Are Large Language Models Strategic Decision Makers? A Study of Performance and Bias in Two-Player Non-Zero-Sum Games

0
💬
Sign in to get full access
Overview
- Large Language Models (LLMs) are increasingly being used in real-world applications
- Game theory provides a framework to assess the decision-making abilities of LLMs
- Prior studies show LLMs can solve tasks with carefully curated prompts, but struggle when the problem or prompt changes
- This work investigates LLM behavior in strategic games like Stag Hunt and Prisoner's Dilemma
- Finds LLMs exhibit systematic biases that impact their performance
Plain English Explanation
Large language models (LLMs) like GPT-4 are powerful AI systems that can perform a wide variety of tasks. Researchers wanted to see how well these LLMs handle strategic decision-making, which is an important real-world skill.
They tested the LLMs on two classic game theory problems: the Stag Hunt and the Prisoner's Dilemma. In these games, players have to choose between different actions, and the outcome depends on the choices of both players.
The researchers found that the LLMs exhibited some consistent biases in how they approached these strategic games. For example, they may have a "positional bias" where they are more likely to choose a certain position in the game. Or they may have a "payoff bias" where they are overly focused on maximizing their own payoff rather than considering the overall outcome.
These biases meant the LLMs didn't always choose the "correct" action - the one that aligned with the preferences of both players. Their performance dropped significantly when the game setup didn't match their particular biases.
Interestingly, the researchers found that even the most advanced LLM, GPT-4, was quite vulnerable to these biases. Simply making the model larger and more sophisticated didn't necessarily solve the problem of strategic reasoning.
The researchers did find that using a "chain-of-thought" prompting approach could reduce the impact of the biases for some models. But this wasn't a complete fix, and the fundamental limitations in the LLMs' strategic decision-making abilities remained.
Technical Explanation
The researchers investigated the strategic decision-making abilities of large language models (LLMs) using game theory as a framework. They tested the LLMs on two classic strategic games: the Stag Hunt and the Prisoner's Dilemma.
In these games, the payoffs for each player depend on the actions chosen by both players. The researchers analyzed the LLMs' performance in selecting the "correct" action - the one that aligns with the preferences of both players.
The results showed that the tested state-of-the-art LLMs, including GPT-4, exhibited at least one of three systematic biases:
- Positional bias: The LLMs showed a preference for choosing a particular position in the game, regardless of the payoffs.
- Payoff bias: The LLMs were overly focused on maximizing their own payoff rather than considering the overall outcome.
- Behavioral bias: The LLMs' choices were influenced by the specific prompts or instructions provided, rather than a deeper understanding of the strategic dynamics.
The researchers found that the LLMs' performance dropped significantly when the game configuration was misaligned with their particular biases. For example, GPT-4's average performance dropped by 34% when the game was misaligned with its biases.
Interestingly, the researchers observed that the trend of "bigger is better" did not hold in this context. The most advanced LLM, GPT-4, suffered the most substantial performance drop when the game setup was misaligned with its biases.
The researchers also explored the use of "chain-of-thought" prompting, which aims to encourage more deliberative reasoning. While this approach reduced the effect of the biases for some models, it did not solve the problem at a fundamental level.
Critical Analysis
The researchers provide valuable insights into the limitations of current large language models (LLMs) in strategic decision-making tasks. The systematic biases identified, such as positional bias, payoff bias, and behavioral bias, highlight the need for further advancements in the strategic reasoning capabilities of these models.
One key limitation of the study is the relatively narrow scope of the games tested - the Stag Hunt and Prisoner's Dilemma. While these are classic game theory problems, they may not fully capture the complexity of real-world strategic interactions. Expanding the research to a wider range of strategic games and decision-making scenarios would provide a more comprehensive understanding of LLM capabilities.
Additionally, the researchers note that the "chain-of-thought" prompting approach, while helpful in reducing the impact of biases, is not a complete solution. This suggests that fundamental improvements in the underlying architecture and training of LLMs may be necessary to address their strategic reasoning limitations.
It is also worth considering the potential implications of these findings beyond the academic context. As LLMs are increasingly deployed in real-world applications, their decision-making biases could have significant consequences, particularly in high-stakes scenarios. Addressing these biases and ensuring the reliable strategic decision-making of LLMs is crucial for their safe and responsible deployment.
Conclusion
This research paper provides important insights into the strategic decision-making abilities of large language models (LLMs). The identification of systematic biases, such as positional bias, payoff bias, and behavioral bias, highlights the need for further advancements in the strategic reasoning capabilities of these models.
The findings suggest that simply increasing the size and complexity of LLMs may not be sufficient to overcome these limitations. Fundamental improvements in the underlying architecture and training of these models, as well as the development of more robust strategic reasoning approaches, are likely necessary.
As LLMs continue to be applied in real-world settings, understanding and addressing their strategic decision-making biases will be crucial for ensuring their safe and responsible deployment. The insights provided in this research paper can serve as a valuable starting point for further exploration and refinement of strategic reasoning in large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Are Large Language Models Strategic Decision Makers? A Study of Performance and Bias in Two-Player Non-Zero-Sum Games
Nathan Herr, Fernando Acero, Roberta Raileanu, Mar'ia P'erez-Ortiz, Zhibin Li
Large Language Models (LLMs) have been increasingly used in real-world settings, yet their strategic abilities remain largely unexplored. Game theory provides a good framework for assessing the decision-making abilities of LLMs in interactions with other agents. Although prior studies have shown that LLMs can solve these tasks with carefully curated prompts, they fail when the problem setting or prompt changes. In this work we investigate LLMs' behaviour in strategic games, Stag Hunt and Prisoner Dilemma, analyzing performance variations under different settings and prompts. Our results show that the tested state-of-the-art LLMs exhibit at least one of the following systematic biases: (1) positional bias, (2) payoff bias, or (3) behavioural bias. Subsequently, we observed that the LLMs' performance drops when the game configuration is misaligned with the affecting biases. Performance is assessed based on the selection of the correct action, one which agrees with the prompted preferred behaviours of both players. Alignment refers to whether the LLM's bias aligns with the correct action. For example, GPT-4o's average performance drops by 34% when misaligned. Additionally, the current trend of bigger and newer is better does not hold for the above, where GPT-4o (the current best-performing LLM) suffers the most substantial performance drop. Lastly, we note that while chain-of-thought prompting does reduce the effect of the biases on most models, it is far from solving the problem at the fundamental level.
Read more7/17/2024
💬
0
Large Language Models Playing Mixed Strategy Nash Equilibrium Games
Alonso Silva
Generative artificial intelligence (Generative AI), and in particular Large Language Models (LLMs) have gained significant popularity among researchers and industrial communities, paving the way for integrating LLMs in different domains, such as robotics, telecom, and healthcare. In this paper, we study the intersection of game theory and generative artificial intelligence, focusing on the capabilities of LLMs to find the Nash equilibrium in games with a mixed strategy Nash equilibrium and no pure strategy Nash equilibrium (that we denote mixed strategy Nash equilibrium games). The study reveals a significant enhancement in the performance of LLMs when they are equipped with the possibility to run code and are provided with a specific prompt to incentivize them to do so. However, our research also highlights the limitations of LLMs when the randomization strategy of the game is not easy to deduce. It is evident that while LLMs exhibit remarkable proficiency in well-known standard games, their performance dwindles when faced with slight modifications of the same games. This paper aims to contribute to the growing body of knowledge on the intersection of game theory and generative artificial intelligence while providing valuable insights into LLMs strengths and weaknesses. It also underscores the need for further research to overcome the limitations of LLMs, particularly in dealing with even slightly more complex scenarios, to harness their full potential.
Read more6/18/2024
0
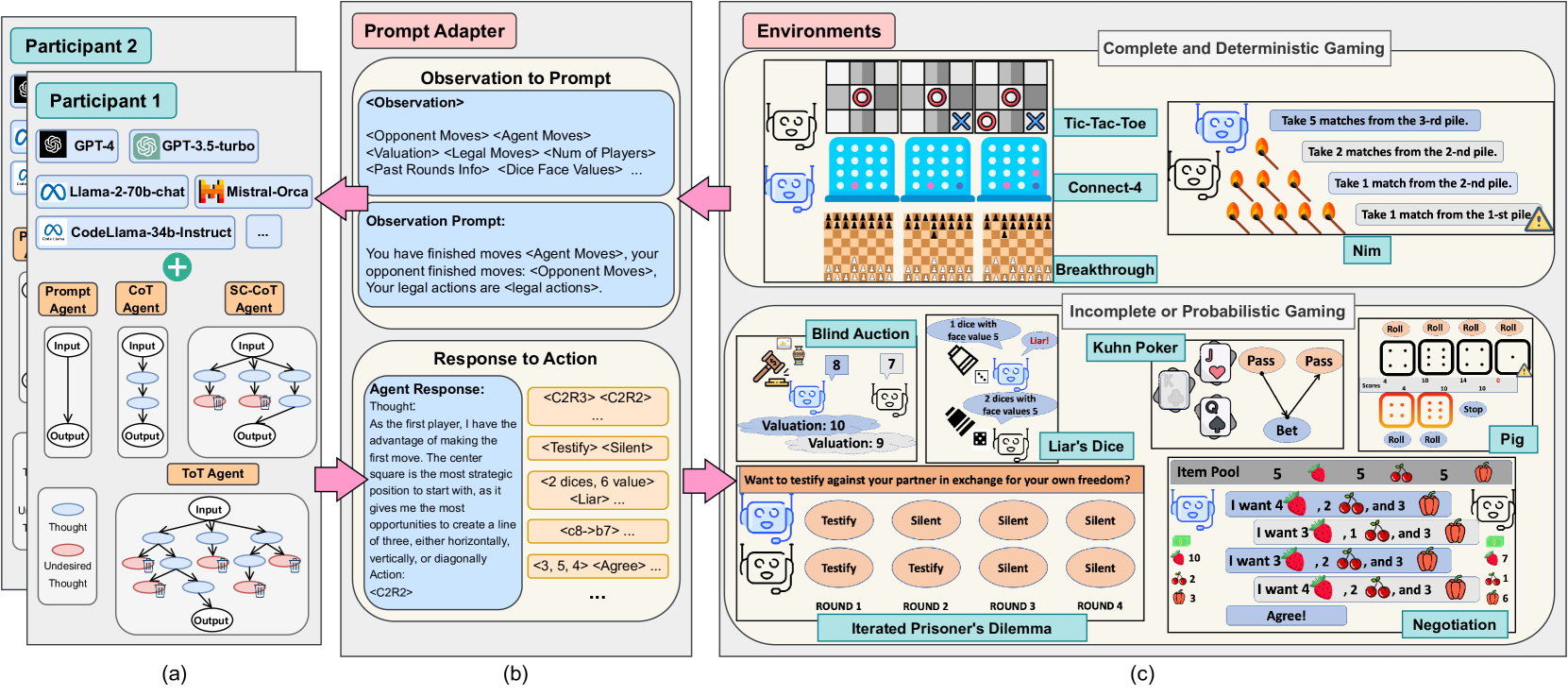
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
Read more6/11/2024
0
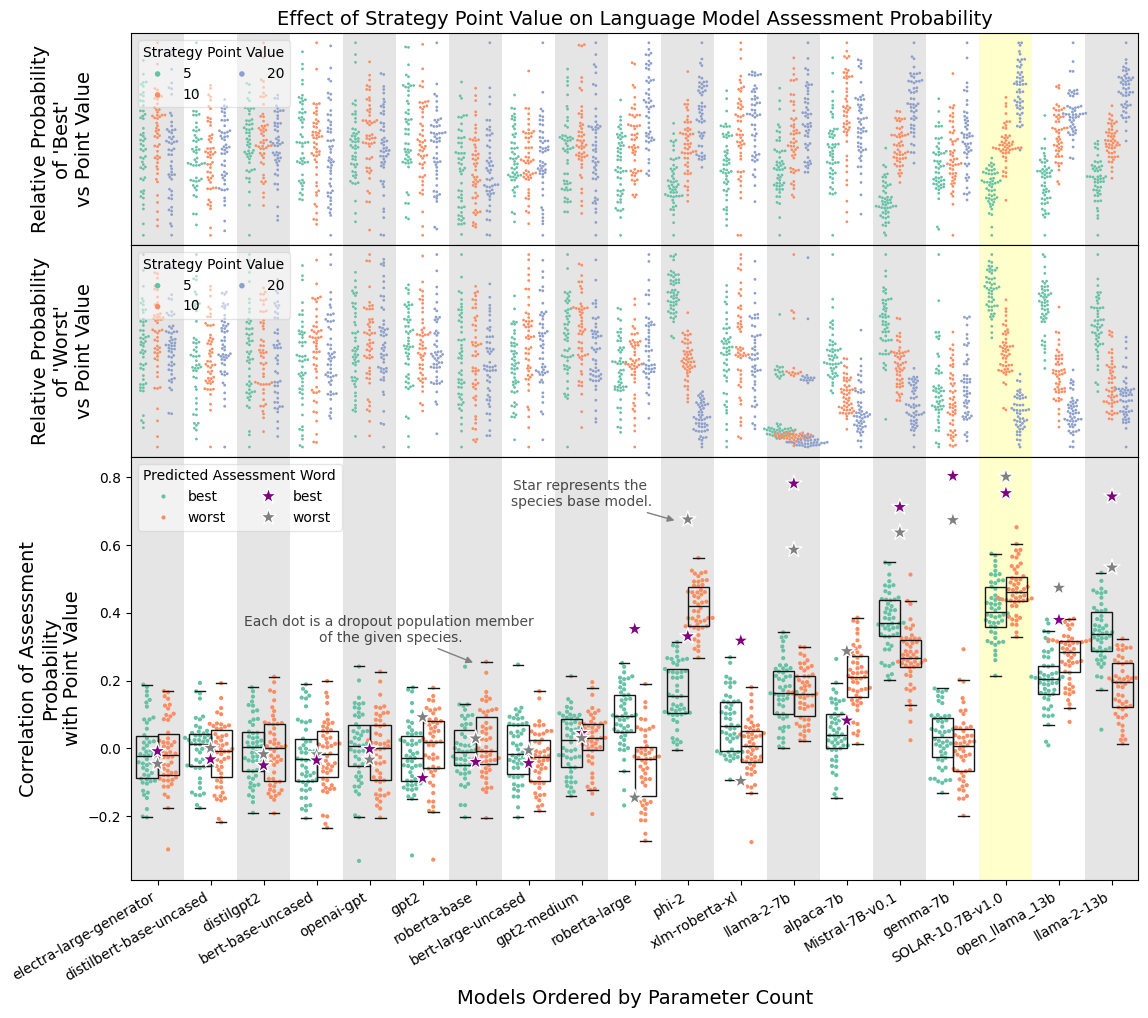
Do Large Language Models Learn Human-Like Strategic Preferences?
Jesse Roberts, Kyle Moore, Doug Fisher
We evaluate whether LLMs learn to make human-like preference judgements in strategic scenarios as compared with known empirical results. We show that Solar and Mistral exhibit stable value-based preference consistent with human in the prisoner's dilemma, including stake-size effect, and traveler's dilemma, including penalty-size effect. We establish a relationship between model size, value based preference, and superficiality. Finally, we find that models that tend to be less brittle were trained with sliding window attention. Additionally, we contribute a novel method for constructing preference relations from arbitrary LLMs and support for a hypothesis regarding human behavior in the traveler's dilemma.
Read more4/16/2024