The researchers in this paper wanted to understand whether large language models, which are powerful AI systems trained on vast amounts of text data, might exhibit a phenomenon called "cognitive dissonance." Cognitive dissonance refers to the mental discomfort that can arise when someone holds two contradictory beliefs or attitudes.
To investigate this, the researchers designed experiments that would probe the models' responses on sensitive topics. They compared the models' stated answers - the things they directly said in response to questions - to their "revealed beliefs," which were inferred from other patterns in their language. The idea was that if the models' stated answers and revealed beliefs didn't line up, that could be a sign of cognitive dissonance.
The researchers found that in some cases, the large language models did express beliefs that conflicted with their stated answers. This suggests that these powerful AI systems may not always have a fully coherent or consistent understanding of the topics they're discussing. It raises questions about whether they can faithfully express their true beliefs and reasoning.
The findings have important implications for how we interpret and rely on the outputs of large language models, especially when it comes to sensitive or controversial topics. It suggests we need to be cautious about taking their stated responses at face value and look for potential inconsistencies or hidden biases in their underlying beliefs.
Technical Explanation
The researchers designed a series of experiments to probe whether large language models exhibit cognitive dissonance - a disconnect between their stated answers and their revealed beliefs. They used a technique called "constrained generation" to carefully control the prompts given to the models, allowing them to measure the differences between the models' stated responses and their underlying language patterns that revealed their true beliefs.
The experiments covered a range of sensitive topics, including politics, ethics, and social issues. The researchers found that in some cases, the models' stated answers contradicted the beliefs that were revealed through their language use. This suggests the models may not have a fully coherent or consistent understanding of these complex topics, despite their impressive language generation capabilities.
The findings build on previous research showing that large language models can struggle with tasks that require logical reasoning and consistency, and raise questions about their ability to faithfully express their true beliefs and reasoning.
The researchers also explored the potential mechanisms behind this phenomenon, including the models' training data and the ways they learn to generate responses. They discuss how the models' language generation may be influenced by factors like task framing, social biases, and the need to appear coherent, even if it means expressing beliefs that are not fully aligned.
Overall, the findings suggest that while large language models are powerful tools, we need to be cautious about interpreting their outputs, especially on sensitive topics. The research highlights the importance of probing the models' underlying beliefs and reasoning, rather than simply accepting their stated responses at face value.
Critical Analysis
The researchers acknowledge several limitations to their study. First, the experiments were conducted on a relatively small number of language models, so the findings may not generalize to all large language models. Additionally, the researchers relied on indirect methods to infer the models' revealed beliefs, which could be influenced by the specific prompts and techniques used.
Another potential issue is that the researchers did not explicitly test for the presence of cognitive dissonance in human participants, making it difficult to determine whether the observed discrepancies in the models' responses are truly indicative of a form of cognitive dissonance, or simply reflect the inherent complexity and context-dependent nature of language use.
It's also worth noting that the paper does not delve deeply into the potential causes or implications of the observed discrepancies. While the researchers speculate about factors like training data and the need for coherence, further research is needed to fully understand the underlying mechanisms at play.
Despite these limitations, the study raises important questions about the reliability and interpretability of large language models, particularly when it comes to sensitive or controversial topics. The findings suggest that we should be cautious about relying too heavily on the stated outputs of these models, and instead seek to understand their deeper, potentially inconsistent beliefs and reasoning.
Conclusion
This paper presents a thought-provoking investigation into whether large language models exhibit a form of cognitive dissonance, where their stated answers and underlying beliefs are not fully aligned. The researchers designed a series of experiments to probe the models' responses on sensitive topics, and found evidence of discrepancies between the models' stated answers and their revealed beliefs.
The findings have important implications for how we interpret and rely on the outputs of large language models, especially when it comes to complex or controversial subjects. They suggest that we need to look beyond the models' surface-level responses and strive to understand their deeper, potentially inconsistent beliefs and reasoning.
While the study has some limitations, it opens up new avenues for research on the reliability, transparency, and interpretability of these powerful AI systems. As large language models continue to be deployed in increasingly high-stakes applications, understanding their true capabilities and limitations will be crucial for ensuring they are used responsibly and ethically.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
0
0
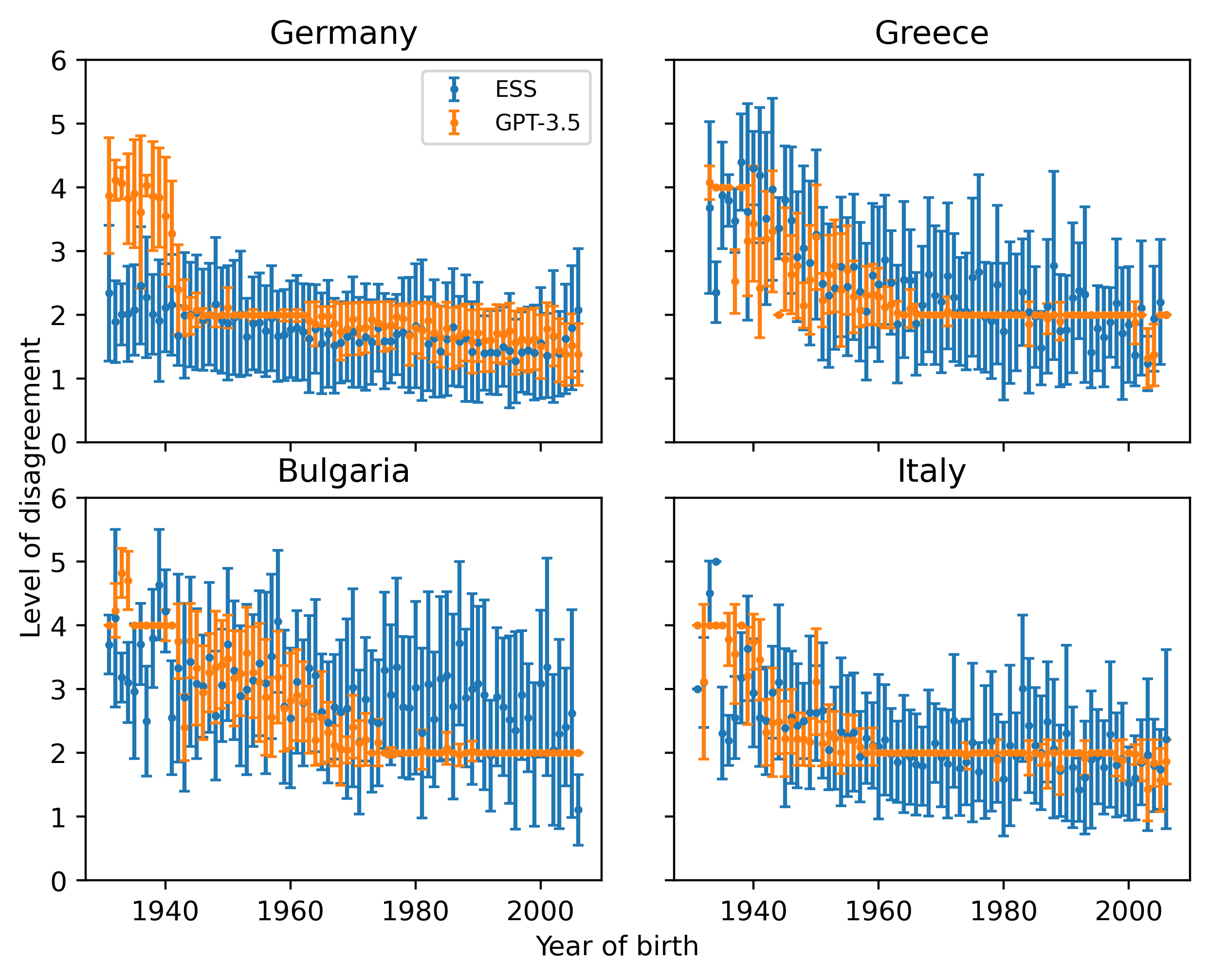
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
5/30/2024

Beyond the Answers: Reviewing the Rationality of Multiple Choice Question Answering for the Evaluation of Large Language Models
Haochun Wang, Sendong Zhao, Zewen Qiang, Nuwa Xi, Bing Qin, Ting Liu
0
0
In the field of natural language processing (NLP), Large Language Models (LLMs) have precipitated a paradigm shift, markedly enhancing performance in natural language generation tasks. Despite these advancements, the comprehensive evaluation of LLMs remains an inevitable challenge for the community. Recently, the utilization of Multiple Choice Question Answering (MCQA) as a benchmark for LLMs has gained considerable traction. This study first investigates the limitations of MCQA as an evaluation method for LLMs and then analyzes the fundamental reason for the limitations of MCQA, that while LLMs may select the correct answers, it is possible that they also recognize other wrong options as correct. Finally, we propose a dataset augmenting method for Multiple-Choice Questions (MCQs), MCQA+, that can more accurately reflect the performance of the model, which underscores the need for more robust evaluation mechanisms in assessing the performance of LLMs.
5/31/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024
💬
Exploring the Capabilities of Prompted Large Language Models in Educational and Assessment Applications
Subhankar Maity, Aniket Deroy, Sudeshna Sarkar
0
0
In the era of generative artificial intelligence (AI), the fusion of large language models (LLMs) offers unprecedented opportunities for innovation in the field of modern education. We embark on an exploration of prompted LLMs within the context of educational and assessment applications to uncover their potential. Through a series of carefully crafted research questions, we investigate the effectiveness of prompt-based techniques in generating open-ended questions from school-level textbooks, assess their efficiency in generating open-ended questions from undergraduate-level technical textbooks, and explore the feasibility of employing a chain-of-thought inspired multi-stage prompting approach for language-agnostic multiple-choice question (MCQ) generation. Additionally, we evaluate the ability of prompted LLMs for language learning, exemplified through a case study in the low-resource Indian language Bengali, to explain Bengali grammatical errors. We also evaluate the potential of prompted LLMs to assess human resource (HR) spoken interview transcripts. By juxtaposing the capabilities of LLMs with those of human experts across various educational tasks and domains, our aim is to shed light on the potential and limitations of LLMs in reshaping educational practices.
5/21/2024