Benchmarking Retrieval-Augmented Large Language Models in Biomedical NLP: Application, Robustness, and Self-Awareness

0
Sign in to get full access
Overview
- This paper examines the performance of retrieval-augmented large language models (RALMs) in biomedical natural language processing (NLP) tasks.
- RALMs combine large language models with information retrieval systems to enhance their knowledge and capabilities.
- The paper evaluates the application, robustness, and self-awareness of RALMs in biomedical domains.
Plain English Explanation
Large language models, like GPT-3, are powerful AI systems that can generate human-like text. However, they can sometimes make mistakes or generate unreliable information, especially when dealing with specialized domains like biomedicine.
To address this, researchers have developed retrieval-augmented language models (RALMs), which combine language models with information retrieval systems. This allows the models to access relevant background knowledge and data when answering questions or generating text, potentially improving their accuracy and reliability.
In this paper, the authors investigate how well these RALMs perform on various biomedical NLP tasks, such as question answering and summarization. They also examine how robust the models are to changes in the input data, and how well they can recognize when they are uncertain or may have made a mistake.
By understanding the strengths and limitations of RALMs in biomedical domains, the researchers aim to inform the development of more reliable and trustworthy AI systems for healthcare and other critical applications.
Technical Explanation
The paper presents a comprehensive evaluation of retrieval-augmented large language models (RALMs) in the context of biomedical natural language processing (NLP) tasks. RALMs, such as RAG and BiomedRAG, combine large language models with information retrieval systems to enhance their knowledge and capabilities.
The researchers assess the performance of RALMs on a range of biomedical tasks, including question answering, summarization, and text generation. They also evaluate the models' robustness to distributional shift, where the input data differs from the training data, as well as their self-awareness, or ability to recognize when they are uncertain or may have made a mistake.
The experiments demonstrate that RALMs generally outperform standalone large language models on the biomedical tasks, highlighting the benefits of the retrieval-augmented approach. However, the models still exhibit some vulnerabilities, such as reduced performance on out-of-distribution data and limited self-awareness in certain scenarios.
The findings of this paper contribute to the ongoing efforts to develop more reliable and transparent AI systems for critical applications, such as healthcare and medical decision-making. The insights provided can inform future research and development to make retrieval-augmented language models more robust and self-aware.
Critical Analysis
The paper provides a thorough and well-designed evaluation of retrieval-augmented large language models in the biomedical domain. The researchers have carefully considered various aspects of the models' performance, including their application, robustness, and self-awareness.
One potential limitation of the study is the reliance on a limited set of biomedical datasets and tasks. While the chosen tasks are representative of common biomedical NLP challenges, expanding the evaluation to a broader range of datasets and applications could further strengthen the conclusions.
Additionally, the paper does not delve deeply into the specific mechanisms or architectural choices that contribute to the performance differences between standalone language models and retrieval-augmented models. A more detailed analysis of the inner workings of these models could provide valuable insights for future model development and optimization.
Nevertheless, the findings of this research are highly relevant and timely, given the growing importance of reliable and trustworthy AI systems in the biomedical domain. The insights provided can help guide the development of next-generation retrieval-augmented language models that are more robust, self-aware, and suitable for real-world deployment in critical applications.
Conclusion
This paper presents a comprehensive evaluation of retrieval-augmented large language models (RALMs) in the context of biomedical natural language processing. The results demonstrate the advantages of the retrieval-augmented approach, with RALMs outperforming standalone language models on a range of tasks, including question answering and summarization.
However, the study also highlights the need for further advancements to improve the robustness and self-awareness of these models. As AI systems become increasingly prevalent in healthcare and other critical domains, ensuring their reliability and transparency is of paramount importance.
The insights provided in this paper can inform the ongoing research and development of more reliable and trustworthy AI systems for biomedical applications. By continuing to study the strengths and limitations of retrieval-augmented language models, researchers can work towards making them more robust to distribution shifts and better able to recognize the boundaries of their own knowledge and capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking Retrieval-Augmented Large Language Models in Biomedical NLP: Application, Robustness, and Self-Awareness
Mingchen Li, Zaifu Zhan, Han Yang, Yongkang Xiao, Jiatan Huang, Rui Zhang
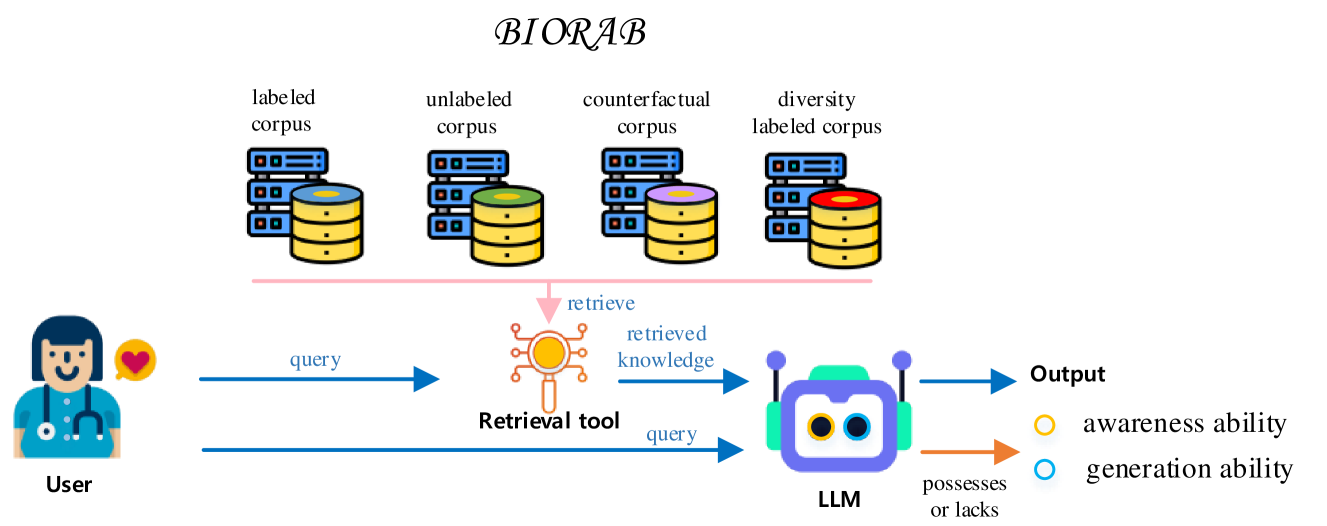
Large language models (LLM) have demonstrated remarkable capabilities in various biomedical natural language processing (NLP) tasks, leveraging the demonstration within the input context to adapt to new tasks. However, LLM is sensitive to the selection of demonstrations. To address the hallucination issue inherent in LLM, retrieval-augmented LLM (RAL) offers a solution by retrieving pertinent information from an established database. Nonetheless, existing research work lacks rigorous evaluation of the impact of retrieval-augmented large language models on different biomedical NLP tasks. This deficiency makes it challenging to ascertain the capabilities of RAL within the biomedical domain. Moreover, the outputs from RAL are affected by retrieving the unlabeled, counterfactual, or diverse knowledge that is not well studied in the biomedical domain. However, such knowledge is common in the real world. Finally, exploring the self-awareness ability is also crucial for the RAL system. So, in this paper, we systematically investigate the impact of RALs on 5 different biomedical tasks (triple extraction, link prediction, classification, question answering, and natural language inference). We analyze the performance of RALs in four fundamental abilities, including unlabeled robustness, counterfactual robustness, diverse robustness, and negative awareness. To this end, we proposed an evaluation framework to assess the RALs' performance on different biomedical NLP tasks and establish four different testbeds based on the aforementioned fundamental abilities. Then, we evaluate 3 representative LLMs with 3 different retrievers on 5 tasks over 9 datasets.
Read more5/17/2024

155
Improving Retrieval Augmented Language Model with Self-Reasoning
Yuan Xia, Jingbo Zhou, Zhenhui Shi, Jun Chen, Haifeng Huang
The Retrieval-Augmented Language Model (RALM) has shown remarkable performance on knowledge-intensive tasks by incorporating external knowledge during inference, which mitigates the factual hallucinations inherited in large language models (LLMs). Despite these advancements, challenges persist in the implementation of RALMs, particularly concerning their reliability and traceability. To be specific, the irrelevant document retrieval may result in unhelpful response generation or even deteriorate the performance of LLMs, while the lack of proper citations in generated outputs complicates efforts to verify the trustworthiness of the models. To this end, we propose a novel self-reasoning framework aimed at improving the reliability and traceability of RALMs, whose core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. We have evaluated our framework across four public datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset) to demonstrate the superiority of our method, which can outperform existing state-of-art models and can achieve comparable performance with GPT-4, while only using 2,000 training samples.
Read more8/6/2024
0
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
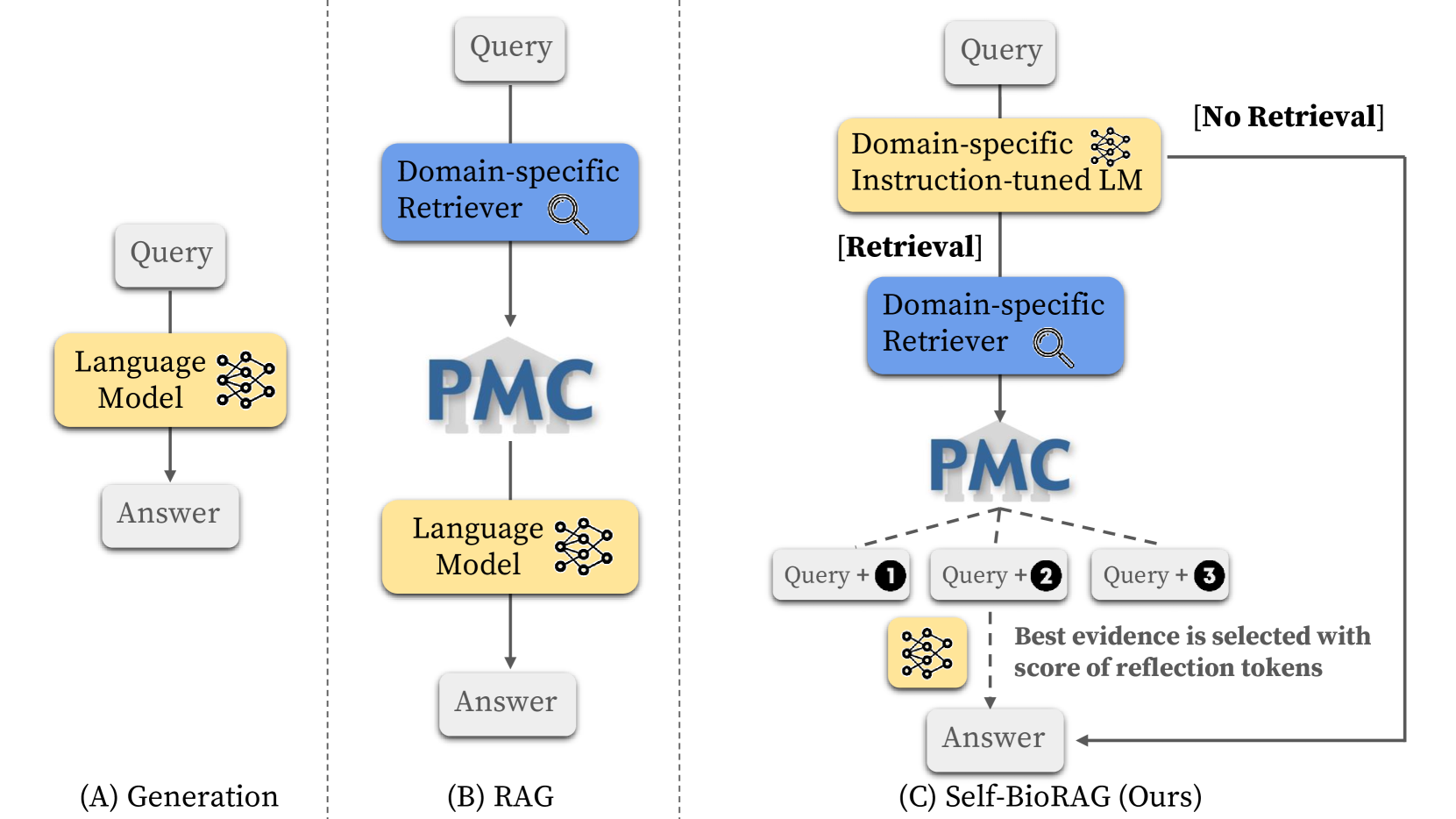
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
Read more6/19/2024
💬
0
BiomedRAG: A Retrieval Augmented Large Language Model for Biomedicine
Mingchen Li, Halil Kilicoglu, Hua Xu, Rui Zhang
Large Language Models (LLMs) have swiftly emerged as vital resources for different applications in the biomedical and healthcare domains; however, these models encounter issues such as generating inaccurate information or hallucinations. Retrieval-augmented generation provided a solution for these models to update knowledge and enhance their performance. In contrast to previous retrieval-augmented LMs, which utilize specialized cross-attention mechanisms to help LLM encode retrieved text, BiomedRAG adopts a simpler approach by directly inputting the retrieved chunk-based documents into the LLM. This straightforward design is easily applicable to existing retrieval and language models, effectively bypassing noise information in retrieved documents, particularly in noise-intensive tasks. Moreover, we demonstrate the potential for utilizing the LLM to supervise the retrieval model in the biomedical domain, enabling it to retrieve the document that assists the LM in improving its predictions. Our experiments reveal that with the tuned scorer,textsc{ BiomedRAG} attains superior performance across 5 biomedical NLP tasks, encompassing information extraction (triple extraction, relation extraction), text classification, link prediction, and question-answering, leveraging over 9 datasets. For instance, in the triple extraction task, textsc{BiomedRAG} outperforms other triple extraction systems with micro-F1 scores of 81.42 and 88.83 on GIT and ChemProt corpora, respectively.
Read more5/6/2024