AsCL: An Asymmetry-sensitive Contrastive Learning Method for Image-Text Retrieval with Cross-Modal Fusion

0
Sign in to get full access
Overview
- This paper proposes a new method called AsCL (Asymmetry-sensitive Contrastive Learning) for improving image-text retrieval performance.
- AsCL addresses the information asymmetry between visual and textual modalities by incorporating an asymmetry-sensitive contrastive learning objective.
- The method also includes a cross-modal fusion module to further enhance the joint representation learning of images and text.
Plain English Explanation
Image-text retrieval is the task of finding relevant images for a given text query, or vice versa. This is an important problem with applications in areas like visual search and multimodal information understanding. However, there is often an inherent "information asymmetry" between images and text - images can convey rich visual information that is difficult to capture in text, while text can express complex semantic concepts not easily translated to visual form.
AsCL: An Asymmetry-sensitive Contrastive Learning Method for Image-Text Retrieval with Cross-Modal Fusion proposes a new approach to address this challenge. The key idea is to use an "asymmetry-sensitive" contrastive learning objective, which accounts for the differences in information content between the visual and textual modalities. This helps the model learn better joint representations that can effectively bridge the gap between images and text.
Additionally, the method incorporates a cross-modal fusion module to further enhance the joint representation learning. This allows the model to more effectively combine and leverage the complementary information from both modalities.
The authors demonstrate that AsCL outperforms previous state-of-the-art methods on several image-text retrieval benchmarks, showing the benefits of the asymmetry-sensitive contrastive learning approach and the cross-modal fusion module.
Technical Explanation
The key technical contributions of this paper are:
-
Asymmetry-sensitive Contrastive Learning (AsCL): The authors propose a novel contrastive learning objective that accounts for the information asymmetry between visual and textual modalities. Specifically, it encourages the model to learn representations where the distance between a relevant image-text pair is smaller than the distance between the image and irrelevant text (or vice versa), with a larger margin for image-text pairs with greater information asymmetry.
-
Cross-Modal Fusion: The paper introduces a cross-modal fusion module that combines the visual and textual representations in a learnable way, allowing the model to effectively leverage the complementary information from both modalities.
-
Evaluation on Image-Text Retrieval Benchmarks: The authors evaluate AsCL on several standard image-text retrieval datasets, including [object Object], [object Object], and [object Object]. The results demonstrate the effectiveness of the proposed approach compared to previous state-of-the-art methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the AsCL method, with comprehensive comparisons to various baselines on multiple datasets. The authors also discuss potential limitations and future research directions, such as exploring different fusion strategies and applying the method to other cross-modal tasks.
One potential concern is the computational complexity of the asymmetry-sensitive contrastive learning objective, which may be more expensive to train than simpler contrastive losses. The authors do not provide a detailed analysis of the training time or computational requirements of their method.
Additionally, while the cross-modal fusion module is a valuable contribution, the specific implementation details and design choices are not extensively discussed. Further exploration of alternative fusion strategies and their impact on performance could provide additional insights.
Overall, the AsCL method offers a promising approach to address the information asymmetry in image-text retrieval, and the authors have made a significant contribution to the field. The critical analysis suggests avenues for further research and refinement of the technique.
Conclusion
This paper presents a novel Asymmetry-sensitive Contrastive Learning (AsCL) method for improving image-text retrieval performance. The key innovations include an asymmetry-sensitive contrastive learning objective and a cross-modal fusion module, which together help the model learn better joint representations that can effectively bridge the gap between visual and textual modalities.
The comprehensive evaluation on multiple benchmarks demonstrates the effectiveness of the proposed approach, outperforming previous state-of-the-art methods. The critical analysis highlights potential areas for future research, such as exploring alternative fusion strategies and further optimizing the computational complexity of the training process.
Overall, the AsCL method represents an important step forward in addressing the information asymmetry challenge in cross-modal retrieval, with the potential to contribute to a wide range of applications in multimodal understanding and information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AsCL: An Asymmetry-sensitive Contrastive Learning Method for Image-Text Retrieval with Cross-Modal Fusion
Ziyu Gong, Chengcheng Mai, Yihua Huang
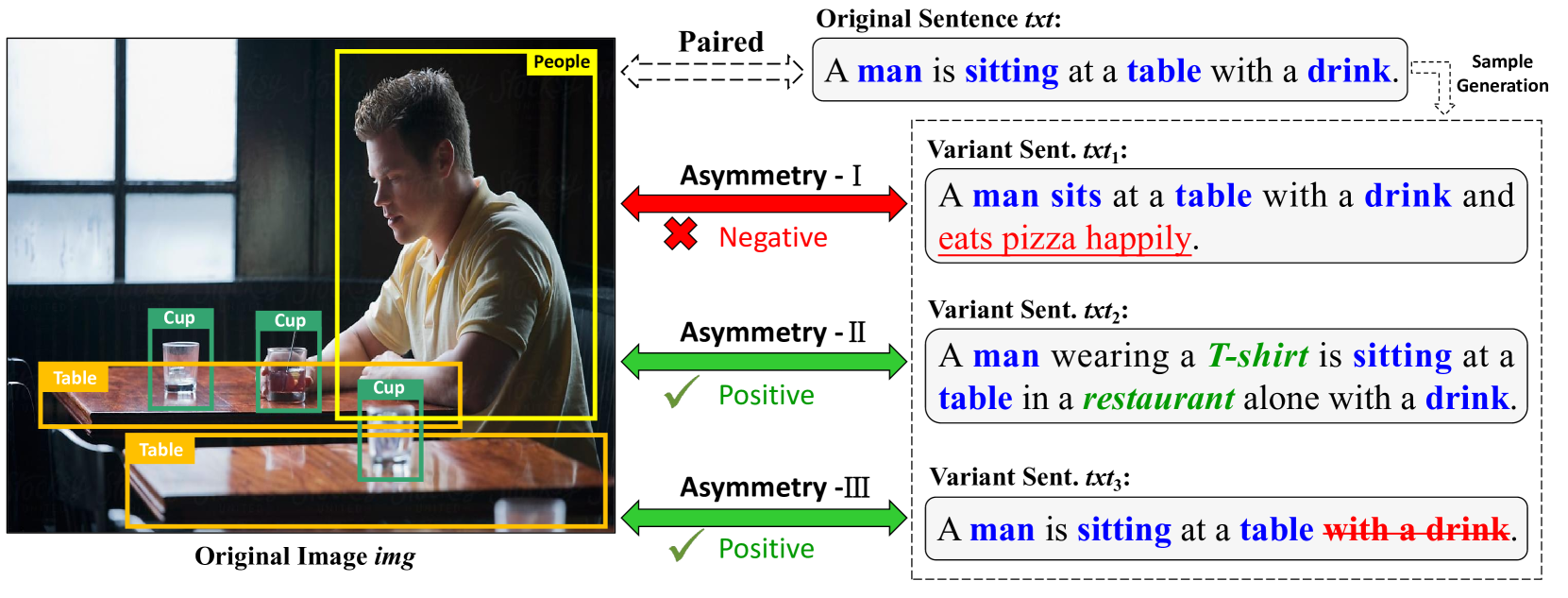
The image-text retrieval task aims to retrieve relevant information from a given image or text. The main challenge is to unify multimodal representation and distinguish fine-grained differences across modalities, thereby finding similar contents and filtering irrelevant contents. However, existing methods mainly focus on unified semantic representation and concept alignment for multi-modalities, while the fine-grained differences across modalities have rarely been studied before, making it difficult to solve the information asymmetry problem. In this paper, we propose a novel asymmetry-sensitive contrastive learning method. By generating corresponding positive and negative samples for different asymmetry types, our method can simultaneously ensure fine-grained semantic differentiation and unified semantic representation between multi-modalities. Additionally, a hierarchical cross-modal fusion method is proposed, which integrates global and local-level features through a multimodal attention mechanism to achieve concept alignment. Extensive experiments performed on MSCOCO and Flickr30K, demonstrate the effectiveness and superiority of our proposed method.
Read more5/20/2024
🤔
0
Asymmetric Contrastive Multimodal Learning for Advancing Chemical Understanding
Hao Xu, Yifei Wang, Yunrui Li, Pengyu Hong
The versatility of multimodal deep learning holds tremendous promise for advancing scientific research and practical applications. As this field continues to evolve, the collective power of cross-modal analysis promises to drive transformative innovations, leading us to new frontiers in chemical understanding and discovery. Hence, we introduce Asymmetric Contrastive Multimodal Learning (ACML) as a novel approach tailored for molecules, showcasing its potential to advance the field of chemistry. ACML harnesses the power of effective asymmetric contrastive learning to seamlessly transfer information from various chemical modalities to molecular graph representations. By combining pre-trained chemical unimodal encoders and a shallow-designed graph encoder, ACML facilitates the assimilation of coordinated chemical semantics from different modalities, leading to comprehensive representation learning with efficient training. We demonstrate the effectiveness of this framework through large-scale cross-modality retrieval and isomer discrimination tasks. Additionally, ACML enhances interpretability by revealing chemical semantics in graph presentations and bolsters the expressive power of graph neural networks, as evidenced by improved performance in molecular property prediction tasks from MoleculeNet. ACML exhibits its capability to revolutionize chemical research and applications, providing a deeper understanding of the chemical semantics of different modalities.
Read more8/2/2024

0
Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking
Tianyu Zhu, Myong Chol Jung, Jesse Clark
Contrastive learning has gained widespread adoption for retrieval tasks due to its minimal requirement for manual annotations. However, popular contrastive frameworks typically learn from binary relevance, making them ineffective at incorporating direct fine-grained rankings. In this paper, we curate a large-scale dataset featuring detailed relevance scores for each query-document pair to facilitate future research and evaluation. Subsequently, we propose Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking (GCL), which is designed to learn from fine-grained rankings beyond binary relevance scores. Our results show that GCL achieves a 94.5% increase in NDCG@10 for in-domain and 26.3 to 48.8% increases for cold-start evaluations, all relative to the CLIP baseline and involving ground truth rankings.
Read more4/15/2024

0
Coarse-to-fine Alignment Makes Better Speech-image Retrieval
Lifeng Zhou, Yuke Li
In this paper, we propose a novel framework for speech-image retrieval. We utilize speech-image contrastive (SIC) learning tasks to align speech and image representations at a coarse level and speech-image matching (SIM) learning tasks to further refine the fine-grained cross-modal alignment. SIC and SIM learning tasks are jointly trained in a unified manner. To optimize the learning process, we utilize an embedding queue that facilitates efficient sampling of high-quality and diverse negative representations during SIC learning. Additionally, it enhances the learning of SIM tasks by effectively mining hard negatives based on contrastive similarities calculated in SIC tasks. To further optimize learning under noisy supervision, we incorporate momentum distillation into the training process. Experimental results show that our framework outperforms the state-of-the-art method by more than 4% in R@1 on two benchmark datasets for the speech-image retrieval tasks. Moreover, as observed in zero-shot experiments, our framework demonstrates excellent generalization capabilities.
Read more9/12/2024