Coarse-to-fine Alignment Makes Better Speech-image Retrieval

0

Sign in to get full access
Overview
- The paper proposes a coarse-to-fine alignment approach to improve speech-image retrieval performance.
- It introduces a speech-image contrastive learning framework that learns multi-granular speech-image alignments.
- The method uses momentum distillation to transfer knowledge from a high-resolution model to a low-resolution one.
- Experiments show the proposed approach achieves state-of-the-art results on several speech-image retrieval benchmarks.
Plain English Explanation
The paper addresses the challenge of speech-image retrieval, which is the task of finding relevant images given a spoken query or vice versa. The researchers developed a new technique called "coarse-to-fine alignment" to tackle this problem more effectively.
The core idea is to learn the speech-image relationship at multiple levels of detail, from coarse (broad strokes) to fine (intricate details). This is accomplished through a contrastive learning framework that aligns speech and image representations at different granularities.
To further improve performance, the method also employs a "momentum distillation" approach. This allows a high-resolution model, which captures fine-grained alignments, to transfer its knowledge to a more efficient low-resolution model. The result is a system that can retrieve relevant images from speech queries (or vice versa) with state-of-the-art accuracy.
Technical Explanation
The paper introduces a speech-image matching learning framework that learns multi-granular speech-image alignments. The key components are:
-
Coarse-to-fine Alignment: The model learns to align speech and image representations at multiple levels of detail, from coarse to fine, by applying contrastive learning at different feature resolutions.
-
Momentum Distillation: A high-resolution model is trained to capture fine-grained speech-image alignments. This knowledge is then transferred to a low-resolution model via a momentum distillation process, improving its efficiency without sacrificing accuracy.
The experiments demonstrate that this coarse-to-fine alignment approach significantly outperforms previous speech-to-text and cross-modal retrieval methods on several benchmarks.
Critical Analysis
The paper presents a well-designed and effective approach for speech-image retrieval. The key strengths are the multi-granular alignment and the momentum distillation technique, which allow the model to capture both coarse and fine-grained relationships between speech and images.
However, the paper does not extensively discuss potential limitations or caveats of the proposed method. For example, it would be helpful to understand how the model's performance might be affected by factors such as the quality and diversity of the training data, the impact of different speech and image encoding architectures, or the scalability of the approach to larger-scale real-world scenarios.
Additionally, the paper could have provided more insights into the interpretability of the learned alignments and how they might be leveraged for other cross-modal tasks beyond retrieval.
Conclusion
This paper introduces a novel coarse-to-fine alignment approach that significantly advances the state of the art in speech-image retrieval. By learning multi-granular alignments and efficiently transferring knowledge from a high-resolution to a low-resolution model, the proposed method achieves impressive results on several benchmark datasets.
The insights and techniques presented in this work have the potential to enable more robust and versatile cross-modal understanding systems, with applications in areas like multimodal search, recommendation, and content understanding. Further research exploring the broader implications and real-world applications of this approach would be a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Coarse-to-fine Alignment Makes Better Speech-image Retrieval
Lifeng Zhou, Yuke Li
In this paper, we propose a novel framework for speech-image retrieval. We utilize speech-image contrastive (SIC) learning tasks to align speech and image representations at a coarse level and speech-image matching (SIM) learning tasks to further refine the fine-grained cross-modal alignment. SIC and SIM learning tasks are jointly trained in a unified manner. To optimize the learning process, we utilize an embedding queue that facilitates efficient sampling of high-quality and diverse negative representations during SIC learning. Additionally, it enhances the learning of SIM tasks by effectively mining hard negatives based on contrastive similarities calculated in SIC tasks. To further optimize learning under noisy supervision, we incorporate momentum distillation into the training process. Experimental results show that our framework outperforms the state-of-the-art method by more than 4% in R@1 on two benchmark datasets for the speech-image retrieval tasks. Moreover, as observed in zero-shot experiments, our framework demonstrates excellent generalization capabilities.
Read more9/12/2024

0
Cross-Modal Denoising: A Novel Training Paradigm for Enhancing Speech-Image Retrieval
Lifeng Zhou, Yuke Li, Rui Deng, Yuting Yang, Haoqi Zhu
The success of speech-image retrieval relies on establishing an effective alignment between speech and image. Existing methods often model cross-modal interaction through simple cosine similarity of the global feature of each modality, which fall short in capturing fine-grained details within modalities. To address this issue, we introduce an effective framework and a novel learning task named cross-modal denoising (CMD) to enhance cross-modal interaction to achieve finer-level cross-modal alignment. Specifically, CMD is a denoising task designed to reconstruct semantic features from noisy features within one modality by interacting features from another modality. Notably, CMD operates exclusively during model training and can be removed during inference without adding extra inference time. The experimental results demonstrate that our framework outperforms the state-of-the-art method by 2.0% in mean R@1 on the Flickr8k dataset and by 1.7% in mean R@1 on the SpokenCOCO dataset for the speech-image retrieval tasks, respectively. These experimental results validate the efficiency and effectiveness of our framework.
Read more9/12/2024

0
Advancing Multi-grained Alignment for Contrastive Language-Audio Pre-training
Yiming Li, Zhifang Guo, Xiangdong Wang, Hong Liu
Recent advances have been witnessed in audio-language joint learning, such as CLAP, that shows much success in multi-modal understanding tasks. These models usually aggregate uni-modal local representations, namely frame or word features, into global ones, on which the contrastive loss is employed to reach coarse-grained cross-modal alignment. However, frame-level correspondence with texts may be ignored, making it ill-posed on explainability and fine-grained challenges which may also undermine performances on coarse-grained tasks. In this work, we aim to improve both coarse- and fine-grained audio-language alignment in large-scale contrastive pre-training. To unify the granularity and latent distribution of two modalities, a shared codebook is adopted to represent multi-modal global features with common bases, and each codeword is regularized to encode modality-shared semantics, bridging the gap between frame and word features. Based on it, a locality-aware block is involved to purify local patterns, and a hard-negative guided loss is devised to boost alignment. Experiments on eleven zero-shot coarse- and fine-grained tasks suggest that our model not only surpasses the baseline CLAP significantly but also yields superior or competitive results compared to current SOTA works.
Read more8/16/2024
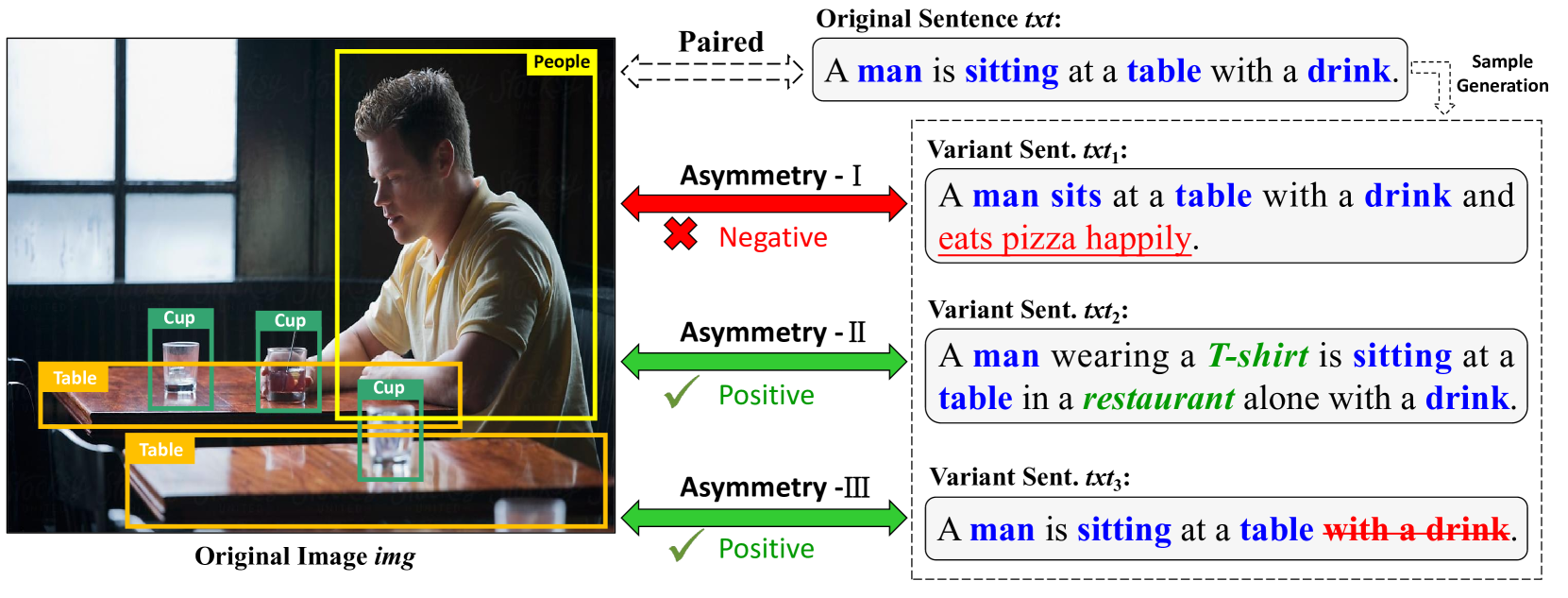
0
AsCL: An Asymmetry-sensitive Contrastive Learning Method for Image-Text Retrieval with Cross-Modal Fusion
Ziyu Gong, Chengcheng Mai, Yihua Huang
The image-text retrieval task aims to retrieve relevant information from a given image or text. The main challenge is to unify multimodal representation and distinguish fine-grained differences across modalities, thereby finding similar contents and filtering irrelevant contents. However, existing methods mainly focus on unified semantic representation and concept alignment for multi-modalities, while the fine-grained differences across modalities have rarely been studied before, making it difficult to solve the information asymmetry problem. In this paper, we propose a novel asymmetry-sensitive contrastive learning method. By generating corresponding positive and negative samples for different asymmetry types, our method can simultaneously ensure fine-grained semantic differentiation and unified semantic representation between multi-modalities. Additionally, a hierarchical cross-modal fusion method is proposed, which integrates global and local-level features through a multimodal attention mechanism to achieve concept alignment. Extensive experiments performed on MSCOCO and Flickr30K, demonstrate the effectiveness and superiority of our proposed method.
Read more5/20/2024