Enhancing Multilingual Speech Generation and Recognition Abilities in LLMs with Constructed Code-switched Data

0
Sign in to get full access
Overview
- Examines methods for enhancing multilingual speech generation and recognition in large language models (LLMs)
- Proposes constructing code-switched speech data to improve LLM performance on these tasks
- Evaluates the effectiveness of this approach through experiments on text-to-speech (TTS) synthesis and automatic speech recognition (ASR)
Plain English Explanation
This research paper looks at ways to improve the ability of large language models (LLMs) to handle multiple languages in speech-related tasks. The key idea is to create artificial data that mixes different languages - a technique called "code-switching" - and use this to train the LLMs.
The researchers wanted to see if training LLMs on this code-switched speech data could enhance their performance in two important areas: text-to-speech (TTS) synthesis, which turns text into spoken audio, and automatic speech recognition (ASR), which converts speech into text.
By bridging the language gap and exposing the LLMs to a wider range of multilingual speech patterns, the hope was that they would become better at transforming LLMs into cross-modal and cross-lingual capabilities.
Technical Explanation
The researchers first constructed a code-switched speech dataset by taking speech samples in different languages and artificially combining them. This involved techniques like voice conversion, speech mixing, and data augmentation.
They then trained LLMs on this constructed dataset and evaluated their performance on multilingual TTS and ASR tasks. The TTS experiments involved generating speech audio from text in multiple languages, while the ASR experiments looked at transcribing multilingual speech into text.
The results showed that the LLMs trained on the code-switched data significantly outperformed models trained on monolingual data, demonstrating the effectiveness of this approach for enhancing multilingual speech abilities. The researchers attribute this to the LLMs learning to better handle language switching and leveraging cross-lingual knowledge.
Critical Analysis
The paper acknowledges that the constructed code-switched data may not fully capture the nuances and complexities of natural code-switching behavior. Further research is needed to explore more realistic data generation methods and their impact on model performance.
Additionally, the experiments were conducted on a limited set of languages, so the generalizability of the findings to a broader range of language pairs is unclear. Expanding the evaluation to a more diverse set of languages would help validate the robustness of the approach.
Another potential limitation is that the paper does not assess the quality or naturalness of the generated multilingual speech, which is an important consideration for real-world TTS applications. Future work could incorporate human evaluation metrics to provide a more comprehensive assessment.
Conclusion
This research demonstrates a promising approach for improving the multilingual speech generation and recognition capabilities of large language models. By constructing code-switched speech data and using it to train the models, the researchers were able to significantly enhance the LLMs' performance on these tasks.
The findings have potential implications for building more versatile and inclusive speech-based AI systems that can effectively handle the linguistic diversity encountered in real-world applications. Further advancements in this area could help bridge language barriers and foster more accessible and equitable communication technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Enhancing Multilingual Speech Generation and Recognition Abilities in LLMs with Constructed Code-switched Data
Jing Xu, Daxin Tan, Jiaqi Wang, Xiao Chen
While large language models (LLMs) have been explored in the speech domain for both generation and recognition tasks, their applications are predominantly confined to the monolingual scenario, with limited exploration in multilingual and code-switched (CS) contexts. Additionally, speech generation and recognition tasks are often handled separately, such as VALL-E and Qwen-Audio. In this paper, we propose a MutltiLingual MultiTask (MLMT) model, integrating multilingual speech generation and recognition tasks within the single LLM. Furthermore, we develop an effective data construction approach that splits and concatenates words from different languages to equip LLMs with CS synthesis ability without relying on CS data. The experimental results demonstrate that our model outperforms other baselines with a comparable data scale. Furthermore, our data construction approach not only equips LLMs with CS speech synthesis capability with comparable speaker consistency and similarity to any given speaker, but also improves the performance of LLMs in multilingual speech generation and recognition tasks.
Read more9/18/2024
💬
0
Semi-supervised Learning for Code-Switching ASR with Large Language Model Filter
Yu Xi, Wen Ding, Kai Yu, Junjie Lai
Code-switching (CS) phenomenon occurs when words or phrases from different languages are alternated in a single sentence. Due to data scarcity, building an effective CS Automatic Speech Recognition (ASR) system remains challenging. In this paper, we propose to enhance CS-ASR systems by utilizing rich unsupervised monolingual speech data within a semi-supervised learning framework, particularly when access to CS data is limited. To achieve this, we establish a general paradigm for applying noisy student training (NST) to the CS-ASR task. Specifically, we introduce the LLM-Filter, which leverages well-designed prompt templates to activate the correction capability of large language models (LLMs) for monolingual data selection and pseudo-labels refinement during NST. Our experiments on the supervised ASRU-CS and unsupervised AISHELL-2 and LibriSpeech datasets show that our method not only achieves significant improvements over supervised and semi-supervised learning baselines for the CS task, but also attains better performance compared with the fully-supervised oracle upper-bound on the CS English part. Additionally, we further investigate the influence of accent on AESRC dataset and demonstrate that our method can get achieve additional benefits when the monolingual data contains relevant linguistic characteristic.
Read more7/8/2024

0
Bridging the Language Gap: Enhancing Multilingual Prompt-Based Code Generation in LLMs via Zero-Shot Cross-Lingual Transfer
Mingda Li, Abhijit Mishra, Utkarsh Mujumdar
The use of Large Language Models (LLMs) for program code generation has gained substantial attention, but their biases and limitations with non-English prompts challenge global inclusivity. This paper investigates the complexities of multilingual prompt-based code generation. Our evaluations of LLMs, including CodeLLaMa and CodeGemma, reveal significant disparities in code quality for non-English prompts; we also demonstrate the inadequacy of simple approaches like prompt translation, bootstrapped data augmentation, and fine-tuning. To address this, we propose a zero-shot cross-lingual approach using a neural projection technique, integrating a cross-lingual encoder like LASER artetxe2019massively to map multilingual embeddings from it into the LLM's token space. This method requires training only on English data and scales effectively to other languages. Results on a translated and quality-checked MBPP dataset show substantial improvements in code quality. This research promotes a more inclusive code generation landscape by empowering LLMs with multilingual capabilities to support the diverse linguistic spectrum in programming.
Read more8/20/2024
0
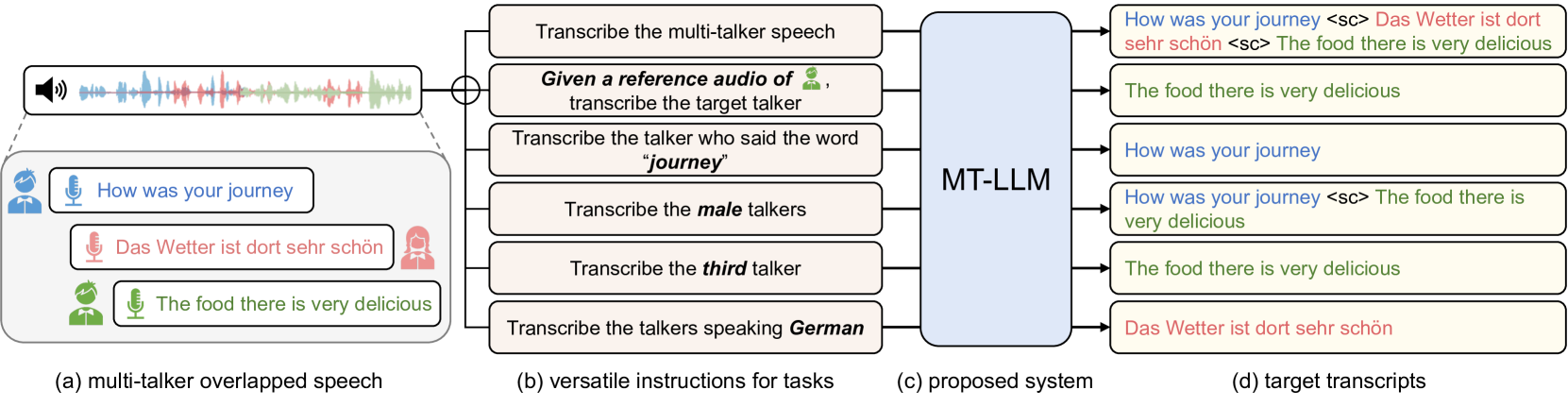
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024