RelevAI-Reviewer: A Benchmark on AI Reviewers for Survey Paper Relevance

0
🤖
Sign in to get full access
Overview
- Recent advancements in Artificial Intelligence (AI), particularly the widespread adoption of Large Language Models (LLMs), have significantly enhanced text analysis capabilities.
- This technological evolution offers considerable promise for automating the review of scientific papers, a task traditionally managed through peer review by fellow researchers.
- The conventional peer-review process is often slow and subject to biases, potentially impeding the swift propagation of scientific knowledge.
- The paper proposes RelevAI-Reviewer, an automatic system that conceptualizes the task of survey paper review as a classification problem, aimed at assessing the relevance of a paper in relation to a specified prompt, analogous to a call for papers.
Plain English Explanation
The paper discusses how recent advancements in AI, specifically the rise of Large Language Models (LLMs), have significantly improved the ability to analyze and understand text. This opens up the possibility of automating the process of reviewing scientific papers, which is traditionally done by other researchers through a process called peer review.
The peer review process, while critical for maintaining research quality, can be slow and subject to biases, which can slow down the spread of new scientific knowledge. To address this, the researchers have developed a system called RelevAI-Reviewer that uses machine learning to automatically assess the relevance of a paper to a given prompt, similar to how a call for papers would work.
The key idea is to train a machine learning model to determine which paper is the most relevant to a given prompt, rather than having human reviewers do this task. This could potentially make the review process faster and more efficient, while still maintaining high-quality standards.
Technical Explanation
The paper introduces a novel dataset comprising 25,164 instances, where each instance contains one prompt and four candidate papers, each varying in relevance to the prompt. The objective is to develop a machine learning (ML) model capable of determining the relevance of each paper and identifying the most pertinent one.
The researchers explore various baseline approaches, including traditional ML classifiers like Support Vector Machine (SVM) and advanced language models such as BERT. Preliminary findings indicate that the BERT-based end-to-end classifier surpasses other conventional ML methods in performance.
The paper presents this problem as a public challenge to foster engagement and interest in this area of research, with the goal of improving the speed and efficiency of the scientific peer review process through the use of AI-powered tools.
Critical Analysis
The paper acknowledges that the conventional peer-review process is subject to biases and can be slow, which can potentially impede the swift propagation of scientific knowledge. However, the paper does not delve deeply into the specific biases or limitations of the current peer-review system.
While the proposed RelevAI-Reviewer system shows promise in automating the paper review process, the paper does not address potential concerns about the reliability and transparency of such an AI-powered system. There may be questions about the ability of the system to accurately assess the nuances and broader implications of a scientific paper, which are crucial aspects of the peer-review process.
Additionally, the paper does not discuss the potential ethical implications of using AI in the peer-review process, such as the risk of perpetuating biases or the need for human oversight and accountability.
Further research would be needed to fully assess the feasibility and limitations of the RelevAI-Reviewer system, as well as to address the potential challenges and ethical considerations of AI-assisted peer review.
Conclusion
The paper presents an innovative approach to automating the review of scientific papers using Large Language Models (LLMs) and machine learning. This could potentially address the limitations of the traditional peer-review process, such as slowness and biases, and lead to a more efficient and timely dissemination of scientific knowledge.
However, the paper also highlights the need for further research to address the reliability, transparency, and ethical implications of such AI-powered systems in the context of scientific peer review. Striking the right balance between automation and human oversight will be crucial in ensuring the integrity and quality of the scientific publishing process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
RelevAI-Reviewer: A Benchmark on AI Reviewers for Survey Paper Relevance
Paulo Henrique Couto (TAU, LISN), Quang Phuoc Ho (TAU, LISN), Nageeta Kumari (TAU, LISN), Benedictus Kent Rachmat (TAU, LISN), Thanh Gia Hieu Khuong (TAU, LISN), Ihsan Ullah (TAU, LISN), Lisheng Sun-Hosoya (TAU, LISN)
Recent advancements in Artificial Intelligence (AI), particularly the widespread adoption of Large Language Models (LLMs), have significantly enhanced text analysis capabilities. This technological evolution offers considerable promise for automating the review of scientific papers, a task traditionally managed through peer review by fellow researchers. Despite its critical role in maintaining research quality, the conventional peer-review process is often slow and subject to biases, potentially impeding the swift propagation of scientific knowledge. In this paper, we propose RelevAI-Reviewer, an automatic system that conceptualizes the task of survey paper review as a classification problem, aimed at assessing the relevance of a paper in relation to a specified prompt, analogous to a call for papers. To address this, we introduce a novel dataset comprised of 25,164 instances. Each instance contains one prompt and four candidate papers, each varying in relevance to the prompt. The objective is to develop a machine learning (ML) model capable of determining the relevance of each paper and identifying the most pertinent one. We explore various baseline approaches, including traditional ML classifiers like Support Vector Machine (SVM) and advanced language models such as BERT. Preliminary findings indicate that the BERT-based end-to-end classifier surpasses other conventional ML methods in performance. We present this problem as a public challenge to foster engagement and interest in this area of research.
Read more6/18/2024
1
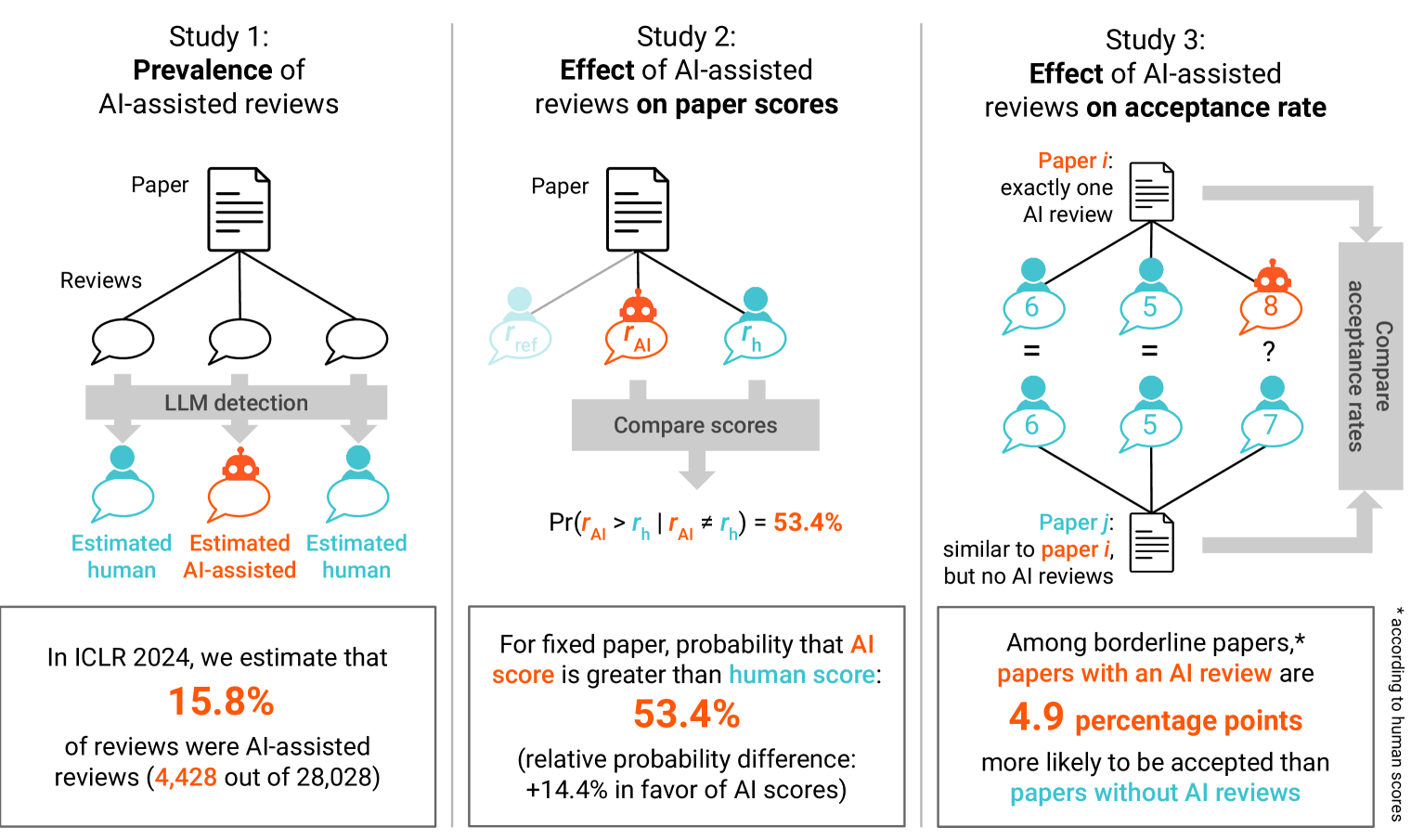
The AI Review Lottery: Widespread AI-Assisted Peer Reviews Boost Paper Scores and Acceptance Rates
Giuseppe Russo Latona, Manoel Horta Ribeiro, Tim R. Davidson, Veniamin Veselovsky, Robert West
Journals and conferences worry that peer reviews assisted by artificial intelligence (AI), in particular, large language models (LLMs), may negatively influence the validity and fairness of the peer-review system, a cornerstone of modern science. In this work, we address this concern with a quasi-experimental study of the prevalence and impact of AI-assisted peer reviews in the context of the 2024 International Conference on Learning Representations (ICLR), a large and prestigious machine-learning conference. Our contributions are threefold. Firstly, we obtain a lower bound for the prevalence of AI-assisted reviews at ICLR 2024 using the GPTZero LLM detector, estimating that at least $15.8%$ of reviews were written with AI assistance. Secondly, we estimate the impact of AI-assisted reviews on submission scores. Considering pairs of reviews with different scores assigned to the same paper, we find that in $53.4%$ of pairs the AI-assisted review scores higher than the human review ($p = 0.002$; relative difference in probability of scoring higher: $+14.4%$ in favor of AI-assisted reviews). Thirdly, we assess the impact of receiving an AI-assisted peer review on submission acceptance. In a matched study, submissions near the acceptance threshold that received an AI-assisted peer review were $4.9$ percentage points ($p = 0.024$) more likely to be accepted than submissions that did not. Overall, we show that AI-assisted reviews are consequential to the peer-review process and offer a discussion on future implications of current trends
Read more5/6/2024
0
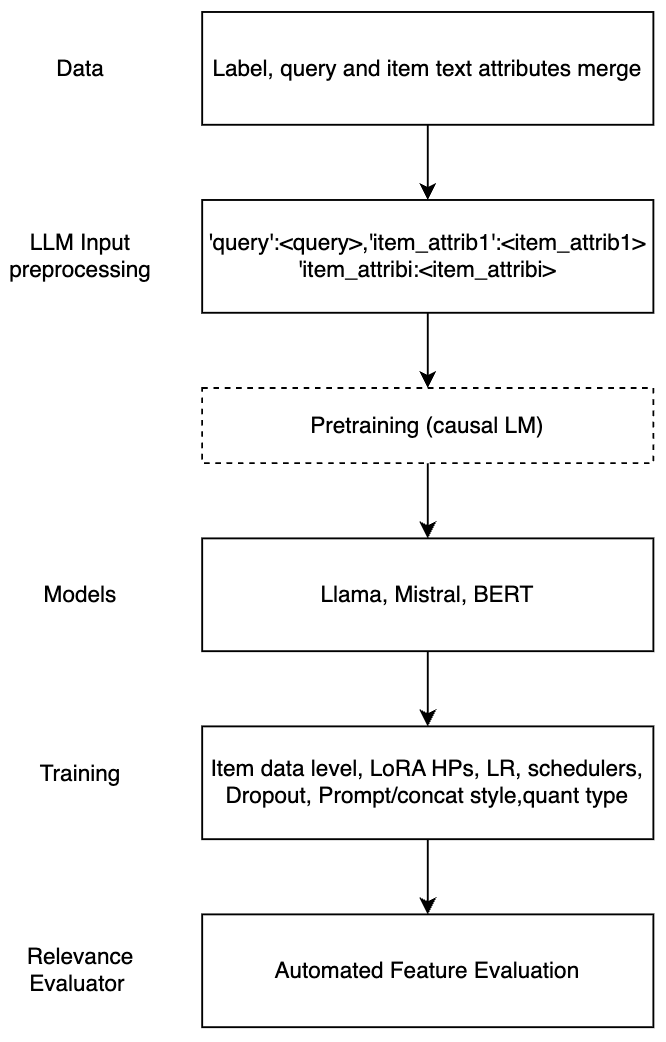
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
Read more7/18/2024

0
AI-Driven Review Systems: Evaluating LLMs in Scalable and Bias-Aware Academic Reviews
Keith Tyser, Ben Segev, Gaston Longhitano, Xin-Yu Zhang, Zachary Meeks, Jason Lee, Uday Garg, Nicholas Belsten, Avi Shporer, Madeleine Udell, Dov Te'eni, Iddo Drori
Automatic reviewing helps handle a large volume of papers, provides early feedback and quality control, reduces bias, and allows the analysis of trends. We evaluate the alignment of automatic paper reviews with human reviews using an arena of human preferences by pairwise comparisons. Gathering human preference may be time-consuming; therefore, we also use an LLM to automatically evaluate reviews to increase sample efficiency while reducing bias. In addition to evaluating human and LLM preferences among LLM reviews, we fine-tune an LLM to predict human preferences, predicting which reviews humans will prefer in a head-to-head battle between LLMs. We artificially introduce errors into papers and analyze the LLM's responses to identify limitations, use adaptive review questions, meta prompting, role-playing, integrate visual and textual analysis, use venue-specific reviewing materials, and predict human preferences, improving upon the limitations of the traditional review processes. We make the reviews of publicly available arXiv and open-access Nature journal papers available online, along with a free service which helps authors review and revise their research papers and improve their quality. This work develops proof-of-concept LLM reviewing systems that quickly deliver consistent, high-quality reviews and evaluate their quality. We mitigate the risks of misuse, inflated review scores, overconfident ratings, and skewed score distributions by augmenting the LLM with multiple documents, including the review form, reviewer guide, code of ethics and conduct, area chair guidelines, and previous year statistics, by finding which errors and shortcomings of the paper may be detected by automated reviews, and evaluating pairwise reviewer preferences. This work identifies and addresses the limitations of using LLMs as reviewers and evaluators and enhances the quality of the reviewing process.
Read more8/21/2024