Large Language Models Playing Mixed Strategy Nash Equilibrium Games

0
💬
Sign in to get full access
Overview
- This paper investigates how large language models (LLMs) can be used to play mixed strategy Nash equilibrium games, which are a type of game theory scenario.
- The researchers explore the ability of LLMs to understand and reason about strategic interactions, with a focus on the Matching Pennies game as a case study.
- The findings provide insights into the limitations of current LLMs in capturing the nuanced strategic thinking required for these types of games, and suggest directions for future research.
Plain English Explanation
This paper looks at how powerful AI language models, known as large language models (LLMs), can be used to play a specific type of game called a mixed strategy Nash equilibrium game. These games involve players making strategic decisions without knowing what their opponent will do.
The researchers focused on studying how well LLMs can understand and reason about these strategic interactions by having them play a classic game called Matching Pennies. In this game, two players each choose to show either "heads" or "tails" on a coin, and the winner is determined by whether the coins match or not.
The key finding is that current LLMs struggle to fully capture the nuanced strategic thinking required to play these types of games optimally. While the LLMs were able to learn to play the game to some degree, they fell short of the ideal "mixed strategy" approach where players randomly choose their moves to prevent their opponent from exploiting a pattern.
This research provides important insights into the limitations of existing LLMs when it comes to complex strategic reasoning. It suggests that more work is needed to develop AI systems that can truly engage in the type of strategic thinking that humans excel at in these game scenarios.
Technical Explanation
The paper investigates the ability of large language models (LLMs) to play mixed strategy Nash equilibrium games, which are a type of game theory scenario where players must reason about strategic interactions and make unpredictable choices to avoid exploitation by their opponent.
The researchers focused on the Matching Pennies game as a case study. In this game, two players each choose to reveal either "heads" or "tails" on a coin, and the player who matches the opponent's choice wins. The unique Nash equilibrium strategy for this game is for both players to randomly choose heads or tails with equal probability.
The researchers trained several LLM-based game agents to play the Matching Pennies game and evaluated their performance. They found that while the LLM agents were able to learn to play the game to some degree, they struggled to fully capture the nuanced strategic thinking required to converge on the mixed strategy Nash equilibrium.
The LLM agents tended to exhibit biases and patterns in their play that could be exploited by an opponent, rather than maintaining the truly random behavior needed to achieve the optimal mixed strategy. The researchers analyzed the internal representations and decision-making processes of the LLM agents to better understand the limitations.
The findings suggest that current LLMs have significant challenges in reasoning about the strategic interactions and unpredictable decision-making required for mixed strategy Nash equilibrium games. This highlights the need for further research to develop AI systems with more sophisticated strategic reasoning capabilities.
Critical Analysis
The research presented in this paper provides valuable insights into the limitations of current large language models (LLMs) when it comes to complex strategic reasoning and game-playing abilities. The focus on the Matching Pennies game as a case study is well-chosen, as it represents a fundamental type of game theory scenario that requires nuanced strategic thinking.
One key limitation of the study is that it only examines a single game type, the Matching Pennies game. While this provides a useful starting point, it would be informative to see how the LLM agents perform on a broader range of game types, including games with more complex payoff structures or multiple Nash equilibria. [See related work on this topic, such as the papers on GTBench, how far LLMs are from optimal decision-making, and cooperation and competition in LLM-based agents.]
Additionally, the paper does not delve deeply into the specific mechanisms or architectural choices that may be limiting the LLMs' strategic reasoning capabilities. Further analysis of the internal representations and decision-making processes of the agents could provide more targeted insights to guide future research in this area. [See the broader survey of LLM-based game agents for more context.]
It would also be valuable to explore whether the limitations observed in this study are inherent to the current state of LLM technology or if they could be addressed through modifications to the training process or architecture. [The paper on LLMs and optimization may provide relevant insights on this front.]
Overall, this paper makes a valuable contribution to the growing body of research on the strategic reasoning capabilities of large language models. While the findings highlight significant challenges, they also suggest promising avenues for future work to develop AI systems with more sophisticated game-playing and strategic decision-making abilities.
Conclusion
This paper investigates the ability of large language models (LLMs) to play mixed strategy Nash equilibrium games, using the Matching Pennies game as a case study. The key finding is that current LLMs struggle to fully capture the nuanced strategic thinking required to converge on the optimal mixed strategy in these types of games.
The research provides important insights into the limitations of existing LLMs when it comes to complex strategic reasoning and decision-making. It suggests that more work is needed to develop AI systems that can truly engage in the type of unpredictable, strategic thinking that humans excel at in game theory scenarios.
The findings of this paper have broader implications for the development of AI systems that can effectively reason about and participate in strategic interactions, whether in game-playing, negotiation, or other real-world applications. Continued research in this area is crucial to advancing the state of the art in AI and its ability to handle the complexities of human decision-making and strategic behavior.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Large Language Models Playing Mixed Strategy Nash Equilibrium Games
Alonso Silva
Generative artificial intelligence (Generative AI), and in particular Large Language Models (LLMs) have gained significant popularity among researchers and industrial communities, paving the way for integrating LLMs in different domains, such as robotics, telecom, and healthcare. In this paper, we study the intersection of game theory and generative artificial intelligence, focusing on the capabilities of LLMs to find the Nash equilibrium in games with a mixed strategy Nash equilibrium and no pure strategy Nash equilibrium (that we denote mixed strategy Nash equilibrium games). The study reveals a significant enhancement in the performance of LLMs when they are equipped with the possibility to run code and are provided with a specific prompt to incentivize them to do so. However, our research also highlights the limitations of LLMs when the randomization strategy of the game is not easy to deduce. It is evident that while LLMs exhibit remarkable proficiency in well-known standard games, their performance dwindles when faced with slight modifications of the same games. This paper aims to contribute to the growing body of knowledge on the intersection of game theory and generative artificial intelligence while providing valuable insights into LLMs strengths and weaknesses. It also underscores the need for further research to overcome the limitations of LLMs, particularly in dealing with even slightly more complex scenarios, to harness their full potential.
Read more6/18/2024
💬
0
Are Large Language Models Strategic Decision Makers? A Study of Performance and Bias in Two-Player Non-Zero-Sum Games
Nathan Herr, Fernando Acero, Roberta Raileanu, Mar'ia P'erez-Ortiz, Zhibin Li
Large Language Models (LLMs) have been increasingly used in real-world settings, yet their strategic abilities remain largely unexplored. Game theory provides a good framework for assessing the decision-making abilities of LLMs in interactions with other agents. Although prior studies have shown that LLMs can solve these tasks with carefully curated prompts, they fail when the problem setting or prompt changes. In this work we investigate LLMs' behaviour in strategic games, Stag Hunt and Prisoner Dilemma, analyzing performance variations under different settings and prompts. Our results show that the tested state-of-the-art LLMs exhibit at least one of the following systematic biases: (1) positional bias, (2) payoff bias, or (3) behavioural bias. Subsequently, we observed that the LLMs' performance drops when the game configuration is misaligned with the affecting biases. Performance is assessed based on the selection of the correct action, one which agrees with the prompted preferred behaviours of both players. Alignment refers to whether the LLM's bias aligns with the correct action. For example, GPT-4o's average performance drops by 34% when misaligned. Additionally, the current trend of bigger and newer is better does not hold for the above, where GPT-4o (the current best-performing LLM) suffers the most substantial performance drop. Lastly, we note that while chain-of-thought prompting does reduce the effect of the biases on most models, it is far from solving the problem at the fundamental level.
Read more7/17/2024

2
Large Language Models and Games: A Survey and Roadmap
Roberto Gallotta, Graham Todd, Marvin Zammit, Sam Earle, Antonios Liapis, Julian Togelius, Georgios N. Yannakakis
Recent years have seen an explosive increase in research on large language models (LLMs), and accompanying public engagement on the topic. While starting as a niche area within natural language processing, LLMs have shown remarkable potential across a broad range of applications and domains, including games. This paper surveys the current state of the art across the various applications of LLMs in and for games, and identifies the different roles LLMs can take within a game. Importantly, we discuss underexplored areas and promising directions for future uses of LLMs in games and we reconcile the potential and limitations of LLMs within the games domain. As the first comprehensive survey and roadmap at the intersection of LLMs and games, we are hopeful that this paper will serve as the basis for groundbreaking research and innovation in this exciting new field.
Read more9/16/2024
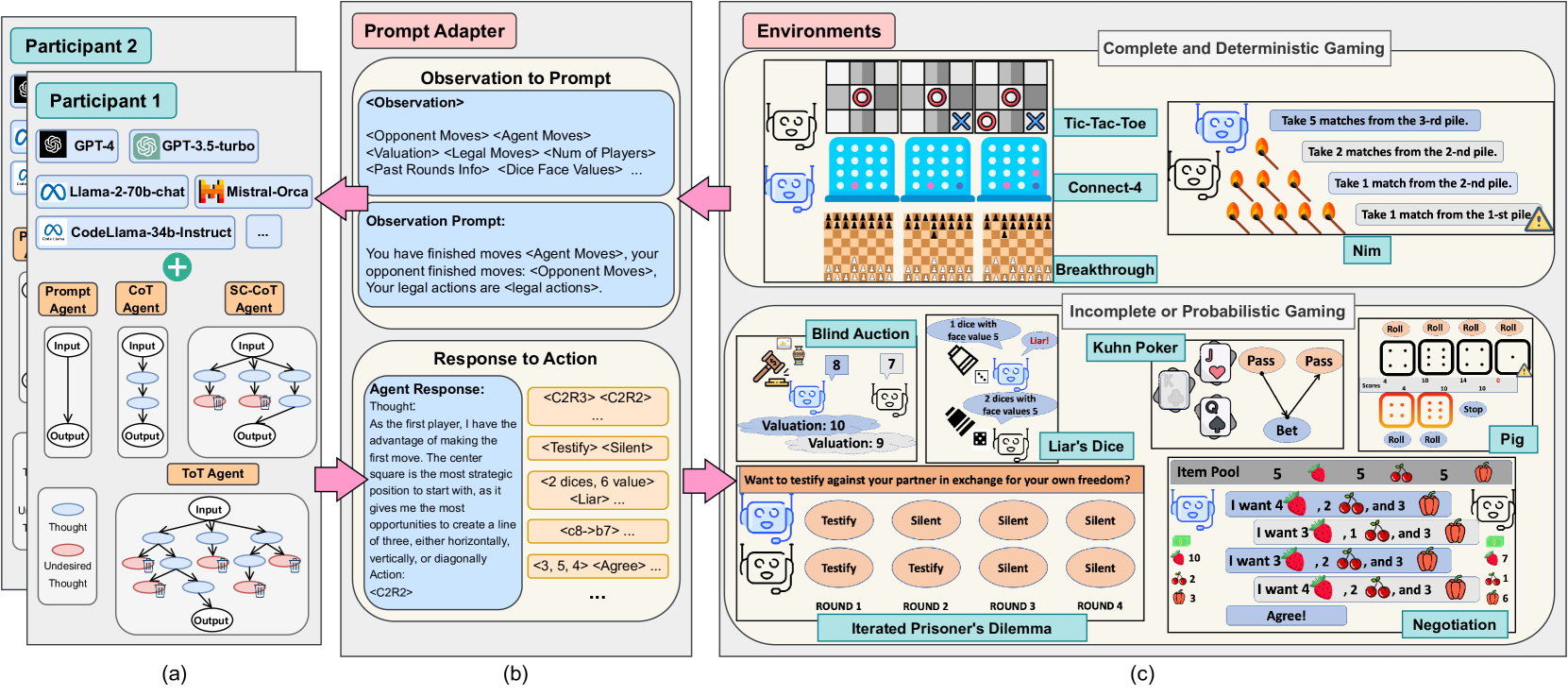
0
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
Read more6/11/2024