Are we making progress in unlearning? Findings from the first NeurIPS unlearning competition

0
Sign in to get full access
Overview
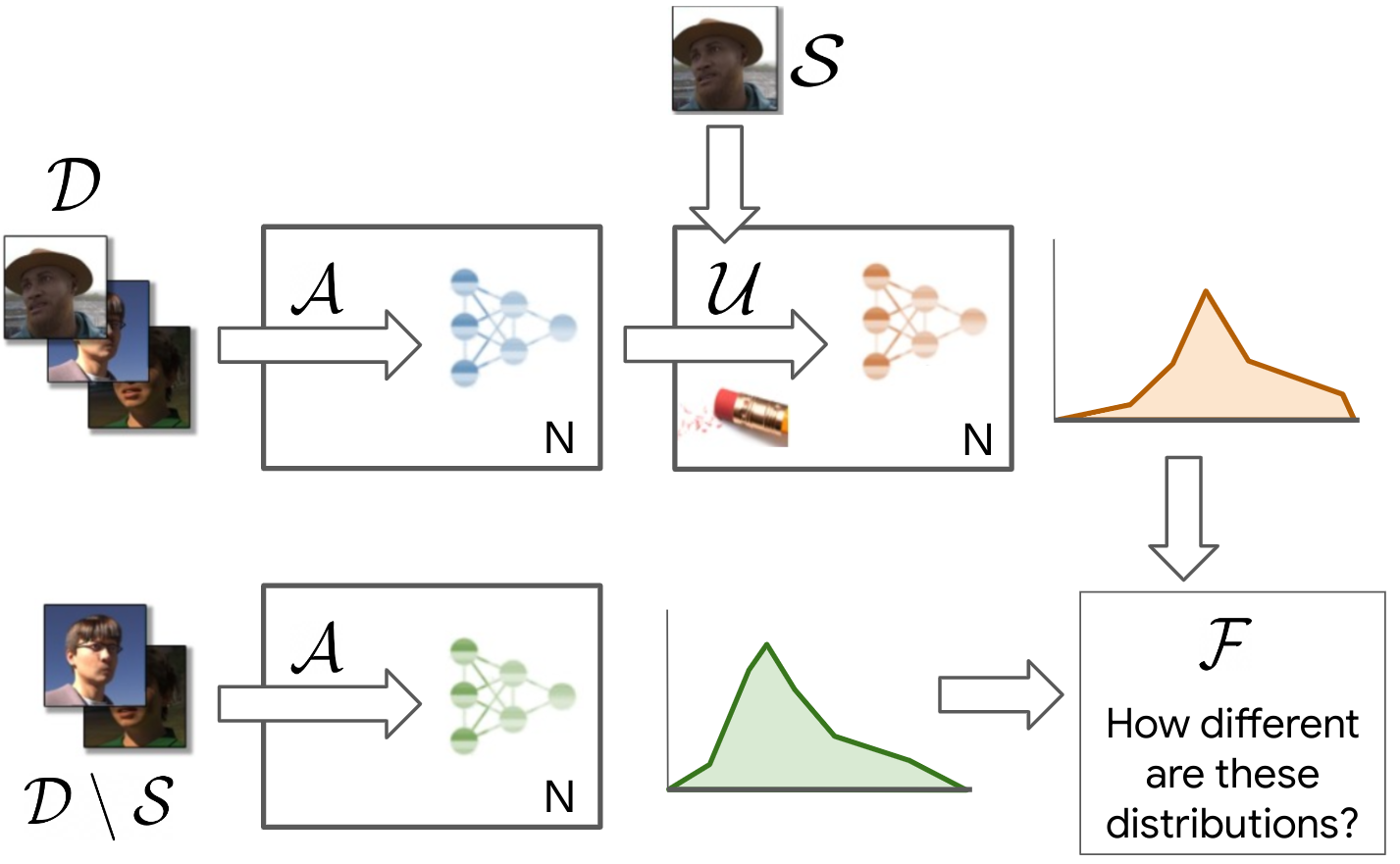
- This paper presents findings from the first NeurIPS competition on machine unlearning, which aims to develop techniques to remove unwanted information from AI models without retraining from scratch.
- The authors analyze the submissions to the competition and discuss the current state of progress in this emerging field, highlighting key insights and challenges.
- The paper provides a comprehensive overview of the competition and its implications for the broader machine unlearning research community.
Plain English Explanation
Machine learning models can sometimes learn and retain information that we don't want them to have, such as sensitive personal data or biases. Machine unlearning is the process of removing this unwanted information from a trained model without having to retrain it from the beginning.
The authors of this paper organized the first NeurIPS competition on machine unlearning, challenging researchers to develop techniques that can effectively "unlearn" information. By analyzing the submissions to this competition, the authors provide insights into the current state of progress in this emerging field.
The paper covers key findings, such as the types of unlearning methods used by participants, the performance of these methods on different tasks, and the challenges that still need to be addressed. For example, the authors found that while some progress has been made, reliably evaluating unlearning is still a significant challenge.
Overall, this paper offers a comprehensive look at the state of machine unlearning research, highlighting both the advancements and the remaining obstacles that need to be overcome. By understanding the current landscape, researchers can better identify the factors that make unlearning difficult and work towards developing more robust and reliable unlearning techniques.
Technical Explanation
The paper presents an analysis of the submissions to the first NeurIPS competition on machine unlearning. Machine unlearning is the process of removing unwanted information from a trained machine learning model without having to retrain the model from scratch.
The competition challenged researchers to develop techniques that can effectively unlearn specific information from a model, such as sensitive personal data or biases. The authors analyze the submissions to the competition, examining the different unlearning methods employed, their performance on various tasks, and the key insights and challenges that emerged.
One of the key findings is that while some progress has been made, reliably evaluating unlearning is still a significant challenge. The authors also identify factors that can make unlearning difficult, such as the nature of the information to be unlearned and the structure of the underlying model.
The paper provides a comprehensive overview of the current state of machine unlearning research, highlighting both the advancements and the remaining obstacles that need to be addressed. The authors discuss the implications of their findings for the broader research community and suggest directions for future work, such as developing more robust and reliable unlearning techniques.
Critical Analysis
The paper provides a valuable contribution to the field of machine unlearning by analyzing the submissions to the first NeurIPS competition on this topic. The authors present a thorough overview of the current state of research and identify several key challenges that need to be addressed.
One of the main strengths of the paper is its comprehensive and objective analysis of the competition submissions. The authors clearly outline the different unlearning methods used by participants and their performance on various tasks, allowing readers to gain a comprehensive understanding of the current landscape.
However, the paper also acknowledges the significant challenges in reliably evaluating unlearning, which is a crucial aspect of this field. Developing robust and reliable evaluation methods will be essential for driving further progress in machine unlearning.
Additionally, the paper could have delved deeper into the potential limitations and drawbacks of the unlearning techniques presented, as well as the broader implications and societal impacts of this research. Exploring these aspects more thoroughly could have provided a more well-rounded critical analysis.
Overall, this paper serves as an important milestone in the machine unlearning research community, offering valuable insights and laying the groundwork for future advancements in this emerging field.
Conclusion
This paper presents the findings from the first NeurIPS competition on machine unlearning, a field focused on developing techniques to remove unwanted information from AI models without retraining from scratch. The authors provide a comprehensive analysis of the competition submissions, highlighting the current state of progress, key insights, and the remaining challenges.
The paper offers a valuable contribution to the machine unlearning research community, providing a clear picture of the latest developments and the factors that can make unlearning difficult. By identifying the challenges in reliably evaluating unlearning, the authors pave the way for future work to address this critical issue.
As machine learning models become increasingly sophisticated and ubiquitous, the ability to effectively unlearn unwanted information will only grow in importance. This paper serves as an important step towards developing more robust and reliable unlearning techniques that can have a meaningful impact on the responsible development and deployment of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are we making progress in unlearning? Findings from the first NeurIPS unlearning competition
Eleni Triantafillou, Peter Kairouz, Fabian Pedregosa, Jamie Hayes, Meghdad Kurmanji, Kairan Zhao, Vincent Dumoulin, Julio Jacques Junior, Ioannis Mitliagkas, Jun Wan, Lisheng Sun Hosoya, Sergio Escalera, Gintare Karolina Dziugaite, Peter Triantafillou, Isabelle Guyon
We present the findings of the first NeurIPS competition on unlearning, which sought to stimulate the development of novel algorithms and initiate discussions on formal and robust evaluation methodologies. The competition was highly successful: nearly 1,200 teams from across the world participated, and a wealth of novel, imaginative solutions with different characteristics were contributed. In this paper, we analyze top solutions and delve into discussions on benchmarking unlearning, which itself is a research problem. The evaluation methodology we developed for the competition measures forgetting quality according to a formal notion of unlearning, while incorporating model utility for a holistic evaluation. We analyze the effectiveness of different instantiations of this evaluation framework vis-a-vis the associated compute cost, and discuss implications for standardizing evaluation. We find that the ranking of leading methods remains stable under several variations of this framework, pointing to avenues for reducing the cost of evaluation. Overall, our findings indicate progress in unlearning, with top-performing competition entries surpassing existing algorithms under our evaluation framework. We analyze trade-offs made by different algorithms and strengths or weaknesses in terms of generalizability to new datasets, paving the way for advancing both benchmarking and algorithm development in this important area.
Read more6/14/2024

0
Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
Read more5/30/2024

0
What makes unlearning hard and what to do about it
Kairan Zhao, Meghdad Kurmanji, George-Octavian Bu{a}rbulescu, Eleni Triantafillou, Peter Triantafillou
Machine unlearning is the problem of removing the effect of a subset of training data (the ''forget set'') from a trained model without damaging the model's utility e.g. to comply with users' requests to delete their data, or remove mislabeled, poisoned or otherwise problematic data. With unlearning research still being at its infancy, many fundamental open questions exist: Are there interpretable characteristics of forget sets that substantially affect the difficulty of the problem? How do these characteristics affect different state-of-the-art algorithms? With this paper, we present the first investigation aiming to answer these questions. We identify two key factors affecting unlearning difficulty and the performance of unlearning algorithms. Evaluation on forget sets that isolate these identified factors reveals previously-unknown behaviours of state-of-the-art algorithms that don't materialize on random forget sets. Based on our insights, we develop a framework coined Refined-Unlearning Meta-algorithm (RUM) that encompasses: (i) refining the forget set into homogenized subsets, according to different characteristics; and (ii) a meta-algorithm that employs existing algorithms to unlearn each subset and finally delivers a model that has unlearned the overall forget set. We find that RUM substantially improves top-performing unlearning algorithms. Overall, we view our work as an important step in (i) deepening our scientific understanding of unlearning and (ii) revealing new pathways to improving the state-of-the-art.
Read more6/4/2024
0
Towards Reliable Empirical Machine Unlearning Evaluation: A Game-Theoretic View
Yiwen Tu, Pingbang Hu, Jiaqi Ma
Machine unlearning is the process of updating machine learning models to remove the information of specific training data samples, in order to comply with data protection regulations that allow individuals to request the removal of their personal data. Despite the recent development of numerous unlearning algorithms, reliable evaluation of these algorithms remains an open research question. In this work, we focus on membership inference attack (MIA) based evaluation, one of the most common approaches for evaluating unlearning algorithms, and address various pitfalls of existing evaluation metrics that lack reliability. Specifically, we propose a game-theoretic framework that formalizes the evaluation process as a game between unlearning algorithms and MIA adversaries, measuring the data removal efficacy of unlearning algorithms by the capability of the MIA adversaries. Through careful design of the game, we demonstrate that the natural evaluation metric induced from the game enjoys provable guarantees that the existing evaluation metrics fail to satisfy. Furthermore, we propose a practical and efficient algorithm to estimate the evaluation metric induced from the game, and demonstrate its effectiveness through both theoretical analysis and empirical experiments. This work presents a novel and reliable approach to empirically evaluating unlearning algorithms, paving the way for the development of more effective unlearning techniques.
Read more6/13/2024