ARL2: Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling

0

Sign in to get full access
Overview
- This paper introduces Arl2, a novel method for aligning retrieval models with black-box large language models (LLMs) using self-guided adaptive relevance labeling.
- The researchers aim to improve the performance of retrieval-augmented LLMs by better aligning the retrieval model with the LLM's relevance criteria.
- Arl2 employs an adaptive relevance labeling strategy that iteratively refines the retrieval model based on feedback from the LLM.
Plain English Explanation
In this paper, the researchers present a new technique called Arl2 (Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling) to help improve the performance of retrieval-augmented large language models.
Large language models are powerful AI systems that can generate human-like text, answer questions, and complete a variety of tasks. However, these models can sometimes struggle with tasks that require retrieving and integrating information from external sources. To address this, researchers have been exploring "retrieval-augmented" language models, which combine a language model with a separate retrieval system to access relevant information.
The key challenge is that the retrieval system needs to be well-aligned with the language model's internal relevance criteria in order to provide the most useful information. Arl2 aims to solve this by using an adaptive feedback loop. The retrieval model iteratively refines its search results based on feedback from the language model, helping the two components work together more effectively.
This self-guided approach allows Arl2 to align the retrieval model without needing access to the inner workings of the language model, which are often "black boxes" that are difficult to inspect directly. By improving the alignment between the retrieval and language model components, Arl2 can enhance the overall performance of retrieval-augmented language models on tasks that require integrating external information.
Technical Explanation
The paper introduces Arl2 (Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling), a novel method for better aligning retrieval models with the relevance criteria of black-box large language models (LLMs).
Retrieval-augmented LLMs combine a language model with a separate retrieval system to access relevant information from external sources. However, ensuring that the retrieval model provides the most useful information to the LLM is challenging, as the LLM's internal relevance criteria are often opaque.
Arl2 addresses this by employing an adaptive relevance labeling strategy. The retrieval model is iteratively refined based on feedback from the LLM, allowing the two components to become better aligned without requiring direct access to the LLM's internal workings.
Specifically, Arl2 uses the LLM's predictions on a set of queries to generate relevance labels for the retrieval model's outputs. These labels are then used to fine-tune the retrieval model, improving its ability to provide the most relevant information to the LLM. This self-guided adaptive process continues over multiple iterations, gradually aligning the retrieval model with the LLM's relevance criteria.
The researchers evaluate Arl2 on several benchmark retrieval-augmented language model tasks, demonstrating significant performance improvements compared to existing methods. Arl2 is particularly effective for empowering large language models to efficiently integrate external knowledge and improve task-specific performance.
Critical Analysis
The Arl2 method presented in this paper offers a promising approach for aligning retrieval models with the relevance criteria of black-box large language models. By using an adaptive feedback loop to iteratively refine the retrieval model, Arl2 can improve the performance of retrieval-augmented LLMs without requiring direct access to the LLM's internal workings.
One potential limitation of the approach is that it relies on the assumption that the LLM's relevance feedback is a reliable signal for training the retrieval model. If the LLM's own relevance criteria are imperfect or biased, this could lead to suboptimal alignment between the two components. Additionally, the iterative nature of the Arl2 process means that any initial misalignment or errors could propagate and amplify over successive rounds of refinement.
Further research could explore ways to validate or cross-check the LLM's relevance feedback, perhaps by incorporating additional sources of information or leveraging human-annotated relevance judgments. Investigating the robustness of Arl2 to different types of LLMs and retrieval tasks would also be valuable.
Despite these potential limitations, the Arl2 method represents an important step forward in enhancing the performance of retrieval-augmented language models. By better aligning the retrieval and language model components, this approach could unlock new capabilities for tasks that require integrating external knowledge, such as biomedical question answering or extreme multi-label classification. As the field of large language models continues to advance, techniques like Arl2 will be increasingly important for leveraging the full potential of these powerful AI systems.
Conclusion
The Arl2 method introduced in this paper offers a novel approach for aligning retrieval models with the relevance criteria of black-box large language models. By employing an adaptive feedback loop, Arl2 is able to refine the retrieval model's performance without requiring direct access to the inner workings of the LLM.
This self-guided alignment process can significantly improve the performance of retrieval-augmented language models on a variety of tasks that rely on integrating external information. While the approach has some potential limitations, Arl2 represents an important step forward in enhancing the capabilities of large language models and unlocking new applications that leverage their power in conjunction with specialized retrieval systems.
As the field of AI continues to advance, techniques like Arl2 will play an increasingly important role in empowering large language models to efficiently extract and utilize relevant knowledge from diverse sources. This could lead to significant breakthroughs in areas such as biomedical research, decision support, and content generation, ultimately benefiting society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ARL2: Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
Lingxi Zhang, Yue Yu, Kuan Wang, Chao Zhang
Retrieval-augmented generation enhances large language models (LLMs) by incorporating relevant information from external knowledge sources. This enables LLMs to adapt to specific domains and mitigate hallucinations in knowledge-intensive tasks. However, existing retrievers are often misaligned with LLMs due to their separate training processes and the black-box nature of LLMs. To address this challenge, we propose ARL2, a retriever learning technique that harnesses LLMs as labelers. ARL2 leverages LLMs to annotate and score relevant evidence, enabling learning the retriever from robust LLM supervision. Furthermore, ARL2 uses an adaptive self-training strategy for curating high-quality and diverse relevance data, which can effectively reduce the annotation cost. Extensive experiments demonstrate the effectiveness of ARL2, achieving accuracy improvements of 5.4% on NQ and 4.6% on MMLU compared to the state-of-the-art methods. Additionally, ARL2 exhibits robust transfer learning capabilities and strong zero-shot generalization abilities. Our code will be published at url{https://github.com/zhanglingxi-cs/ARL2}.
Read more6/5/2024

155
Improving Retrieval Augmented Language Model with Self-Reasoning
Yuan Xia, Jingbo Zhou, Zhenhui Shi, Jun Chen, Haifeng Huang
The Retrieval-Augmented Language Model (RALM) has shown remarkable performance on knowledge-intensive tasks by incorporating external knowledge during inference, which mitigates the factual hallucinations inherited in large language models (LLMs). Despite these advancements, challenges persist in the implementation of RALMs, particularly concerning their reliability and traceability. To be specific, the irrelevant document retrieval may result in unhelpful response generation or even deteriorate the performance of LLMs, while the lack of proper citations in generated outputs complicates efforts to verify the trustworthiness of the models. To this end, we propose a novel self-reasoning framework aimed at improving the reliability and traceability of RALMs, whose core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. We have evaluated our framework across four public datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset) to demonstrate the superiority of our method, which can outperform existing state-of-art models and can achieve comparable performance with GPT-4, while only using 2,000 training samples.
Read more8/6/2024
0
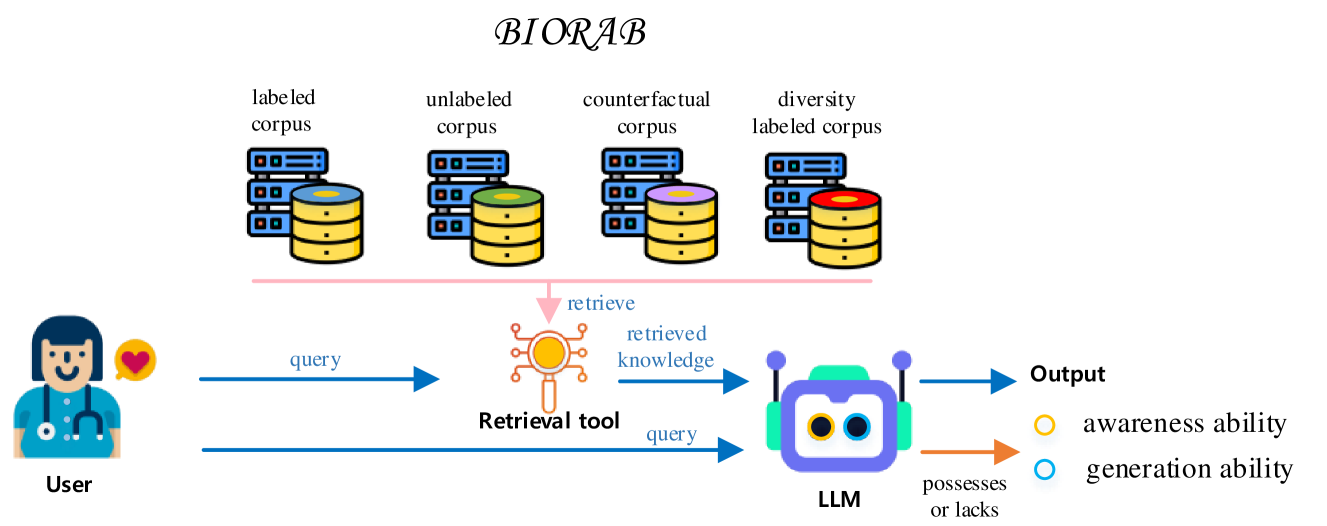
Benchmarking Retrieval-Augmented Large Language Models in Biomedical NLP: Application, Robustness, and Self-Awareness
Mingchen Li, Zaifu Zhan, Han Yang, Yongkang Xiao, Jiatan Huang, Rui Zhang
Large language models (LLM) have demonstrated remarkable capabilities in various biomedical natural language processing (NLP) tasks, leveraging the demonstration within the input context to adapt to new tasks. However, LLM is sensitive to the selection of demonstrations. To address the hallucination issue inherent in LLM, retrieval-augmented LLM (RAL) offers a solution by retrieving pertinent information from an established database. Nonetheless, existing research work lacks rigorous evaluation of the impact of retrieval-augmented large language models on different biomedical NLP tasks. This deficiency makes it challenging to ascertain the capabilities of RAL within the biomedical domain. Moreover, the outputs from RAL are affected by retrieving the unlabeled, counterfactual, or diverse knowledge that is not well studied in the biomedical domain. However, such knowledge is common in the real world. Finally, exploring the self-awareness ability is also crucial for the RAL system. So, in this paper, we systematically investigate the impact of RALs on 5 different biomedical tasks (triple extraction, link prediction, classification, question answering, and natural language inference). We analyze the performance of RALs in four fundamental abilities, including unlabeled robustness, counterfactual robustness, diverse robustness, and negative awareness. To this end, we proposed an evaluation framework to assess the RALs' performance on different biomedical NLP tasks and establish four different testbeds based on the aforementioned fundamental abilities. Then, we evaluate 3 representative LLMs with 3 different retrievers on 5 tasks over 9 datasets.
Read more5/17/2024
💬
0
Redefining Information Retrieval of Structured Database via Large Language Models
Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Juanyi Yang, Hong Zhang
Retrieval augmentation is critical when Language Models (LMs) exploit non-parametric knowledge related to the query through external knowledge bases before reasoning. The retrieved information is incorporated into LMs as context alongside the query, enhancing the reliability of responses towards factual questions. Prior researches in retrieval augmentation typically follow a retriever-generator paradigm. In this context, traditional retrievers encounter challenges in precisely and seamlessly extracting query-relevant information from knowledge bases. To address this issue, this paper introduces a novel retrieval augmentation framework called ChatLR that primarily employs the powerful semantic understanding ability of Large Language Models (LLMs) as retrievers to achieve precise and concise information retrieval. Additionally, we construct an LLM-based search and question answering system tailored for the financial domain by fine-tuning LLM on two tasks including Text2API and API-ID recognition. Experimental results demonstrate the effectiveness of ChatLR in addressing user queries, achieving an overall information retrieval accuracy exceeding 98.8%.
Read more5/10/2024