ArzEn-LLM: Code-Switched Egyptian Arabic-English Translation and Speech Recognition Using LLMs

0
Sign in to get full access
Overview
- The paper proposes ArzEn-LLM, a system for code-switched Egyptian Arabic-English translation and speech recognition using large language models (LLMs).
- It aims to enhance the multilingual abilities of LLMs for tasks involving code-switching, which is common in conversational speech in many regions.
- The system is evaluated on several datasets for translation and speech recognition, showing improved performance over existing approaches.
Plain English Explanation
The paper introduces a new system called ArzEn-LLM that is designed to work with code-switched language, which is a common way of speaking where people mix two or more languages in the same conversation. In this case, the system focuses on translating and recognizing speech that combines Egyptian Arabic and English.
The researchers used large language models (LLMs) - powerful AI systems trained on huge amounts of text data - to build ArzEn-LLM. The goal was to enhance the ability of these LLMs to handle code-switching, which can be challenging for conventional translation and speech recognition systems.
The paper evaluates ArzEn-LLM on several datasets for translation and speech recognition tasks involving Egyptian Arabic and English. The results show that the system outperforms existing approaches, indicating that it is better able to understand and process code-switched language.
Technical Explanation
The paper proposes the ArzEn-LLM system for code-switched Egyptian Arabic-English translation and speech recognition using large language models (LLMs).
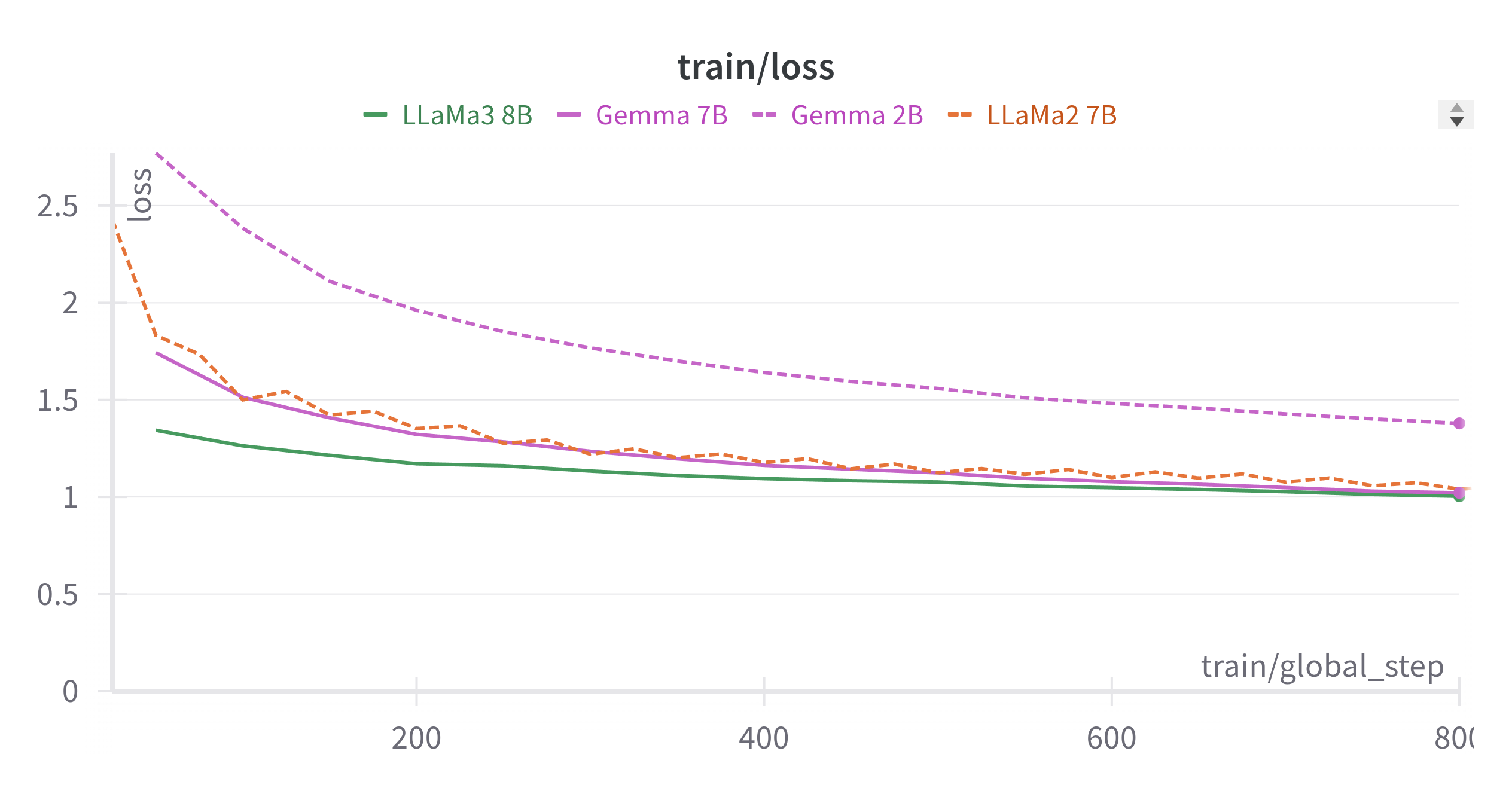
The system is designed to enhance the multilingual abilities of LLMs for tasks involving code-switching, which is common in conversational speech in many regions. The authors evaluate ArzEn-LLM on several datasets for translation and speech recognition, including the CoVoSWITCH and GHADAR datasets.
The experiments show that ArzEn-LLM outperforms existing approaches, demonstrating improved performance on code-switched Egyptian Arabic-English translation and speech recognition tasks. The authors attribute this to the system's ability to effectively leverage the multilingual capabilities of LLMs.
Critical Analysis
The paper provides a valuable contribution by addressing the challenge of code-switching, which is an important real-world phenomenon that can hinder the performance of language technologies. The authors' focus on enhancing LLMs to handle code-switched language is a promising direction.
However, the paper does not discuss potential limitations or caveats of the ArzEn-LLM system. For example, it is unclear how the system would perform on code-switching patterns or language pairs beyond Egyptian Arabic and English. Additionally, the paper does not explore the system's robustness to noisy or disfluent input, which can be common in conversational speech.
Further research could investigate the generalizability of the ArzEn-LLM approach to other code-switching scenarios, as well as its performance on more diverse and realistic datasets. Exploring the interpretability and explainability of the system's code-switching capabilities could also provide valuable insights.
Conclusion
The ArzEn-LLM system proposed in this paper represents a significant advancement in the field of code-switched language processing. By leveraging the power of large language models, the system demonstrates improved performance on translation and speech recognition tasks involving Egyptian Arabic and English code-switching.
This research highlights the importance of addressing real-world language phenomena, such as code-switching, in order to develop more robust and inclusive language technologies. The success of ArzEn-LLM suggests that further advancements in this area could have widespread benefits, particularly for applications in multilingual and diverse communication contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ArzEn-LLM: Code-Switched Egyptian Arabic-English Translation and Speech Recognition Using LLMs
Ahmed Heakl, Youssef Zaghloul, Mennatullah Ali, Rania Hossam, Walid Gomaa
Motivated by the widespread increase in the phenomenon of code-switching between Egyptian Arabic and English in recent times, this paper explores the intricacies of machine translation (MT) and automatic speech recognition (ASR) systems, focusing on translating code-switched Egyptian Arabic-English to either English or Egyptian Arabic. Our goal is to present the methodologies employed in developing these systems, utilizing large language models such as LLama and Gemma. In the field of ASR, we explore the utilization of the Whisper model for code-switched Egyptian Arabic recognition, detailing our experimental procedures including data preprocessing and training techniques. Through the implementation of a consecutive speech-to-text translation system that integrates ASR with MT, we aim to overcome challenges posed by limited resources and the unique characteristics of the Egyptian Arabic dialect. Evaluation against established metrics showcases promising results, with our methodologies yielding a significant improvement of $56%$ in English translation over the state-of-the-art and $9.3%$ in Arabic translation. Since code-switching is deeply inherent in spoken languages, it is crucial that ASR systems can effectively handle this phenomenon. This capability is crucial for enabling seamless interaction in various domains, including business negotiations, cultural exchanges, and academic discourse. Our models and code are available as open-source resources. Code: url{http://github.com/ahmedheakl/arazn-llm}}, Models: url{http://huggingface.co/collections/ahmedheakl/arazn-llm-662ceaf12777656607b9524e}.
Read more7/16/2024
0
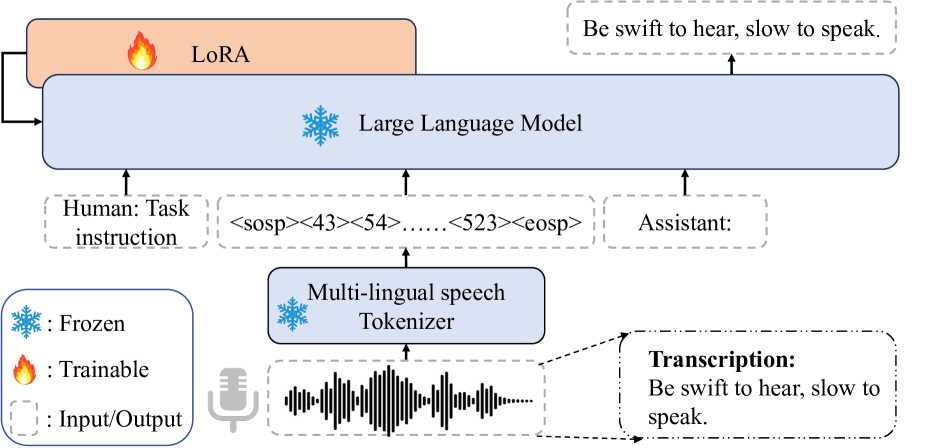
Enhancing Multilingual Speech Generation and Recognition Abilities in LLMs with Constructed Code-switched Data
Jing Xu, Daxin Tan, Jiaqi Wang, Xiao Chen
While large language models (LLMs) have been explored in the speech domain for both generation and recognition tasks, their applications are predominantly confined to the monolingual scenario, with limited exploration in multilingual and code-switched (CS) contexts. Additionally, speech generation and recognition tasks are often handled separately, such as VALL-E and Qwen-Audio. In this paper, we propose a MutltiLingual MultiTask (MLMT) model, integrating multilingual speech generation and recognition tasks within the single LLM. Furthermore, we develop an effective data construction approach that splits and concatenates words from different languages to equip LLMs with CS synthesis ability without relying on CS data. The experimental results demonstrate that our model outperforms other baselines with a comparable data scale. Furthermore, our data construction approach not only equips LLMs with CS speech synthesis capability with comparable speaker consistency and similarity to any given speaker, but also improves the performance of LLMs in multilingual speech generation and recognition tasks.
Read more9/18/2024

0
Boosting Code-Switching ASR with Mixture of Experts Enhanced Speech-Conditioned LLM
Fengrun Zhang, Wang Geng, Hukai Huang, Cheng Yi, He Qu
In this paper, we introduce a speech-conditioned Large Language Model (LLM) integrated with a Mixture of Experts (MoE) based connector to address the challenge of Code-Switching (CS) in Automatic Speech Recognition (ASR). Specifically, we propose an Insertion and Deletion of Interruption Token (IDIT) mechanism for better transfer text generation ability of LLM to speech recognition task. We also present a connecter with MoE architecture that manages multiple languages efficiently. To further enhance the collaboration of multiple experts and leverage the understanding capabilities of LLM, we propose a two-stage progressive training strategy: 1) The connector is unfrozen and trained with language-specialized experts to map speech representations to the text space. 2) The connector and LLM LoRA adaptor are trained with the proposed IDIT mechanism and all experts are activated to learn general representations. Experimental results demonstrate that our method significantly outperforms state-of-the-art models, including end-to-end and large-scale audio-language models.
Read more9/25/2024
0
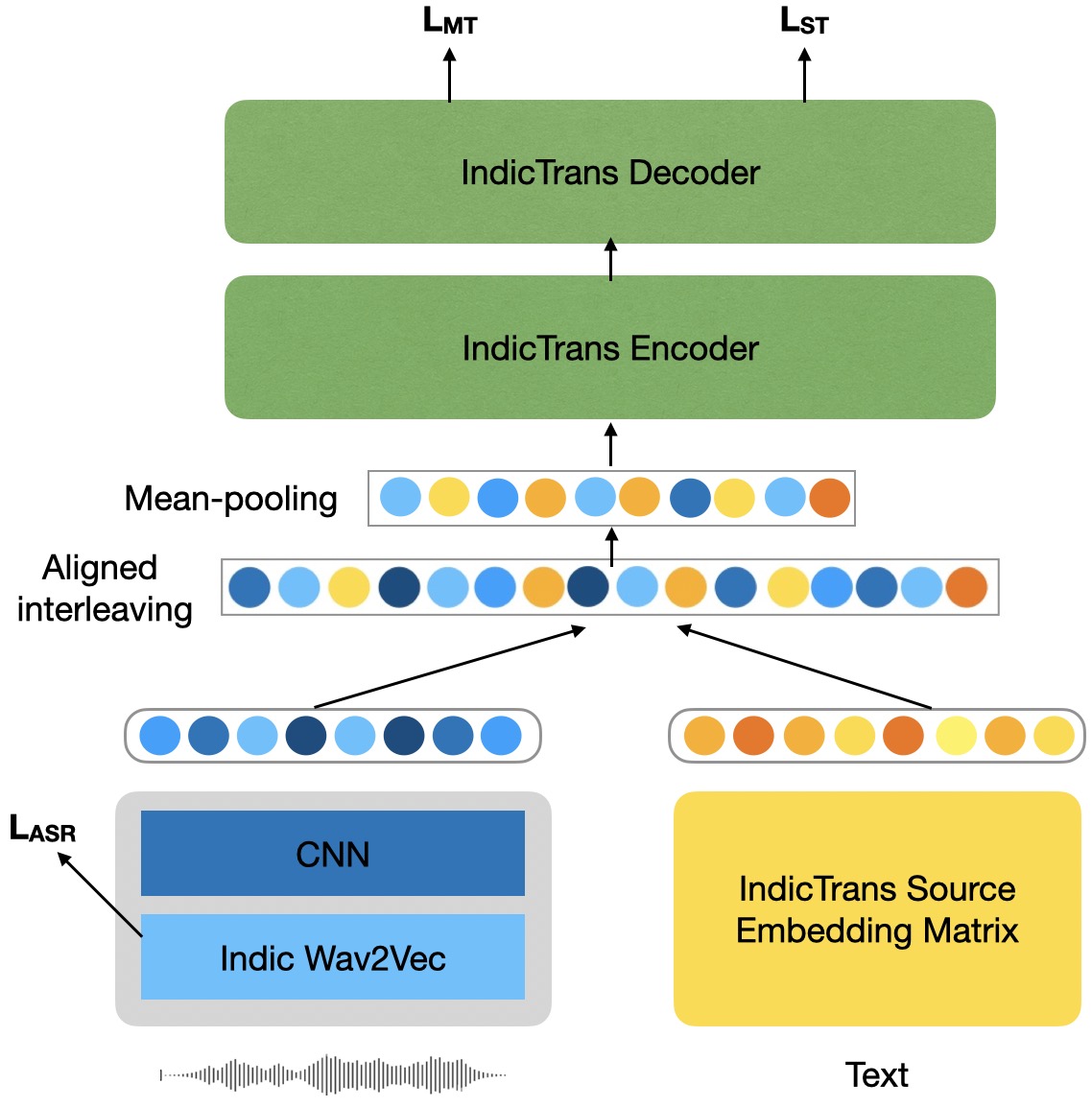
CoSTA: Code-Switched Speech Translation using Aligned Speech-Text Interleaving
Bhavani Shankar, Preethi Jyothi, Pushpak Bhattacharyya
Code-switching is a widely prevalent linguistic phenomenon in multilingual societies like India. Building speech-to-text models for code-switched speech is challenging due to limited availability of datasets. In this work, we focus on the problem of spoken translation (ST) of code-switched speech in Indian languages to English text. We present a new end-to-end model architecture COSTA that scaffolds on pretrained automatic speech recognition (ASR) and machine translation (MT) modules (that are more widely available for many languages). Speech and ASR text representations are fused using an aligned interleaving scheme and are fed further as input to a pretrained MT module; the whole pipeline is then trained end-to-end for spoken translation using synthetically created ST data. We also release a new evaluation benchmark for code-switched Bengali-English, Hindi-English, Marathi-English and Telugu- English speech to English text. COSTA significantly outperforms many competitive cascaded and end-to-end multimodal baselines by up to 3.5 BLEU points.
Read more6/18/2024