From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
2406.11939
0
0
Abstract
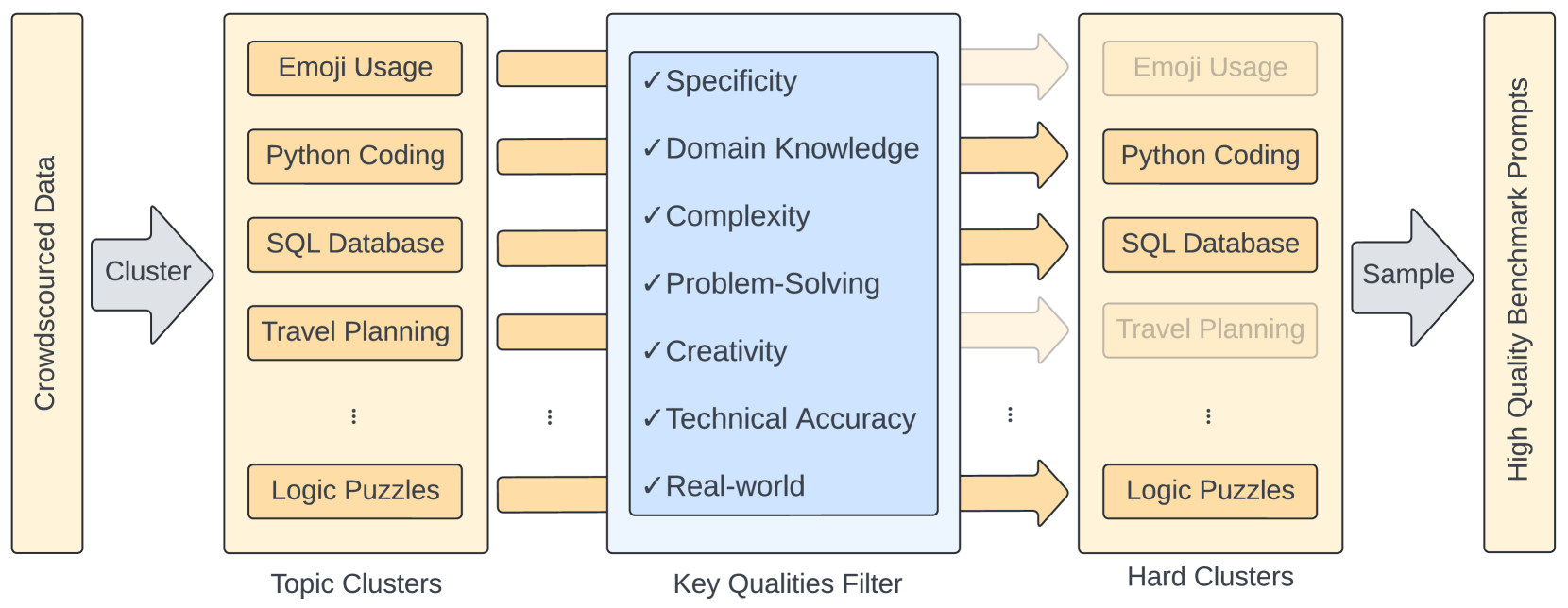
The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.
Create account to get full access
Overview
- This paper introduces two new benchmarks for evaluating large language models (LLMs) on challenging tasks: Arena-Hard and the BenchBuilder pipeline.
- Arena-Hard is a collection of 10 high-quality tasks that represent real-world challenges for LLMs, such as open-ended question answering, common sense reasoning, and dialogue generation.
- The BenchBuilder pipeline is a systematic process for creating high-quality benchmarks from crowdsourced data, ensuring the tasks are diverse, difficult, and well-defined.
Plain English Explanation
The researchers wanted to create benchmark tests that could really put large language models (LLMs) through their paces. The typical benchmarks used to evaluate these models often don't capture the full complexity of real-world tasks that humans can handle with ease.
So the researchers developed Arena-Hard, a collection of 10 challenging tasks that represent common challenges LLMs face, like answering open-ended questions, reasoning about common sense, and engaging in natural dialogue. These tasks are designed to be much harder than typical benchmarks, forcing the models to truly demonstrate their capabilities.
To create Arena-Hard, the researchers used a novel process called the BenchBuilder pipeline. This system takes crowdsourced data and refines it into high-quality, well-defined benchmark tasks. The goal is to ensure the benchmarks are diverse, difficult, and accurately measure a model's performance on real-world challenges.
By developing Arena-Hard and the BenchBuilder pipeline, the researchers hope to push the boundaries of LLM evaluation and drive progress in the field. These tools can help researchers and developers better understand the strengths and limitations of their models, ultimately leading to more capable and reliable AI systems.
Technical Explanation
The paper introduces two key contributions: the Arena-Hard benchmark and the BenchBuilder pipeline.
Arena-Hard is a collection of 10 challenging tasks designed to evaluate the capabilities of large language models (LLMs) on real-world problems. The tasks cover a range of domains, including open-ended question answering, commonsense reasoning, dialogue generation, and more. The researchers carefully curated these tasks to be significantly more difficult than typical LLM benchmarks, pushing the models to their limits.
To create Arena-Hard, the researchers developed the BenchBuilder pipeline, a systematic process for transforming crowdsourced data into high-quality, well-defined benchmark tasks. This pipeline involves several key steps:
- Data Collection: The researchers collect a diverse set of crowdsourced data, such as open-ended questions, reasoning problems, and dialogue snippets.
- Data Curation: The collected data is carefully reviewed and filtered to ensure it meets certain quality criteria, such as being well-defined, challenging, and representative of real-world problems.
- Task Formulation: The curated data is used to define specific benchmark tasks, with clear input formats, output specifications, and scoring criteria.
- Validation: The benchmark tasks are validated through human evaluation to ensure they are diverse, difficult, and accurately measure the targeted capabilities of LLMs.
By using the BenchBuilder pipeline, the researchers were able to create Arena-Hard, a benchmark that provides a more comprehensive and challenging assessment of LLM performance compared to existing benchmarks.
Critical Analysis
The Arena-Hard benchmark and the BenchBuilder pipeline represent a significant advancement in the field of LLM evaluation. By focusing on challenging, real-world tasks, the researchers are addressing a key limitation of existing benchmarks, which often fail to capture the true capabilities and limitations of these models.
However, the paper does acknowledge some potential limitations of its approach. For example, the researchers note that the tasks in Arena-Hard may not be representative of all the challenges LLMs face in real-world deployment, and that the benchmark may not be suitable for evaluating certain specialized or domain-specific models.
Additionally, the paper does not provide a detailed analysis of the performance of various LLMs on the Arena-Hard benchmark. This makes it difficult to assess the true impact and usefulness of the benchmark for the research community.
Further research could explore the application of the BenchBuilder pipeline to other domains and the development of even more challenging benchmarks that push the boundaries of LLM capabilities. Additionally, a more comprehensive evaluation of LLM performance on Arena-Hard could provide valuable insights into the strengths and weaknesses of these models.
Conclusion
The Arena-Hard benchmark and the BenchBuilder pipeline introduced in this paper represent a significant advancement in the field of LLM evaluation. By creating a more challenging and realistic set of benchmark tasks, the researchers are helping to drive progress in the development of more capable and reliable AI systems.
The BenchBuilder pipeline, in particular, demonstrates a systematic approach to transforming crowdsourced data into high-quality benchmarks, which could be applied to a wide range of AI domains beyond just language models. As the field of AI continues to evolve, tools like Arena-Hard and BenchBuilder will become increasingly important for ensuring that AI systems can truly meet the demands of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, Yejin Choi
0
0
We introduce WildBench, an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries. WildBench consists of 1,024 tasks carefully selected from over one million human-chatbot conversation logs. For automated evaluation with WildBench, we have developed two metrics, WB-Reward and WB-Score, which are computable using advanced LLMs such as GPT-4-turbo. WildBench evaluation uses task-specific checklists to evaluate model outputs systematically and provides structured explanations that justify the scores and comparisons, resulting in more reliable and interpretable automatic judgments. WB-Reward employs fine-grained pairwise comparisons between model responses, generating five potential outcomes: much better, slightly better, slightly worse, much worse, or a tie. Unlike previous evaluations that employed a single baseline model, we selected three baseline models at varying performance levels to ensure a comprehensive pairwise evaluation. Additionally, we propose a simple method to mitigate length bias, by converting outcomes of ``slightly better/worse'' to ``tie'' if the winner response exceeds the loser one by more than $K$ characters. WB-Score evaluates the quality of model outputs individually, making it a fast and cost-efficient evaluation metric. WildBench results demonstrate a strong correlation with the human-voted Elo ratings from Chatbot Arena on hard tasks. Specifically, WB-Reward achieves a Pearson correlation of 0.98 with top-ranking models. Additionally, WB-Score reaches 0.95, surpassing both ArenaHard's 0.91 and AlpacaEval2.0's 0.89 for length-controlled win rates, as well as the 0.87 for regular win rates.
6/10/2024
💬
Evaluating Large Language Models with Human Feedback: Establishing a Swedish Benchmark
Birger Moell
0
0
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have demonstrated significant capabilities across numerous applications. However, the performance of these models in languages with fewer resources, such as Swedish, remains under-explored. This study introduces a comprehensive human benchmark to assess the efficacy of prominent LLMs in understanding and generating Swedish language texts using forced choice ranking. We employ a modified version of the ChatbotArena benchmark, incorporating human feedback to evaluate eleven different models, including GPT-4, GPT-3.5, various Claude and Llama models, and bespoke models like Dolphin-2.9-llama3b-8b-flashback and BeagleCatMunin. These models were chosen based on their performance on LMSYS chatbot arena and the Scandeval benchmarks. We release the chatbotarena.se benchmark as a tool to improve our understanding of language model performance in Swedish with the hopes that it will be widely used. We aim to create a leaderboard once sufficient data has been collected and analysed.
5/24/2024
🌐
LiveBench: A Challenging, Contamination-Free LLM Benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, Micah Goldblum
0
0
Test set contamination, wherein test data from a benchmark ends up in a newer model's training set, is a well-documented obstacle for fair LLM evaluation and can quickly render benchmarks obsolete. To mitigate this, many recent benchmarks crowdsource new prompts and evaluations from human or LLM judges; however, these can introduce significant biases, and break down when scoring hard questions. In this work, we introduce a new benchmark for LLMs designed to be immune to both test set contamination and the pitfalls of LLM judging and human crowdsourcing. We release LiveBench, the first benchmark that (1) contains frequently-updated questions from recent information sources, (2) scores answers automatically according to objective ground-truth values, and (3) contains a wide variety of challenging tasks, spanning math, coding, reasoning, language, instruction following, and data analysis. To achieve this, LiveBench contains questions that are based on recently-released math competitions, arXiv papers, news articles, and datasets, and it contains harder, contamination-free versions of tasks from previous benchmarks such as Big-Bench Hard, AMPS, and IFEval. We evaluate many prominent closed-source models, as well as dozens of open-source models ranging from 0.5B to 110B in size. LiveBench is difficult, with top models achieving below 65% accuracy. We release all questions, code, and model answers. Questions will be added and updated on a monthly basis, and we will release new tasks and harder versions of tasks over time so that LiveBench can distinguish between the capabilities of LLMs as they improve in the future. We welcome community engagement and collaboration for expanding the benchmark tasks and models.
6/28/2024

Evaluating Large Vision-Language Models' Understanding of Real-World Complexities Through Synthetic Benchmarks
Haokun Zhou, Yipeng Hong
0
0
This study assesses the ability of Large Vision-Language Models (LVLMs) to differentiate between AI-generated and human-generated images. It introduces a new automated benchmark construction method for this evaluation. The experiment compared common LVLMs with human participants using a mixed dataset of AI and human-created images. Results showed that LVLMs could distinguish between the image types to some extent but exhibited a rightward bias, and perform significantly worse compared to humans. To build on these findings, we developed an automated benchmark construction process using AI. This process involved topic retrieval, narrative script generation, error embedding, and image generation, creating a diverse set of text-image pairs with intentional errors. We validated our method through constructing two caparable benchmarks. This study highlights the strengths and weaknesses of LVLMs in real-world understanding and advances benchmark construction techniques, providing a scalable and automatic approach for AI model evaluation.
6/14/2024