ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews

1

Sign in to get full access
Overview
- The paper presents ARIES, a corpus of scientific paper edits made in response to peer reviews.
- The corpus contains over 1,000 paper revisions and associated peer review comments.
- The dataset aims to facilitate research on understanding the peer review process and developing systems to assist researchers in responding to reviews.
Plain English Explanation
The paper introduces a new dataset called ARIES, which contains 1,000+ scientific paper revisions and the corresponding peer review comments that prompted those revisions. The goal of this dataset is to help researchers better understand the peer review process and develop tools to assist scientists in effectively responding to peer feedback on their work.
When researchers submit a paper to a journal, it goes through a peer review process where other experts in the field provide feedback and suggestions for improvement. The authors then revise the paper based on this feedback before resubmitting it. ARIES captures this iterative process, providing a valuable resource for analyzing how scientists incorporate reviewer comments into their paper edits.
This dataset could enable the development of AI-powered tools to help authors more efficiently and effectively respond to peer reviews, ultimately improving the overall quality of scientific publications. By studying the patterns in how authors update their papers, researchers may also gain new insights into the peer review system itself.
Technical Explanation
The ARIES corpus was constructed by collecting paper submissions, peer review comments, and revised versions of papers from various scientific conferences and journals. The dataset contains over 1,000 paper revisions, each paired with the corresponding set of peer review comments that prompted the changes.
To create ARIES, the researchers first identified conferences and journals that make peer review comments publicly available, such as the ACL Anthology and the ArXiv preprint server. They then extracted the peer review comments and matched them to the revised versions of the papers, creating a dataset that tracks the evolution of scientific papers in response to feedback.
The dataset includes a variety of metadata, such as the author names, paper titles, submission dates, and reviewer comments. This information enables researchers to analyze how different factors, such as the type of feedback or the academic field, may influence the revision process.
Critical Analysis
The ARIES dataset provides a valuable resource for studying the peer review process, but it also has some limitations. The dataset is limited to papers that were made publicly available, which may introduce selection bias. Additionally, the dataset does not include information about the final publication status of the papers, so it's unclear how the revisions ultimately impacted the acceptance or rejection of the work.
Another potential issue is that the dataset only captures the revisions made in response to the initial round of peer reviews. It does not contain information about subsequent rounds of reviews or revisions that may have occurred before final publication. This means the dataset may not fully reflect the iterative nature of the peer review process.
Despite these caveats, the ARIES dataset represents a significant step forward in understanding the dynamics of scientific publishing. By providing researchers with a rich dataset of paper edits and associated peer feedback, the ARIES corpus enables new avenues of research into automated citation retrieval and the development of tools to assist authors in responding to peer reviews.
Conclusion
The ARIES dataset is a valuable resource for researchers interested in understanding the peer review process and developing systems to support scientific authors. By providing a corpus of paper revisions paired with peer review comments, the dataset enables new approaches to analyzing how researchers incorporate feedback and improve their work. While the dataset has some limitations, it represents an important step forward in the study of scientific publishing and offers exciting opportunities for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews
Mike D'Arcy, Alexis Ross, Erin Bransom, Bailey Kuehl, Jonathan Bragg, Tom Hope, Doug Downey
We introduce the task of automatically revising scientific papers based on peer feedback and release ARIES, a dataset of review comments and their corresponding paper edits. The data is drawn from real reviewer-author interactions from computer science, and we provide labels linking each reviewer comment to the specific paper edits made by the author in response. We automatically create a high-precision silver training set, as well as an expert-labeled test set that shows high inter-annotator agreement. In experiments with 10 models covering the state of the art, we find that they struggle even to identify which edits correspond to a comment -- especially when the relationship between the edit and the comment is indirect and requires reasoning to uncover. We also extensively analyze GPT-4's ability to generate edits given a comment and the original paper. We find that it often succeeds on a superficial level, but tends to rigidly follow the wording of the feedback rather than the underlying intent, and lacks technical details compared to human-written edits.
Read more8/7/2024
🤖
0
RelevAI-Reviewer: A Benchmark on AI Reviewers for Survey Paper Relevance
Paulo Henrique Couto (TAU, LISN), Quang Phuoc Ho (TAU, LISN), Nageeta Kumari (TAU, LISN), Benedictus Kent Rachmat (TAU, LISN), Thanh Gia Hieu Khuong (TAU, LISN), Ihsan Ullah (TAU, LISN), Lisheng Sun-Hosoya (TAU, LISN)
Recent advancements in Artificial Intelligence (AI), particularly the widespread adoption of Large Language Models (LLMs), have significantly enhanced text analysis capabilities. This technological evolution offers considerable promise for automating the review of scientific papers, a task traditionally managed through peer review by fellow researchers. Despite its critical role in maintaining research quality, the conventional peer-review process is often slow and subject to biases, potentially impeding the swift propagation of scientific knowledge. In this paper, we propose RelevAI-Reviewer, an automatic system that conceptualizes the task of survey paper review as a classification problem, aimed at assessing the relevance of a paper in relation to a specified prompt, analogous to a call for papers. To address this, we introduce a novel dataset comprised of 25,164 instances. Each instance contains one prompt and four candidate papers, each varying in relevance to the prompt. The objective is to develop a machine learning (ML) model capable of determining the relevance of each paper and identifying the most pertinent one. We explore various baseline approaches, including traditional ML classifiers like Support Vector Machine (SVM) and advanced language models such as BERT. Preliminary findings indicate that the BERT-based end-to-end classifier surpasses other conventional ML methods in performance. We present this problem as a public challenge to foster engagement and interest in this area of research.
Read more6/18/2024
1
Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Weixin Liang, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, Haotian Ye, Sheng Liu, Zhi Huang, Daniel A. McFarland, James Y. Zou
We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.
Read more6/18/2024
0
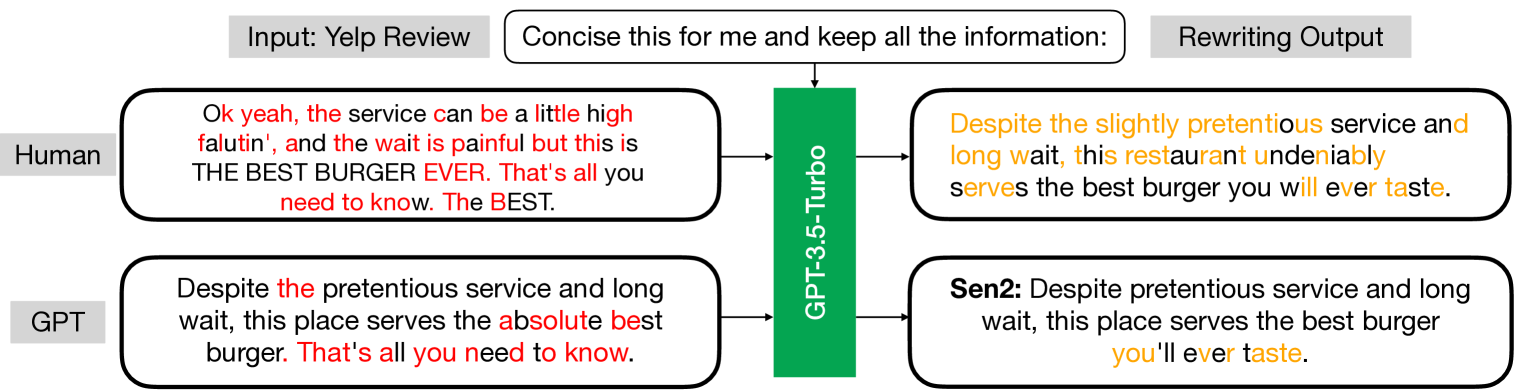
Raidar: geneRative AI Detection viA Rewriting
Chengzhi Mao, Carl Vondrick, Hao Wang, Junfeng Yang
We find that large language models (LLMs) are more likely to modify human-written text than AI-generated text when tasked with rewriting. This tendency arises because LLMs often perceive AI-generated text as high-quality, leading to fewer modifications. We introduce a method to detect AI-generated content by prompting LLMs to rewrite text and calculating the editing distance of the output. We dubbed our geneRative AI Detection viA Rewriting method Raidar. Raidar significantly improves the F1 detection scores of existing AI content detection models -- both academic and commercial -- across various domains, including News, creative writing, student essays, code, Yelp reviews, and arXiv papers, with gains of up to 29 points. Operating solely on word symbols without high-dimensional features, our method is compatible with black box LLMs, and is inherently robust on new content. Our results illustrate the unique imprint of machine-generated text through the lens of the machines themselves.
Read more4/16/2024