Towards Logically Consistent Language Models via Probabilistic Reasoning
2404.12843
0
0
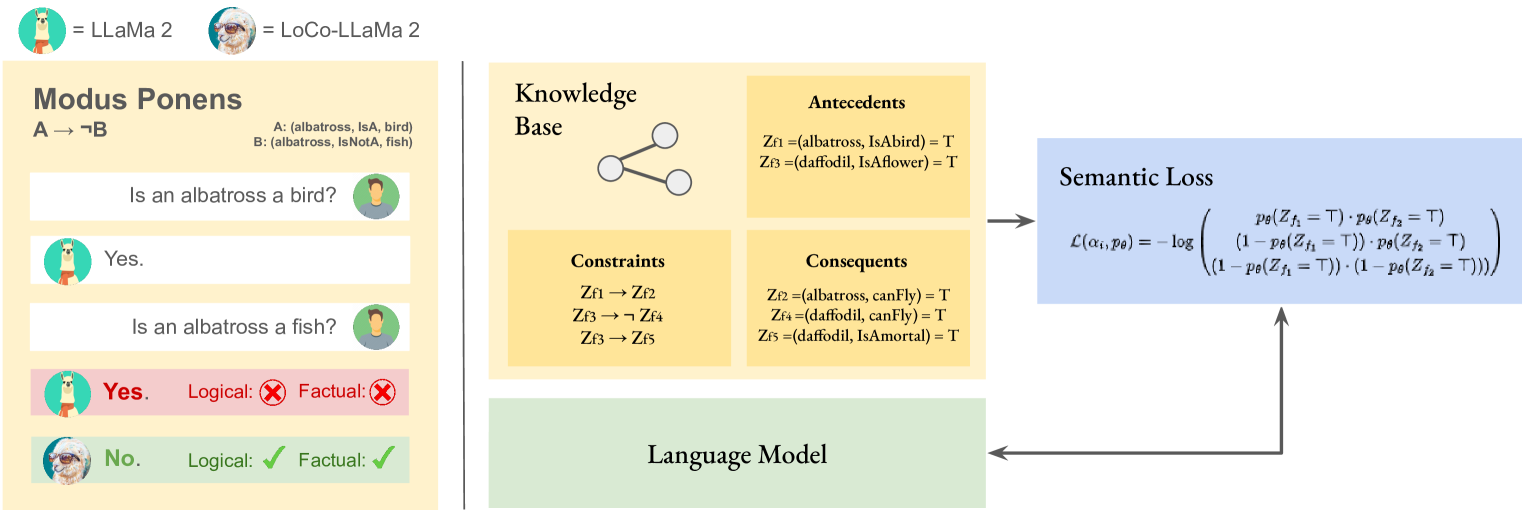
Abstract
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new approach called "LoCo-LMs" (Logically Consistent Language Models) that aims to improve the factual consistency and logical reasoning capabilities of large language models.
- The key idea is to use probabilistic reasoning techniques to constrain the model's outputs and ensure they are logically consistent, going beyond simply optimizing for accuracy.
- The authors evaluate LoCo-LMs on a range of benchmarks that test different aspects of reasoning, and find improvements over standard language models in areas like logical consistency, factual knowledge, and interventional reasoning.
Plain English Explanation
Large language models have become incredibly powerful at tasks like generating human-like text, answering questions, and even engaging in open-ended dialogue. However, these models can sometimes produce outputs that are factually incorrect or logically inconsistent. This is because they are primarily optimized to predict the next word in a sequence, without a strong underlying model of the real world or logical reasoning.
The researchers behind this paper wanted to address this limitation. They developed a new approach called "LoCo-LMs" that uses probabilistic reasoning techniques to constrain the model's outputs and ensure they are logically consistent. The key idea is to incorporate additional knowledge and reasoning capabilities into the language model, beyond just pure text prediction.
For example, if a LoCo-LM is asked "Is the sky blue?", it would not only consider the statistical patterns in the training data, but also draw on its understanding of physics and optics to deduce that the sky is indeed blue under normal conditions. This allows the model to avoid making logically inconsistent statements, even if they might be plausible based on the training data alone.
The researchers tested LoCo-LMs on a variety of benchmarks that assess different aspects of reasoning, such as logical consistency, factual knowledge, and interventional reasoning. They found that LoCo-LMs outperformed standard language models in these areas, demonstrating the potential of this approach to create more logically consistent and factually grounded language AI systems.
Technical Explanation
The core idea behind LoCo-LMs is to augment traditional language models with a probabilistic reasoning module that can enforce logical consistency constraints on the model's outputs. This is achieved by incorporating an additional neural network component that models the joint probability distribution over the relevant concepts and facts, based on external knowledge sources.
During inference, the language model and the probabilistic reasoning module work together to generate outputs that not only match the statistical patterns in the training data, but also satisfy the logical constraints imposed by the reasoning module. This helps to avoid outputs that are factually incorrect or logically inconsistent, even if they might be plausible from the perspective of the language model alone.
The authors evaluate LoCo-LMs on a range of benchmarks that test different aspects of reasoning, including logical consistency, factual knowledge, and interventional reasoning. The results demonstrate that LoCo-LMs are able to outperform standard language models on these tasks, suggesting that the probabilistic reasoning approach can effectively improve the logical consistency and factual grounding of language models.
Critical Analysis
The authors of this paper have presented a promising approach for enhancing the logical consistency and reasoning capabilities of large language models. However, there are a few caveats and limitations to consider:
-
The performance improvements of LoCo-LMs, while significant, are still relatively modest compared to the capabilities of the best human-level reasoning. More research is needed to further close this gap and achieve truly human-like logical consistency and reasoning.
-
The authors acknowledge that the current implementation of LoCo-LMs relies on manually curated knowledge bases and reasoning rules, which can be time-consuming and expensive to create. Developing more scalable and automated methods for acquiring this knowledge would be an important area for future work.
-
It's unclear how well LoCo-LMs would generalize to open-ended, real-world scenarios, where the logical constraints and relevant facts may not be known in advance. Further testing in more diverse and challenging settings would help to better understand the limitations and robustness of this approach.
-
The paper does not address potential biases or ethical concerns that may arise from using LoCo-LMs, such as the propagation of biases in the underlying knowledge bases or the potential for misuse in generating misinformation. Addressing these issues should be a priority for future research in this area.
Overall, the approach presented in this paper represents an important step forward in enhancing the logical consistency and reasoning capabilities of large language models. By incorporating probabilistic reasoning into the language modeling framework, the authors have demonstrated the potential to produce more reliable and trustworthy AI systems. Continued research and development in this direction could lead to significant advancements in the field of natural language AI.
Conclusion
This paper introduces a novel approach called "LoCo-LMs" that aims to improve the factual consistency and logical reasoning capabilities of large language models. By incorporating probabilistic reasoning techniques, LoCo-LMs are able to generate outputs that not only match statistical patterns in the training data, but also satisfy logical constraints and factual grounding.
The results of the authors' evaluations on various reasoning benchmarks demonstrate the effectiveness of this approach, with LoCo-LMs outperforming standard language models in areas like logical consistency, factual knowledge, and interventional reasoning. This represents an important step forward in the quest to develop more reliable and trustworthy AI systems that can engage in human-like reasoning and decision-making.
While the current implementation of LoCo-LMs has some limitations, the authors have demonstrated the potential of this approach to enhance the logical consistency and factual grounding of large language models. Continued research and development in this direction could lead to significant advancements in the field of natural language AI, with important implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Consistency and Reasoning Capabilities of Large Language Models
Yash Saxena, Sarthak Chopra, Arunendra Mani Tripathi
0
0
Large Language Models (LLMs) are extensively used today across various sectors, including academia, research, business, and finance, for tasks such as text generation, summarization, and translation. Despite their widespread adoption, these models often produce incorrect and misleading information, exhibiting a tendency to hallucinate. This behavior can be attributed to several factors, with consistency and reasoning capabilities being significant contributors. LLMs frequently lack the ability to generate explanations and engage in coherent reasoning, leading to inaccurate responses. Moreover, they exhibit inconsistencies in their outputs. This paper aims to evaluate and compare the consistency and reasoning capabilities of both public and proprietary LLMs. The experiments utilize the Boolq dataset as the ground truth, comprising questions, answers, and corresponding explanations. Queries from the dataset are presented as prompts to the LLMs, and the generated responses are evaluated against the ground truth answers. Additionally, explanations are generated to assess the models' reasoning abilities. Consistency is evaluated by repeatedly presenting the same query to the models and observing for variations in their responses. For measuring reasoning capabilities, the generated explanations are compared to the ground truth explanations using metrics such as BERT, BLEU, and F-1 scores. The findings reveal that proprietary models generally outperform public models in terms of both consistency and reasoning capabilities. However, even when presented with basic general knowledge questions, none of the models achieved a score of 90% in both consistency and reasoning. This study underscores the direct correlation between consistency and reasoning abilities in LLMs and highlights the inherent reasoning challenges present in current language models.
4/26/2024
💬
Argumentative Large Language Models for Explainable and Contestable Decision-Making
Gabriel Freedman, Adam Dejl, Deniz Gorur, Xiang Yin, Antonio Rago, Francesca Toni
0
0
The diversity of knowledge encoded in large language models (LLMs) and their ability to apply this knowledge zero-shot in a range of settings makes them a promising candidate for use in decision-making. However, they are currently limited by their inability to reliably provide outputs which are explainable and contestable. In this paper, we attempt to reconcile these strengths and weaknesses by introducing a method for supplementing LLMs with argumentative reasoning. Concretely, we introduce argumentative LLMs, a method utilising LLMs to construct argumentation frameworks, which then serve as the basis for formal reasoning in decision-making. The interpretable nature of these argumentation frameworks and formal reasoning means that any decision made by the supplemented LLM may be naturally explained to, and contested by, humans. We demonstrate the effectiveness of argumentative LLMs experimentally in the decision-making task of claim verification. We obtain results that are competitive with, and in some cases surpass, comparable state-of-the-art techniques.
5/6/2024
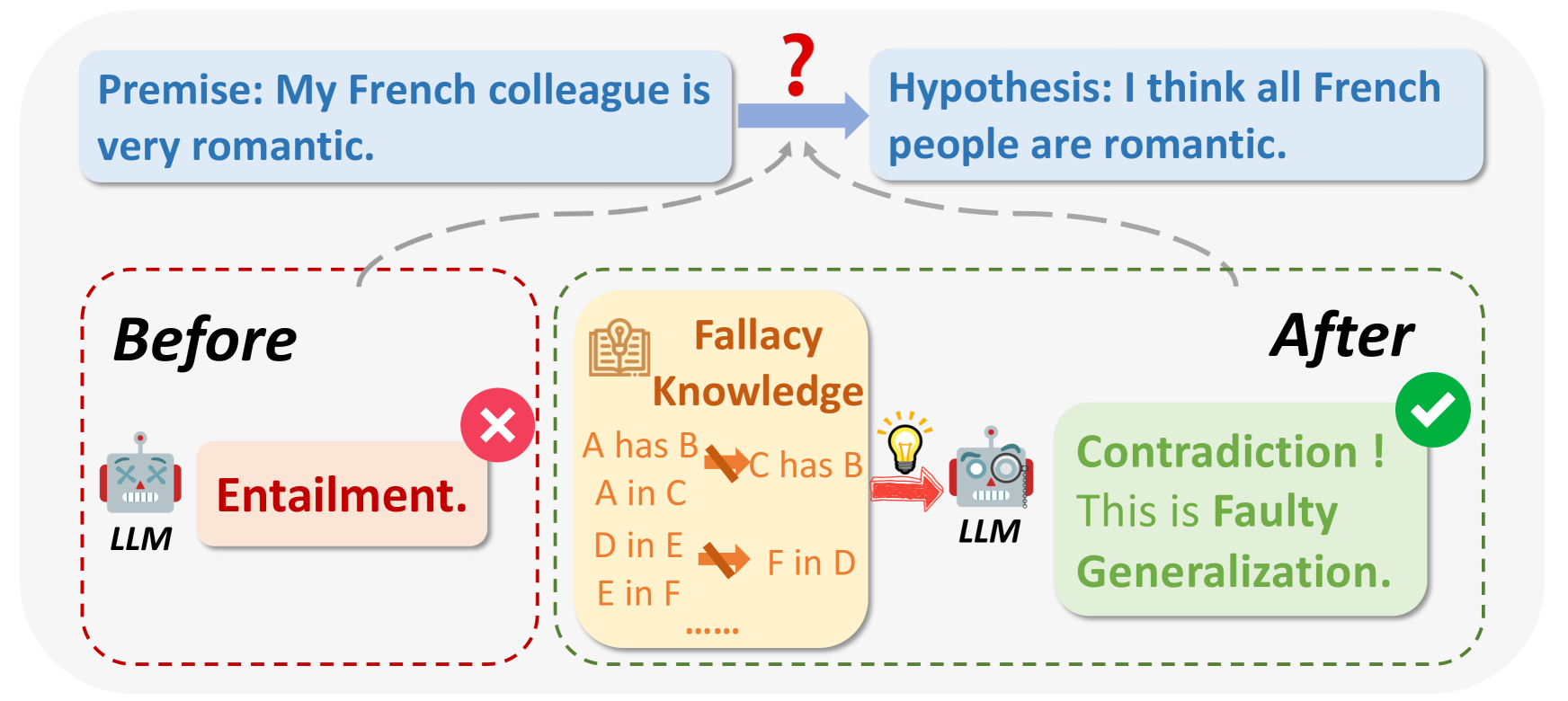
Reason from Fallacy: Enhancing Large Language Models' Logical Reasoning through Logical Fallacy Understanding
Yanda Li, Dixuan Wang, Jiaqing Liang, Guochao Jiang, Qianyu He, Yanghua Xiao, Deqing Yang
0
0
Large Language Models (LLMs) have demonstrated good performance in many reasoning tasks, but they still struggle with some complicated reasoning tasks including logical reasoning. One non-negligible reason for LLMs' suboptimal performance on logical reasoning is their overlooking of understanding logical fallacies correctly. To evaluate LLMs' capability of logical fallacy understanding (LFU), we propose five concrete tasks from three cognitive dimensions of WHAT, WHY, and HOW in this paper. Towards these LFU tasks, we have successfully constructed a new dataset LFUD based on GPT-4 accompanied by a little human effort. Our extensive experiments justify that our LFUD can be used not only to evaluate LLMs' LFU capability, but also to fine-tune LLMs to obtain significantly enhanced performance on logical reasoning.
4/9/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024