Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena

0

Sign in to get full access
Overview
- Proposes a simulated "chatbot arena" to continuously improve large language models (LLMs) after initial training
- Aims to build a "data flywheel" that generates diverse, high-quality training data through iterative chatbot interactions
- Leverages self-supervised learning and interactive evaluations to drive ongoing model improvements
Plain English Explanation
The paper presents a novel approach called "Arena Learning" to help large language models (LLMs) such as GPT-3 continuously improve themselves after their initial training. The key idea is to create a simulated "chatbot arena" where the LLM can engage in open-ended conversations with other AI chatbots.
Through these interactions, the LLM can learn to handle a wider range of topics and conversational styles, generating diverse new training data in the process. This creates a self-reinforcing "data flywheel" - the model improves, generates better training data, which in turn leads to further model improvements.
The researchers envision this arena-based approach as a way to automate the post-training refinement of LLMs, avoiding the need for costly manual data collection and curation. By continuously challenging the model with novel interactions, the arena can push the LLM to expand its capabilities over time.
Technical Explanation
The paper outlines a framework called "Arena Learning" that aims to drive ongoing improvements in large language models (LLMs) after their initial training. At the core of this approach is a simulated "chatbot arena" where the target LLM can engage in open-ended conversations with other AI chatbots.
Through these interactive evaluations, the LLM is exposed to a diverse range of conversational styles and topics. The model's responses are then analyzed to identify areas for improvement, and the insights are used to fine-tune the LLM's training. This creates a self-reinforcing loop, where the model generates new training data through its interactions, leading to performance gains that enable even richer conversations.
The researchers propose several techniques to facilitate this "data flywheel", including self-supervised learning to extract relevant training signals from the arena interactions, as well as automated methods for generating challenging conversational prompts and evaluating the model's outputs. By automating the post-training refinement process, the approach aims to reduce the need for costly manual data curation and model fine-tuning.
Critical Analysis
The "Arena Learning" framework proposed in the paper offers a promising approach to driving ongoing improvements in large language models (LLMs) after their initial training. By leveraging interactive evaluations in a simulated chatbot environment, the researchers aim to build a self-improving "data flywheel" that can continuously expand the model's capabilities.
One key strength of the approach is its potential to generate diverse, high-quality training data through the model's interactions in the arena. This could help address the challenge of data scarcity that often limits the post-training refinement of LLMs. The integration of self-supervised learning techniques also seems well-aligned with the goal of extracting relevant training signals from the arena interactions.
However, the paper does not delve deeply into some of the potential challenges and limitations of the proposed framework. For example, it remains to be seen how the arena's prompts and conversational agents can be designed to reliably identify areas for model improvement, without introducing unintended biases or instabilities. The scalability of the approach to large-scale, open-ended interactions also warrants further investigation.
Additionally, the ethical implications of an automated system continuously refining and expanding the capabilities of powerful language models deserve careful consideration. Issues around model alignment, safety, and transparency would need to be addressed to ensure the "Arena Learning" framework is developed and deployed responsibly.
Conclusion
The "Arena Learning" framework presented in this paper offers a novel and ambitious approach to driving ongoing improvements in large language models (LLMs) after their initial training. By creating a simulated chatbot environment where the target LLM can engage in diverse interactions, the researchers aim to build a self-reinforcing "data flywheel" that continuously expands the model's capabilities.
This concept of using interactive evaluations to generate high-quality training data and spur model refinement is intriguing and could help address some of the key challenges in post-training LLM development. However, the paper also highlights the need to carefully consider the potential limitations and ethical implications of such an automated system for LLM improvement.
Overall, the "Arena Learning" framework represents an interesting direction for future research, with the potential to drive significant advances in large language models and their real-world applications. As the field of AI continues to evolve, innovative approaches like this will be crucial for unlocking the full potential of these powerful technologies while prioritizing safety, transparency, and responsible development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Qingwei Lin, Jianguang Lou, Shifeng Chen, Yansong Tang, Weizhu Chen
Assessing the effectiveness of large language models (LLMs) presents substantial challenges. The method of conducting human-annotated battles in an online Chatbot Arena is a highly effective evaluative technique. However, this approach is limited by the costs and time required for human annotation. In this paper, we introduce Arena Learning, an innovative offline strategy designed to simulate these arena battles using AI-driven annotations to evaluate battle outcomes, thus facilitating the continuous improvement of the target model through both supervised fine-tuning and reinforcement learning. Arena Learning comprises two key elements. First, it ensures precise evaluations and maintains consistency between offline simulations and online competitions via WizardArena, a pipeline developed to accurately predict the Elo rankings of various models using a meticulously designed offline test set. Our results demonstrate that WizardArena's predictions closely align with those from the online Arena. Second, it involves the continuous improvement of training data based on the battle results and the refined model. We establish a data flywheel to iteratively update the training data by highlighting the weaknesses of the target model based on its battle results, enabling it to learn from the strengths of multiple different models. We apply Arena Learning to train our target model, WizardLM-$beta$, and demonstrate significant performance enhancements across various metrics. This fully automated training and evaluation pipeline sets the stage for continuous advancements in various LLMs via post-training. Notably, Arena Learning plays a pivotal role in the success of WizardLM-2, and this paper serves both as an exploration of its efficacy and a foundational study for future discussions related to WizardLM-2 and its derivatives.
Read more7/16/2024
0
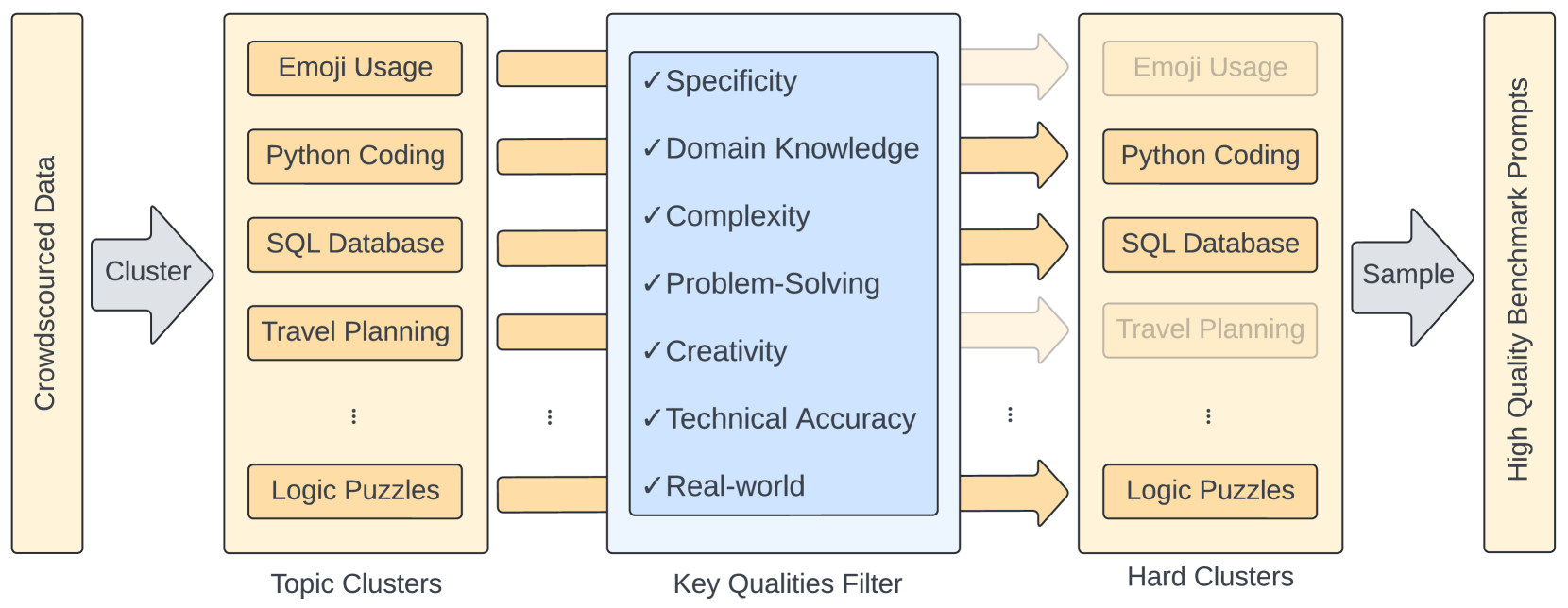
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, Ion Stoica
The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.
Read more6/19/2024

0
Auto Arena of LLMs: Automating LLM Evaluations with Agent Peer-battles and Committee Discussions
Ruochen Zhao, Wenxuan Zhang, Yew Ken Chia, Deli Zhao, Lidong Bing
As LLMs evolve on a daily basis, there is an urgent need for a trustworthy evaluation method that can provide robust evaluation results in a timely fashion. Currently, as static benchmarks are prone to contamination concerns, users tend to trust human voting platforms, such as Chatbot Arena. However, human annotations require extensive manual efforts. To provide an automatic, robust, and trustworthy evaluation framework, we innovatively propose the Auto-Arena of LLMs, which automates the entire evaluation process with LLM agents. Firstly, an examiner LLM devises queries. Then, a pair of candidate LLMs engage in a multi-round peer-battle around the query, during which the LLM's true performance gaps become visible. Finally, a committee of LLM judges collectively discuss and determine the winner, which alleviates bias and promotes fairness. In our extensive experiment on the 17 newest LLMs, Auto-Arena shows the highest correlation with human preferences, providing a promising alternative to human evaluation platforms.
Read more6/13/2024
📶
0
Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena
Jiangjie Chen, Siyu Yuan, Rong Ye, Bodhisattwa Prasad Majumder, Kyle Richardson
Recent advancements in Large Language Models (LLMs) showcase advanced reasoning, yet NLP evaluations often depend on static benchmarks. Evaluating this necessitates environments that test strategic reasoning in dynamic, competitive scenarios requiring long-term planning. We introduce AucArena, a novel evaluation suite that simulates auctions, a setting chosen for being highly unpredictable and involving many skills related to resource and risk management, while also being easy to evaluate. We conduct controlled experiments using state-of-the-art LLMs to power bidding agents to benchmark their planning and execution skills. Our research demonstrates that LLMs, such as GPT-4, possess key skills for auction participation, such as budget management and goal adherence, which improve with adaptive strategies. This highlights LLMs' potential in modeling complex social interactions in competitive contexts. However, variability in LLM performance and occasional outperformance by simpler methods indicate opportunities for further advancements in LLM design and the value of our simulation environment for ongoing testing and refinement.
Read more8/27/2024