Argumentative Large Language Models for Explainable and Contestable Decision-Making
2405.02079
0
0
💬
Abstract
The diversity of knowledge encoded in large language models (LLMs) and their ability to apply this knowledge zero-shot in a range of settings makes them a promising candidate for use in decision-making. However, they are currently limited by their inability to reliably provide outputs which are explainable and contestable. In this paper, we attempt to reconcile these strengths and weaknesses by introducing a method for supplementing LLMs with argumentative reasoning. Concretely, we introduce argumentative LLMs, a method utilising LLMs to construct argumentation frameworks, which then serve as the basis for formal reasoning in decision-making. The interpretable nature of these argumentation frameworks and formal reasoning means that any decision made by the supplemented LLM may be naturally explained to, and contested by, humans. We demonstrate the effectiveness of argumentative LLMs experimentally in the decision-making task of claim verification. We obtain results that are competitive with, and in some cases surpass, comparable state-of-the-art techniques.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have diverse knowledge and can apply it in various settings, making them promising for decision-making.
- However, they currently struggle to provide explainable and contestable outputs.
- This paper introduces a method to supplement LLMs with argumentative reasoning, creating "argumentative LLMs."
- Argumentative LLMs use LLMs to construct interpretable argumentation frameworks, enabling formal reasoning and explainable decision-making.
Plain English Explanation
Large language models (LLMs) are powerful AI systems trained on vast amounts of text data. They have developed a diverse understanding of the world, which they can apply to a wide range of tasks, from answering questions to generating text. This makes them a promising technology for assisting with decision-making.
However, the outputs of LLMs can be difficult for humans to understand and evaluate. It's not always clear how an LLM arrived at a particular conclusion or decision. This lack of explainability and the ability for humans to contest the LLM's reasoning is a significant limitation.
To address this, the researchers in this paper developed a new approach called "argumentative LLMs." The key idea is to use the LLM to construct a structured framework of arguments, which can then be used as the basis for formal reasoning and decision-making. This approach helps make the LLM's decision-making process more interpretable and open to scrutiny by humans.
In other words, argumentative LLMs don't just give you an answer - they also explain the reasoning behind that answer in a way that you can understand and challenge if needed. This could be very useful in high-stakes decision-making scenarios, where it's important to be able to justify the decisions being made.
Technical Explanation
The researchers introduce a method for supplementing large language models (LLMs) with argumentative reasoning, creating "argumentative LLMs." This approach involves using LLMs to construct interpretable argumentation frameworks, which then serve as the basis for formal reasoning in decision-making tasks.
Specifically, the argumentative LLM first uses the LLM to identify relevant arguments and counterarguments for a given decision-making scenario. It then structures these arguments into a formal argumentation framework, which captures the logical relationships between the different claims.
This argumentative framework can then be used to reason about the decision in a more transparent and explainable way. The researchers demonstrate the effectiveness of this approach in the decision-making task of claim verification, where argumentative LLMs achieve results competitive with or surpassing state-of-the-art techniques.
The interpretable nature of the argumentation frameworks and the formal reasoning process means that any decisions made by the argumentative LLM can be clearly explained to and contested by human users. This addresses a key limitation of current LLMs, which often struggle to provide explainable and contestable outputs.
Critical Analysis
The researchers acknowledge that their proposed argumentative LLM approach is a step towards reconciling the strengths and weaknesses of large language models in decision-making. By supplementing LLMs with structured argumentation, they are able to improve the explainability and contestability of the models' outputs.
However, the paper also notes that there are still some limitations to this approach. The construction of the argumentation frameworks relies on the LLM's ability to accurately identify and relate relevant arguments, which may not always be perfect. There is also the question of how to best present the argumentative reasoning to human users in a clear and intuitive way.
Additionally, the experiments in the paper are focused on a specific decision-making task (claim verification), and it remains to be seen how well the argumentative LLM approach would generalize to a wider range of decision-making scenarios. Further research and testing would be needed to fully evaluate the capabilities and limitations of this approach.
Overall, the introduction of argumentative LLMs represents an interesting and promising step towards developing more explainable and contestable AI decision-making systems. However, there is still work to be done to refine and validate this approach before it can be widely adopted.
Conclusion
This paper presents a novel method for supplementing large language models (LLMs) with argumentative reasoning, creating "argumentative LLMs." By using LLMs to construct interpretable argumentation frameworks, this approach enables more explainable and contestable decision-making.
The experimental results demonstrate the effectiveness of argumentative LLMs in the task of claim verification, where they achieve competitive or superior performance compared to state-of-the-art techniques. This suggests that the integration of formal reasoning and argumentation can help address some of the key limitations of current LLMs, potentially making them more suitable for high-stakes decision-making applications.
While the proposed approach has some limitations that require further research, the concept of argumentative LLMs represents an important step towards developing AI systems that can provide justifiable and accountable decisions. As large language models continue to grow in power and influence, techniques like this will be crucial for ensuring their safe and ethical deployment in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models are as persuasive as humans, but why? About the cognitive effort and moral-emotional language of LLM arguments
Carlos Carrasco-Farre
0
0
Large Language Models (LLMs) are already as persuasive as humans. However, we know very little about how they do it. This paper investigates the persuasion strategies of LLMs, comparing them with human-generated arguments. Using a dataset of 1,251 participants in an experiment, we analyze the persuasion strategies of LLM-generated and human-generated arguments using measures of cognitive effort (lexical and grammatical complexity) and moral-emotional language (sentiment and moral analysis). The study reveals that LLMs produce arguments that require higher cognitive effort, exhibiting more complex grammatical and lexical structures than human counterparts. Additionally, LLMs demonstrate a significant propensity to engage more deeply with moral language, utilizing both positive and negative moral foundations more frequently than humans. In contrast with previous research, no significant difference was found in the emotional content produced by LLMs and humans. These findings contribute to the discourse on AI and persuasion, highlighting the dual potential of LLMs to both enhance and undermine informational integrity through communication strategies for digital persuasion.
4/23/2024
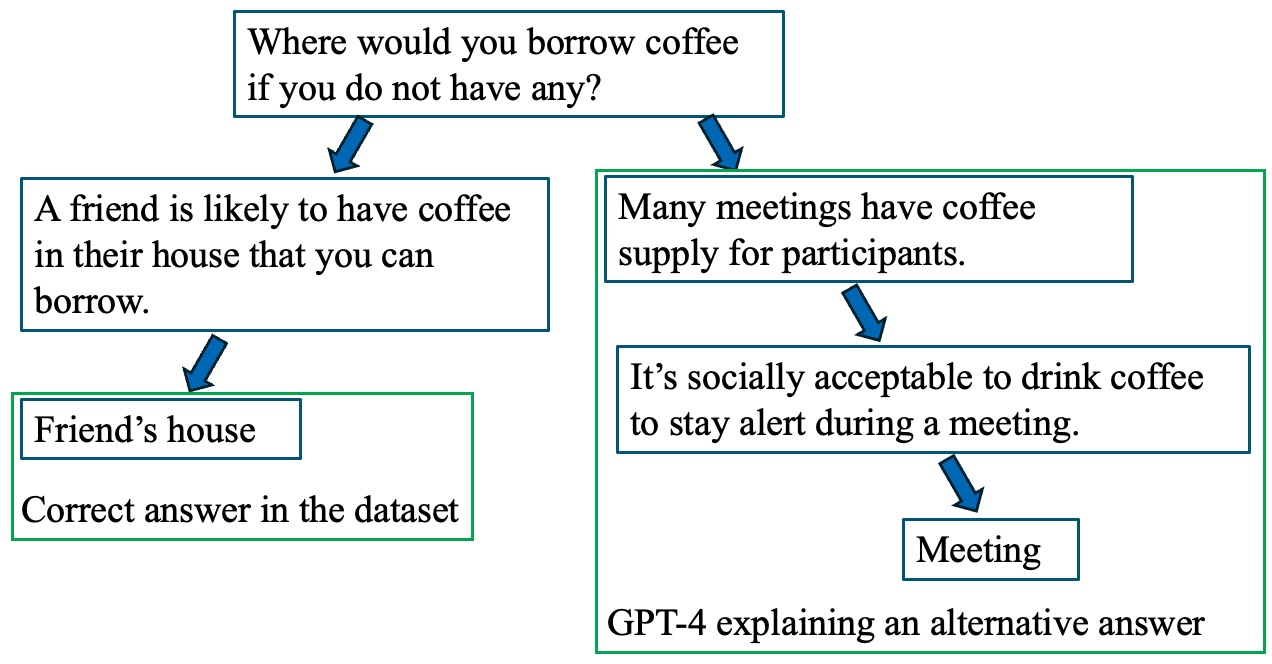
LLM-Generated Black-box Explanations Can Be Adversarially Helpful
Rohan Ajwani, Shashidhar Reddy Javaji, Frank Rudzicz, Zining Zhu
0
0
Large Language Models (LLMs) are becoming vital tools that help us solve and understand complex problems by acting as digital assistants. LLMs can generate convincing explanations, even when only given the inputs and outputs of these problems, i.e., in a ``black-box'' approach. However, our research uncovers a hidden risk tied to this approach, which we call *adversarial helpfulness*. This happens when an LLM's explanations make a wrong answer look right, potentially leading people to trust incorrect solutions. In this paper, we show that this issue affects not just humans, but also LLM evaluators. Digging deeper, we identify and examine key persuasive strategies employed by LLMs. Our findings reveal that these models employ strategies such as reframing the questions, expressing an elevated level of confidence, and cherry-picking evidence to paint misleading answers in a credible light. To examine if LLMs are able to navigate complex-structured knowledge when generating adversarially helpful explanations, we create a special task based on navigating through graphs. Some LLMs are not able to find alternative paths along simple graphs, indicating that their misleading explanations aren't produced by only logical deductions using complex knowledge. These findings shed light on the limitations of black-box explanation setting. We provide some advice on how to use LLMs as explainers safely.
5/14/2024
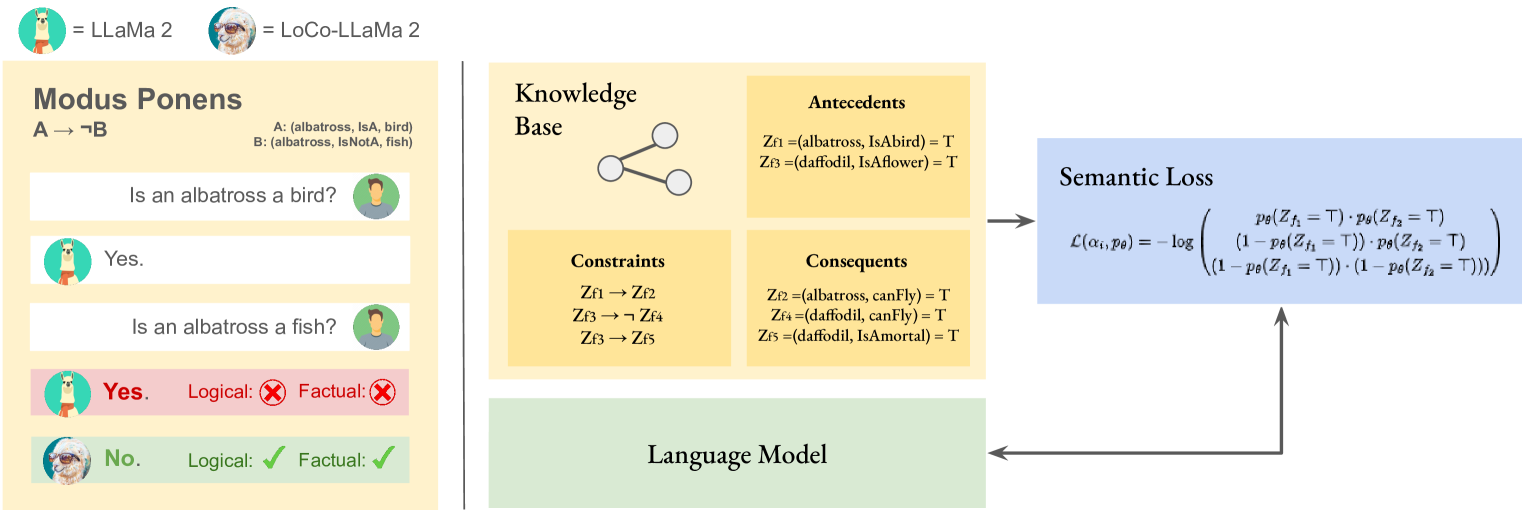
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
0
0
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
4/22/2024
💬
Are Large Language Models Reliable Argument Quality Annotators?
Nailia Mirzakhmedova, Marcel Gohsen, Chia Hao Chang, Benno Stein
0
0
Evaluating the quality of arguments is a crucial aspect of any system leveraging argument mining. However, it is a challenge to obtain reliable and consistent annotations regarding argument quality, as this usually requires domain-specific expertise of the annotators. Even among experts, the assessment of argument quality is often inconsistent due to the inherent subjectivity of this task. In this paper, we study the potential of using state-of-the-art large language models (LLMs) as proxies for argument quality annotators. To assess the capability of LLMs in this regard, we analyze the agreement between model, human expert, and human novice annotators based on an established taxonomy of argument quality dimensions. Our findings highlight that LLMs can produce consistent annotations, with a moderately high agreement with human experts across most of the quality dimensions. Moreover, we show that using LLMs as additional annotators can significantly improve the agreement between annotators. These results suggest that LLMs can serve as a valuable tool for automated argument quality assessment, thus streamlining and accelerating the evaluation of large argument datasets.
4/16/2024