EE-TTS: Emphatic Expressive TTS with Linguistic Information
2305.12107
0
0
💬
Abstract
While Current TTS systems perform well in synthesizing high-quality speech, producing highly expressive speech remains a challenge. Emphasis, as a critical factor in determining the expressiveness of speech, has attracted more attention nowadays. Previous works usually enhance the emphasis by adding intermediate features, but they can not guarantee the overall expressiveness of the speech. To resolve this matter, we propose Emphatic Expressive TTS (EE-TTS), which leverages multi-level linguistic information from syntax and semantics. EE-TTS contains an emphasis predictor that can identify appropriate emphasis positions from text and a conditioned acoustic model to synthesize expressive speech with emphasis and linguistic information. Experimental results indicate that EE-TTS outperforms baseline with MOS improvements of 0.49 and 0.67 in expressiveness and naturalness. EE-TTS also shows strong generalization across different datasets according to AB test results.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Current text-to-speech (TTS) systems can produce high-quality speech, but generating highly expressive speech remains a challenge.
- Emphasis, a crucial factor in expressive speech, has received more attention recently.
- Previous methods have tried to enhance emphasis by adding intermediate features, but they couldn't guarantee overall speech expressiveness.
- To address this, the researchers propose Emphatic Expressive TTS (EE-TTS), which leverages multi-level linguistic information from syntax and semantics.
Plain English Explanation
The paper discusses the challenge of creating text-to-speech (TTS) systems that can produce highly expressive and natural-sounding speech. One key aspect of expressive speech is emphasis - the way certain words or syllables are stressed or highlighted.
Previous approaches have tried to enhance emphasis by adding additional features to the TTS model, but they couldn't guarantee that the overall speech would sound truly expressive and natural. To solve this problem, the researchers developed a new TTS system called EE-TTS.
EE-TTS uses linguistic information from the text, including syntax (grammatical structure) and semantics (meaning), to predict where emphasis should be placed. It then conditions the acoustic model to synthesize speech that incorporates this emphasis in a natural and expressive way. The idea is that by considering the deeper linguistic context, EE-TTS can produce speech that sounds more human-like and emotionally engaging.
Technical Explanation
The Emphatic Expressive TTS (EE-TTS) system proposed in the paper consists of two main components:
-
Emphasis Predictor: This module analyzes the input text and identifies the appropriate positions for emphasis. It leverages linguistic information at the syntactic and semantic levels to determine where certain words or syllables should be stressed.
-
Conditioned Acoustic Model: This is the speech synthesis component of the system. It takes the text input along with the emphasis predictions from the first module and generates the final expressive speech output.
The key innovation of EE-TTS is its ability to integrate multi-level linguistic knowledge to enhance the expressiveness of the synthesized speech. By considering both the grammatical structure and the meaning of the text, the system can produce speech that sounds more natural and human-like, with appropriate emphasis and intonation.
Experimental results show that EE-TTS outperforms baseline TTS systems in terms of both expressiveness and overall naturalness, with mean opinion score (MOS) improvements of 0.49 and 0.67, respectively. The system also demonstrates strong generalization capabilities, performing well across different datasets according to the researchers' AB testing.
Critical Analysis
The paper presents a promising approach to improving the expressiveness of TTS systems, but there are a few potential limitations and areas for further research:
-
Dependency on Linguistic Analysis: EE-TTS relies heavily on the accuracy of its linguistic analysis, particularly the syntactic and semantic parsing of the input text. If these underlying natural language processing components are not robust, it could negatively impact the system's ability to predict emphasis correctly.
-
Generalization to Diverse Linguistic Contexts: While the paper shows strong generalization across datasets, it's unclear how well EE-TTS would perform in handling highly complex or unconventional linguistic structures, such as those found in poetry, jokes, or casual conversational speech.
-
Evaluation Metrics: The paper primarily uses subjective mean opinion scores to assess the system's performance. Incorporating more objective, quantitative metrics, such as prior-agnostic multi-scale contrastive text-audio evaluation or open-vocabulary keyword spotting, could provide additional insights into the system's capabilities and limitations.
-
Robustness to Noise and Distortion: The paper does not explore how well EE-TTS performs in the presence of background noise, audio compression, or other real-world distortions that can affect the perceived quality and expressiveness of the synthesized speech.
-
Integration with Robust Codec Language Modeling: Exploring ways to combine EE-TTS with advanced language modeling techniques could further enhance the system's ability to generate coherent, contextually appropriate, and expressive speech.
Conclusion
The Emphatic Expressive TTS (EE-TTS) system proposed in this paper represents an important step forward in the quest to create text-to-speech systems that can generate highly expressive and natural-sounding speech. By leveraging multi-level linguistic information, EE-TTS is able to produce speech with appropriate emphasis and intonation, resulting in significant improvements in both expressiveness and overall naturalness.
While the paper highlights the potential of this approach, further research is needed to address the system's dependence on linguistic analysis, ensure robust performance in diverse contexts, and explore integration with advanced language modeling techniques. Nonetheless, the insights and techniques presented in this work offer a promising direction for the continued development of more expressive and engaging text-to-speech technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
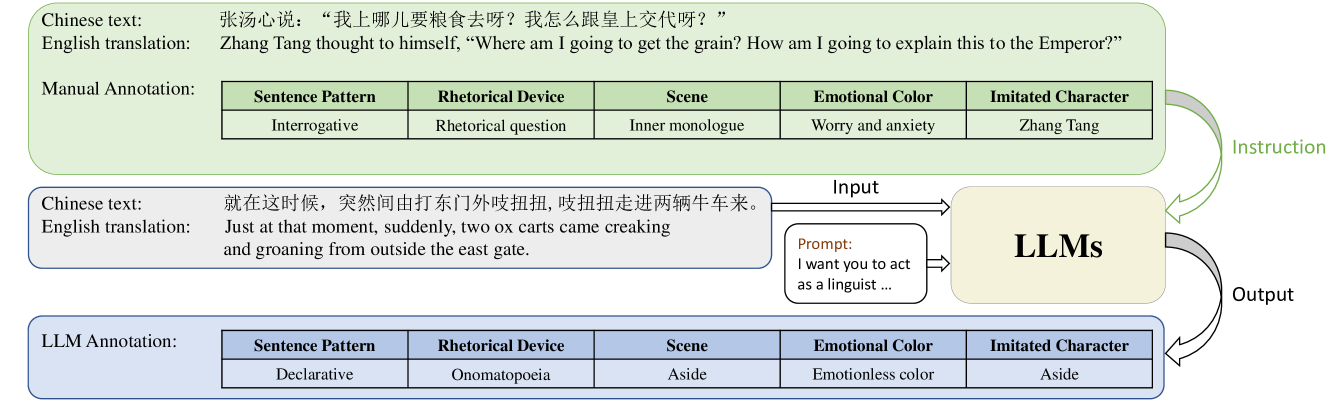
StoryTTS: A Highly Expressive Text-to-Speech Dataset with Rich Textual Expressiveness Annotations
Sen Liu, Yiwei Guo, Xie Chen, Kai Yu
0
0
While acoustic expressiveness has long been studied in expressive text-to-speech (ETTS), the inherent expressiveness in text lacks sufficient attention, especially for ETTS of artistic works. In this paper, we introduce StoryTTS, a highly ETTS dataset that contains rich expressiveness both in acoustic and textual perspective, from the recording of a Mandarin storytelling show. A systematic and comprehensive labeling framework is proposed for textual expressiveness. We analyze and define speech-related textual expressiveness in StoryTTS to include five distinct dimensions through linguistics, rhetoric, etc. Then we employ large language models and prompt them with a few manual annotation examples for batch annotation. The resulting corpus contains 61 hours of consecutive and highly prosodic speech equipped with accurate text transcriptions and rich textual expressiveness annotations. Therefore, StoryTTS can aid future ETTS research to fully mine the abundant intrinsic textual and acoustic features. Experiments are conducted to validate that TTS models can generate speech with improved expressiveness when integrating with the annotated textual labels in StoryTTS.
4/24/2024
❗
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Xiang Li, Zhi-Qi Cheng, Jun-Yan He, Xiaojiang Peng, Alexander G. Hauptmann
0
0
Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily relying on oversimplified emotional labels or single-modality inputs. To address these limitations, we propose the Multimodal Emotional Text-to-Speech System (MM-TTS), a unified framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. MM-TTS consists of two key components: (1) the Emotion Prompt Alignment Module (EP-Align), which employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information; and (2) the Emotion Embedding-Induced TTS (EMI-TTS), which integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations across diverse datasets demonstrate the superior performance of MM-TTS compared to traditional E-TTS models. Objective metrics, including Word Error Rate (WER) and Character Error Rate (CER), show significant improvements on ESD dataset, with MM-TTS achieving scores of 7.35% and 3.07%, respectively. Subjective assessments further validate that MM-TTS generates speech with emotional fidelity and naturalness comparable to human speech. Our code and pre-trained models are publicly available at https://anonymous.4open.science/r/MMTTS-D214
4/30/2024
🗣️
Boosting Multi-Speaker Expressive Speech Synthesis with Semi-supervised Contrastive Learning
Xinfa Zhu, Yuke Li, Yi Lei, Ning Jiang, Guoqing Zhao, Lei Xie
0
0
This paper aims to build a multi-speaker expressive TTS system, synthesizing a target speaker's speech with multiple styles and emotions. To this end, we propose a novel contrastive learning-based TTS approach to transfer style and emotion across speakers. Specifically, contrastive learning from different levels, i.e. utterance and category level, is leveraged to extract the disentangled style, emotion, and speaker representations from speech for style and emotion transfer. Furthermore, a semi-supervised training strategy is introduced to improve the data utilization efficiency by involving multi-domain data, including style-labeled data, emotion-labeled data, and abundant unlabeled data. To achieve expressive speech with diverse styles and emotions for a target speaker, the learned disentangled representations are integrated into an improved VITS model. Experiments on multi-domain data demonstrate the effectiveness of the proposed method.
4/26/2024
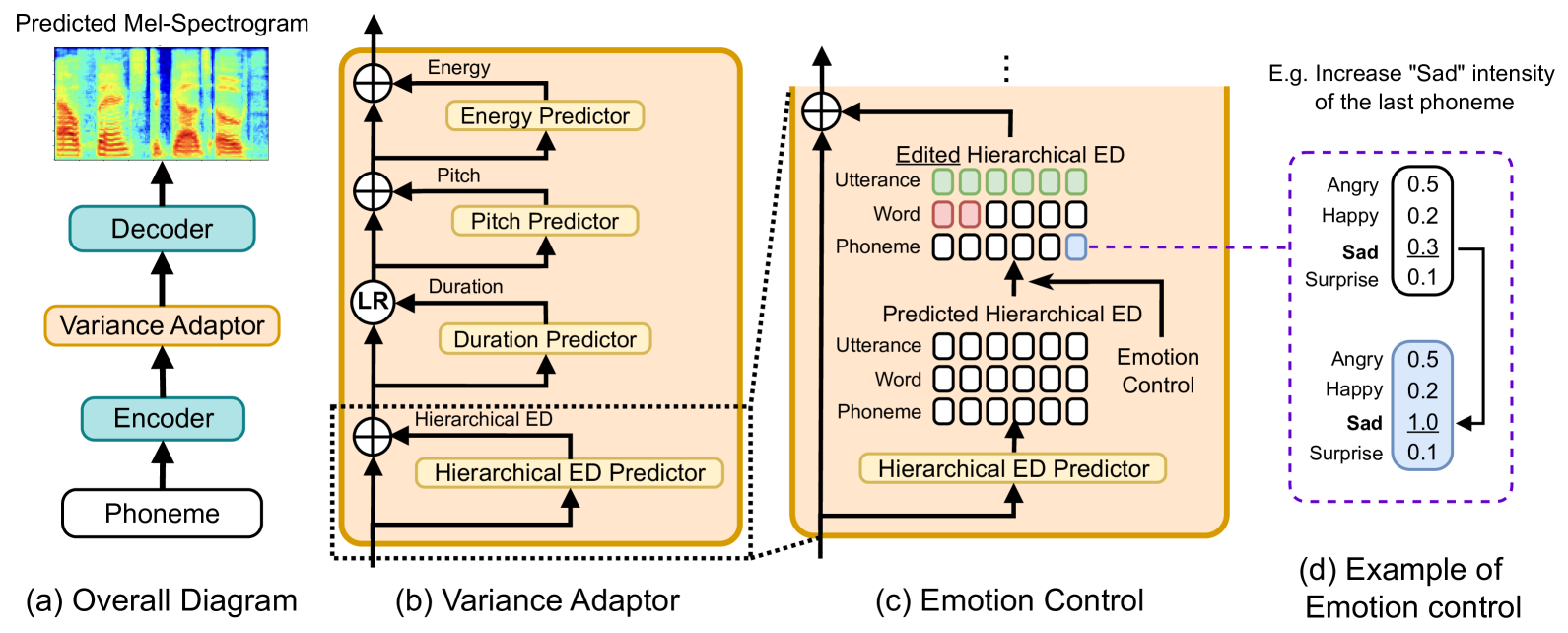
Hierarchical Emotion Prediction and Control in Text-to-Speech Synthesis
Sho Inoue, Kun Zhou, Shuai Wang, Haizhou Li
0
0
It remains a challenge to effectively control the emotion rendering in text-to-speech (TTS) synthesis. Prior studies have primarily focused on learning a global prosodic representation at the utterance level, which strongly correlates with linguistic prosody. Our goal is to construct a hierarchical emotion distribution (ED) that effectively encapsulates intensity variations of emotions at various levels of granularity, encompassing phonemes, words, and utterances. During TTS training, the hierarchical ED is extracted from the ground-truth audio and guides the predictor to establish a connection between emotional and linguistic prosody. At run-time inference, the TTS model generates emotional speech and, at the same time, provides quantitative control of emotion over the speech constituents. Both objective and subjective evaluations validate the effectiveness of the proposed framework in terms of emotion prediction and control.
5/16/2024