Benchmarking Large Language Models for Math Reasoning Tasks

0

Sign in to get full access
Overview
- This paper benchmarks the mathematical reasoning capabilities of large language models (LLMs) across a variety of math tasks.
- The authors evaluate the performance of several prominent LLMs, including GPT-3, InstructGPT, and PaLM, on math problems ranging from algebra to calculus.
- The goal is to assess the current state of LLM abilities in mathematical reasoning and identify areas for future research and improvement.
Plain English Explanation
The researchers in this paper wanted to understand how well the latest and greatest language models, like GPT-3 and PaLM, can handle mathematical reasoning tasks. These models are incredibly powerful at understanding and generating human language, but math is a whole different ballgame.
The researchers put the models through their paces on a wide range of math problems, from basic algebra to more advanced calculus. They wanted to see how the models would fare at things like solving equations, explaining mathematical concepts, and even coming up with original solutions to problems.
The results were a bit of a mixed bag. The models did surprisingly well on some simpler math tasks, showing that they can grasp basic mathematical principles. But when it came to more complex, multi-step problems, the models struggled quite a bit. They often made mistakes or couldn't fully explain their reasoning.
This suggests that while these language models are making impressive strides, they still have a long way to go before they can match human-level mathematical reasoning. There's a lot of room for improvement, and the researchers hope that their findings will help guide future research and development in this area.
Technical Explanation
The researchers benchmarked the mathematical reasoning capabilities of several prominent large language models (LLMs), including GPT-3, InstructGPT, and PaLM. They evaluated the models' performance on a diverse set of math tasks, ranging from algebra and geometry to calculus and probability.
The benchmark dataset consisted of over 12,000 math problems, covering a wide range of difficulties and concepts. The researchers assessed the models' ability to correctly solve the problems, as well as their capacity to provide step-by-step explanations of their reasoning.
To establish a baseline, the researchers also evaluated human performance on the same benchmark tasks. This allowed them to contextualize the LLMs' results and identify areas where the models excel or struggle compared to human mathematicians.
The results showed that the LLMs exhibited varying levels of mathematical reasoning ability. On simpler, more straightforward problems, the models performed reasonably well, often matching or even exceeding human-level performance. However, on more complex, multi-step problems, the models consistently faltered, making mistakes and failing to provide comprehensive explanations.
The researchers found that the models' weaknesses were particularly pronounced in tasks that required deeper mathematical understanding, such as solving differential equations or proving geometric theorems. These findings suggest that while LLMs have made significant strides in natural language processing, they still face substantial challenges when it comes to mastering the intricacies of mathematical reasoning.
Critical Analysis
The researchers acknowledge several limitations to their study. First, the benchmark dataset, while comprehensive, may not fully capture the breadth of mathematical knowledge and skills required in real-world applications. There may be certain types of math problems or domains that are underrepresented in the dataset.
Additionally, the study focused solely on the performance of LLMs, without exploring the potential benefits of combining these models with other AI-powered tools or human experts. It's possible that a hybrid approach, where LLMs are used in conjunction with specialized mathematical reasoning systems or human guidance, could yield better results.
The researchers also note that the LLMs' performance may be influenced by biases and inconsistencies in the training data used to develop these models. If the training data does not adequately represent the diversity of mathematical knowledge and problem-solving strategies, the models may struggle to generalize their learning to novel situations.
Finally, the study does not delve into the underlying mechanisms and cognitive processes that drive the LLMs' mathematical reasoning. A more in-depth understanding of how these models approach and solve math problems could inform future architectural and algorithmic improvements.
Conclusion
This paper provides a comprehensive evaluation of the mathematical reasoning capabilities of several prominent large language models. The results suggest that while these models have made significant progress in natural language processing, they still face substantial challenges when it comes to mastering the intricacies of mathematical reasoning.
The findings highlight the need for continued research and development in this area, as the ability of AI systems to engage in robust mathematical reasoning will be crucial for a wide range of applications, from scientific discovery to complex decision-making. By identifying the strengths and limitations of current LLMs, this study lays the groundwork for future advancements in the field of AI-powered mathematical reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking Large Language Models for Math Reasoning Tasks
Kathrin Se{ss}ler, Yao Rong, Emek Gozluklu, Enkelejda Kasneci
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.
Read more8/21/2024

0
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
Read more4/8/2024
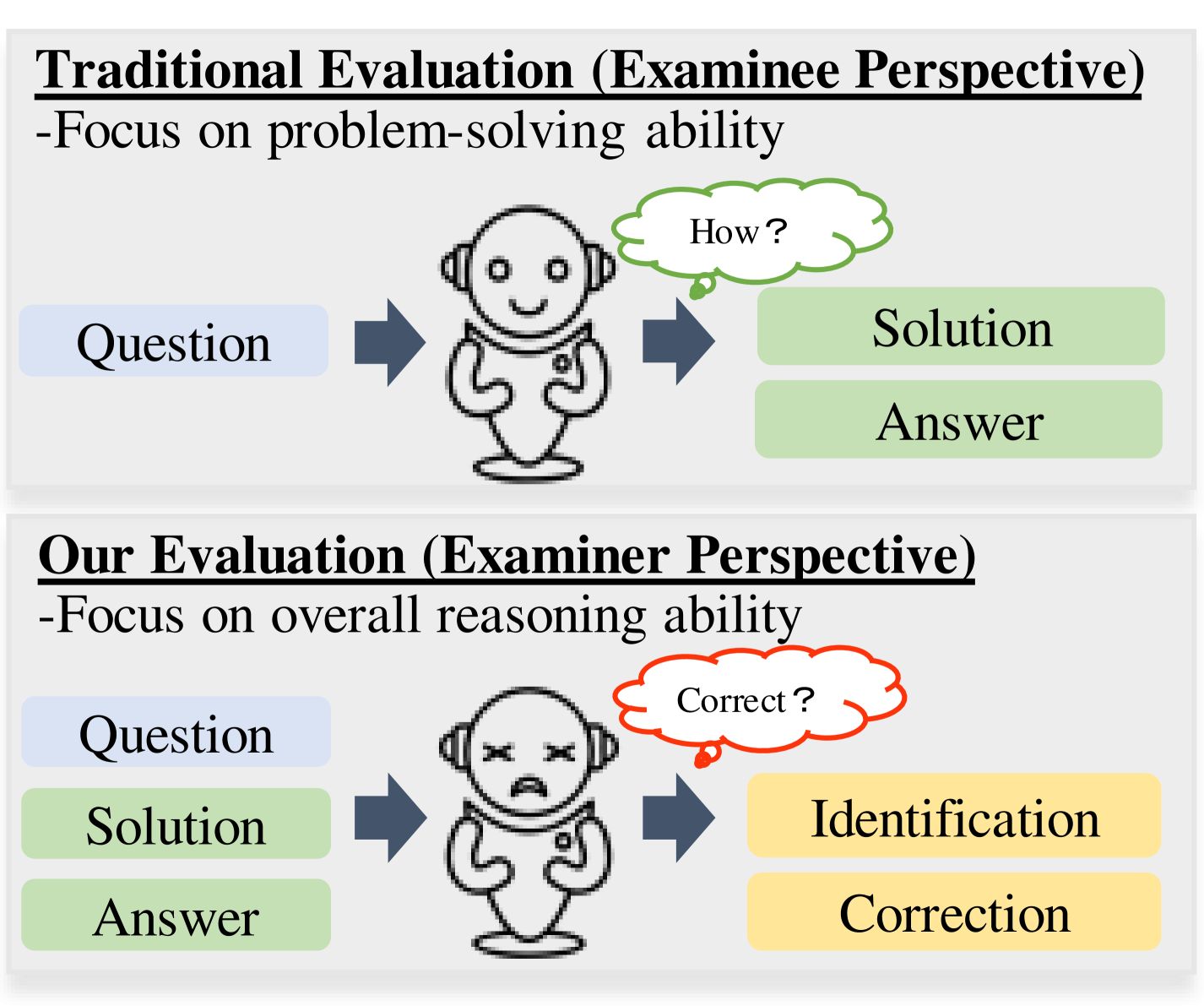
0
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Read more6/4/2024

0
LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs
Arash Gholami Davoodi, Seyed Pouyan Mousavi Davoudi, Pouya Pezeshkpour
Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that the most advanced model, GPT-4, achieved a mere 54% accuracy in a multiple-choice scenario. Interestingly, even when employing Chain-of-Thought prompting, we observe mostly no notable improvement. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. Further detailed analysis of the LLMs' performance across a range of topics showed significant discrepancy even for closely related subtopics within the same general mathematical area. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
Read more6/11/2024