LLM-Generated Black-box Explanations Can Be Adversarially Helpful
2405.06800
0
0
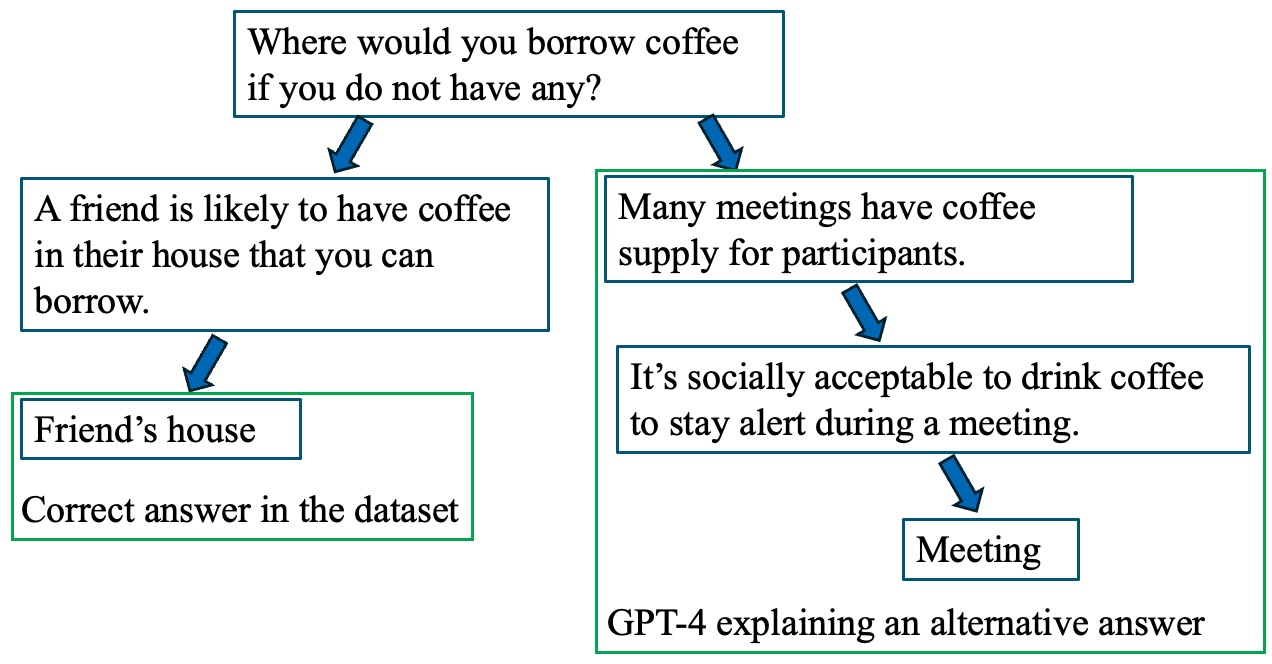
Abstract
Large Language Models (LLMs) are becoming vital tools that help us solve and understand complex problems by acting as digital assistants. LLMs can generate convincing explanations, even when only given the inputs and outputs of these problems, i.e., in a ``black-box'' approach. However, our research uncovers a hidden risk tied to this approach, which we call
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can be used to generate "black-box" explanations that may inadvertently help adversaries in harmful ways.
- The key insight is that LLM-generated explanations can sometimes provide useful information to bad actors, even if the explanations are not intended to do so.
- The paper examines this phenomenon and provides guidance on how to mitigate the potential risks.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. One application of LLMs is to provide "black-box" explanations for the decisions made by other AI systems. These explanations can help humans understand how the systems work, even if the inner workings are complex.
However, the paper finds that these LLM-generated explanations can sometimes be "adversarially helpful" - meaning they can unintentionally provide useful information to bad actors who want to manipulate or attack the AI systems. For example, an LLM-generated explanation of how a spam detection system works could inadvertently give spammers insights on how to bypass the system.
The research highlights that this is a significant concern, as LLMs become more widely used to explain AI decision-making. The authors provide guidance on how to mitigate these risks, such as carefully filtering the information included in the explanations and monitoring for potential misuse.
Overall, this paper sheds light on an important and overlooked challenge in the development of explainable AI systems. As LLMs become more advanced and integrated into high-stakes applications, understanding and managing their potential for unintended consequences will be crucial.
Technical Explanation
The paper investigates the phenomenon of "adversarially helpful" LLM-generated black-box explanations. The authors conducted a series of experiments to explore this issue.
First, they trained an LLM to generate explanations for the decisions of a spam detection model. They then showed that by analyzing the LLM-generated explanations, an adversary could gain valuable insights about the underlying spam detection system and use that information to evade its defenses.
Next, the researchers explored ways to mitigate this risk. They experimented with techniques like causal explainable guardrails and model-agnostic interpretability to modify the LLM-generated explanations, making them less helpful to adversaries while still providing useful information to humans.
The key insight from this work is that the very properties that make LLMs useful for generating explanations - their ability to produce coherent, human-like text - can also make them vulnerable to misuse by adversaries. The paper highlights the importance of carefully designing LLM-based explanation systems to balance the needs of transparency and security.
Critical Analysis
The paper provides a valuable contribution to the growing field of "XAI" (explainable AI), which seeks to make AI systems more interpretable and accountable. The authors' identification of the "adversarially helpful" phenomenon is an important insight that deserves further attention.
That said, the paper acknowledges several limitations and areas for future research. For example, the experiments were conducted on a relatively simple spam detection system, and it's unclear how the findings would scale to more complex AI applications. Additionally, the proposed mitigation strategies, while promising, require further development and testing.
Another potential issue is that the paper focuses primarily on the risks of LLM-generated explanations, without fully exploring their potential benefits. While the authors are right to highlight the security concerns, it's also important to consider how these explanations could empower users and improve trust in AI systems, if designed and deployed thoughtfully.
Overall, this paper serves as a valuable warning about a significant challenge in the field of explainable AI. As LLMs continue to advance and find their way into more high-stakes applications, understanding and addressing the risks of "adversarially helpful" explanations will be crucial to ensuring the safe and responsible development of these technologies.
Conclusion
This paper uncovers an important and overlooked challenge in the development of explainable AI systems: the potential for LLM-generated black-box explanations to be "adversarially helpful" and provide useful information to bad actors.
The research highlights the need for careful design and deployment of LLM-based explanation systems, balancing the demands of transparency and security. While the proposed mitigation strategies are promising, further work is needed to fully understand and address this issue as LLMs become more widely integrated into critical applications.
Overall, this paper serves as a valuable wake-up call for the AI research community, urging us to think critically about the unintended consequences of our powerful technologies and to work towards solutions that maximize the benefits of explainable AI while minimizing the risks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024
💬
Argumentative Large Language Models for Explainable and Contestable Decision-Making
Gabriel Freedman, Adam Dejl, Deniz Gorur, Xiang Yin, Antonio Rago, Francesca Toni
0
0
The diversity of knowledge encoded in large language models (LLMs) and their ability to apply this knowledge zero-shot in a range of settings makes them a promising candidate for use in decision-making. However, they are currently limited by their inability to reliably provide outputs which are explainable and contestable. In this paper, we attempt to reconcile these strengths and weaknesses by introducing a method for supplementing LLMs with argumentative reasoning. Concretely, we introduce argumentative LLMs, a method utilising LLMs to construct argumentation frameworks, which then serve as the basis for formal reasoning in decision-making. The interpretable nature of these argumentation frameworks and formal reasoning means that any decision made by the supplemented LLM may be naturally explained to, and contested by, humans. We demonstrate the effectiveness of argumentative LLMs experimentally in the decision-making task of claim verification. We obtain results that are competitive with, and in some cases surpass, comparable state-of-the-art techniques.
5/6/2024

Adversarial Math Word Problem Generation
Roy Xie, Chengxuan Huang, Junlin Wang, Bhuwan Dhingra
0
0
Large language models (LLMs) have significantly transformed the educational landscape. As current plagiarism detection tools struggle to keep pace with LLMs' rapid advancements, the educational community faces the challenge of assessing students' true problem-solving abilities in the presence of LLMs. In this work, we explore a new paradigm for ensuring fair evaluation -- generating adversarial examples which preserve the structure and difficulty of the original questions aimed for assessment, but are unsolvable by LLMs. Focusing on the domain of math word problems, we leverage abstract syntax trees to structurally generate adversarial examples that cause LLMs to produce incorrect answers by simply editing the numeric values in the problems. We conduct experiments on various open- and closed-source LLMs, quantitatively and qualitatively demonstrating that our method significantly degrades their math problem-solving ability. We identify shared vulnerabilities among LLMs and propose a cost-effective approach to attack high-cost models. Additionally, we conduct automatic analysis to investigate the cause of failure, providing further insights into the limitations of LLMs.
6/18/2024
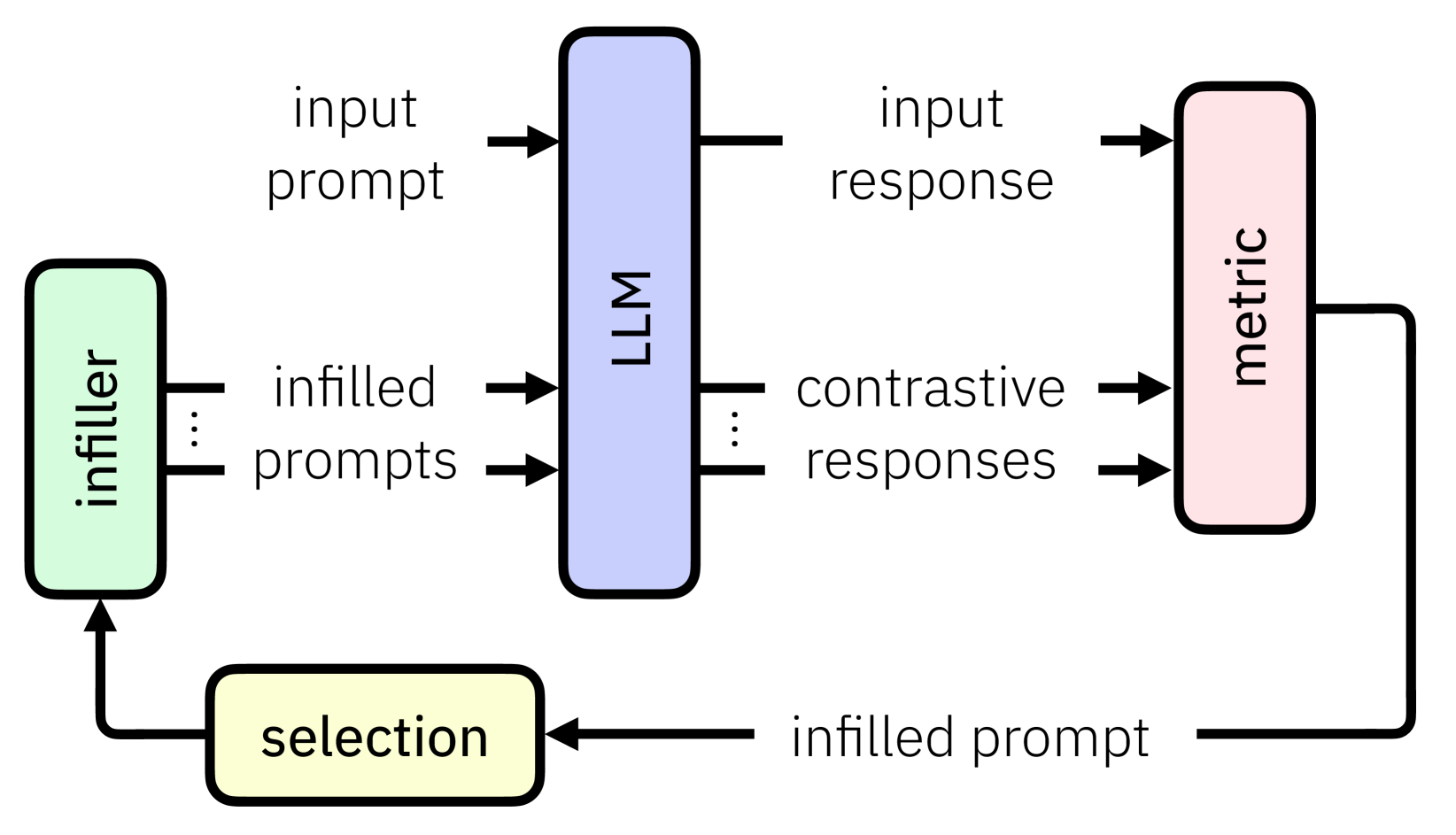
CELL your Model: Contrastive Explanation Methods for Large Language Models
Ronny Luss, Erik Miehling, Amit Dhurandhar
0
0
The advent of black-box deep neural network classification models has sparked the need to explain their decisions. However, in the case of generative AI such as large language models (LLMs), there is no class prediction to explain. Rather, one can ask why an LLM output a particular response to a given prompt. In this paper, we answer this question by proposing, to the best of our knowledge, the first contrastive explanation methods requiring simply black-box/query access. Our explanations suggest that an LLM outputs a reply to a given prompt because if the prompt was slightly modified, the LLM would have given a different response that is either less preferable or contradicts the original response. The key insight is that contrastive explanations simply require a distance function that has meaning to the user and not necessarily a real valued representation of a specific response (viz. class label). We offer two algorithms for finding contrastive explanations: i) A myopic algorithm, which although effective in creating contrasts, requires many model calls and ii) A budgeted algorithm, our main algorithmic contribution, which intelligently creates contrasts adhering to a query budget, necessary for longer contexts. We show the efficacy of these methods on diverse natural language tasks such as open-text generation, automated red teaming, and explaining conversational degradation.
6/18/2024