ASoBO: Attentive Beamformer Selection for Distant Speaker Diarization in Meetings

0
Sign in to get full access
Overview
- This paper proposes a method called "Attentive Beamformer Selection for Distant Speaker Diarization in Meetings" (ASoBO) to improve speaker diarization in group meeting settings.
- Speaker diarization is the task of identifying "who spoke when" in an audio recording, which is an important step for meeting transcription and analysis.
- The key idea of ASoBO is to use an attention mechanism to dynamically select the most relevant beamformer for diarization, rather than using a fixed beamformer.
- The authors evaluate their approach on several meeting datasets and show improvements over existing diarization methods.
Plain English Explanation
In group meetings, it can be challenging to transcribe the conversation accurately because there are multiple people speaking at different times. Speaker diarization is the process of identifying "who said what" in the audio recording of a meeting.
The researchers in this paper propose a new method called ASoBO to improve speaker diarization for distant microphone recordings. The key idea is to use an "attention" mechanism to dynamically select the most relevant audio signal from the different microphones in the room.
Traditionally, speaker diarization systems use a single fixed "beamformer" to combine the microphone signals. But in a meeting setting, the optimal beamformer may change over time as different people speak. The ASoBO method learns to automatically choose the best beamformer for each time segment, which helps improve the accuracy of the speaker diarization.
The researchers tested their ASoBO approach on several meeting datasets and showed that it outperformed existing diarization methods. This could be useful for improving meeting transcription systems and providing better analysis of group discussions.
Technical Explanation
The key innovation in the ASoBO method is the use of an attention mechanism to dynamically select the most relevant beamformer for speaker diarization. Traditionally, speaker diarization systems use a fixed beamformer to combine the signals from multiple microphones. However, in a meeting scenario, the optimal beamformer may change over time as different participants speak from different locations.
ASoBO addresses this by learning an attention model that can weight the contributions of each beamformer based on the current audio input. This attention model is trained end-to-end alongside the other components of the diarization system, including a speaker embedding extractor and a diarization clustering module.
The authors evaluate their approach on several meeting datasets, including AMI, DIHARD, and EURECOM. They show that ASoBO achieves significant improvements in diarization error rate compared to baseline methods that use fixed beamformers.
One key insight is that the attention weights learned by ASoBO tend to focus on the beamformer that is best aligned with the dominant speaker at each time point. This dynamic selection of the optimal beamformer helps the diarization system more accurately track the changing speaker activities in a meeting.
Critical Analysis
The ASoBO method represents a promising advance in speaker diarization for distant microphone recordings. By incorporating an attention mechanism to dynamically select the most relevant beamformer, the authors have demonstrated improved diarization performance over previous approaches.
However, the paper does not provide a deep analysis of the limitations or failure cases of the ASoBO method. For example, it would be interesting to understand how the attention mechanism behaves in scenarios with overlapping speech, background noise, or highly dynamic speaker movements. Additional analysis in these challenging conditions could help identify areas for further improvement.
Additionally, the authors only evaluate their approach on standard benchmark datasets. While these are well-established in the field, it would be valuable to see how ASoBO performs on real-world meeting recordings with greater variability in acoustic conditions and speaker behaviors.
Finally, the computational complexity of the attention-based beamformer selection is not discussed in detail. As diarization systems are often deployed in real-time applications, the runtime efficiency of the ASoBO method would be an important consideration for practical use.
Conclusion
This paper presents a novel approach called ASoBO that uses an attention mechanism to dynamically select the most relevant beamformer for speaker diarization in distant microphone recordings. The authors demonstrate improved diarization performance on several meeting datasets compared to existing methods.
The key innovation of ASoBO is its ability to adapt the beamformer selection to the changing speaker activities in a meeting, rather than relying on a fixed beamformer. This dynamic selection helps the diarization system more accurately track "who spoke when" in the audio.
While the paper shows promising results, further analysis of the method's robustness and computational efficiency would be valuable to assess its real-world applicability. Overall, the ASoBO approach represents an interesting advancement in the field of speaker diarization that could lead to more accurate meeting transcription and analysis systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ASoBO: Attentive Beamformer Selection for Distant Speaker Diarization in Meetings
Theo Mariotte, Anthony Larcher, Silvio Montresor, Jean-Hugh Thomas
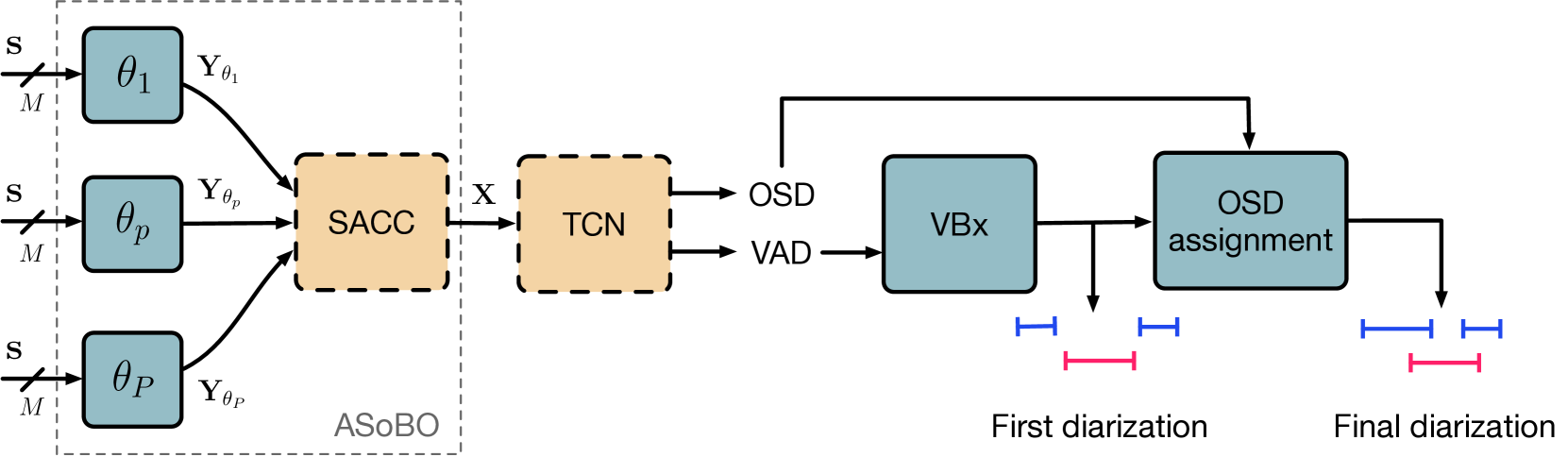
Speaker Diarization (SD) aims at grouping speech segments that belong to the same speaker. This task is required in many speech-processing applications, such as rich meeting transcription. In this context, distant microphone arrays usually capture the audio signal. Beamforming, i.e., spatial filtering, is a common practice to process multi-microphone audio data. However, it often requires an explicit localization of the active source to steer the filter. This paper proposes a self-attention-based algorithm to select the output of a bank of fixed spatial filters. This method serves as a feature extractor for joint Voice Activity (VAD) and Overlapped Speech Detection (OSD). The speaker diarization is then inferred from the detected segments. The approach shows convincing distant VAD, OSD, and SD performance, e.g. 14.5% DER on the AISHELL-4 dataset. The analysis of the self-attention weights demonstrates their explainability, as they correlate with the speaker's angular locations.
Read more6/6/2024
🧠
0
Array Geometry-Robust Attention-Based Neural Beamformer for Moving Speakers
Marvin Tammen, Tsubasa Ochiai, Marc Delcroix, Tomohiro Nakatani, Shoko Araki, Simon Doclo
Although mask-based beamforming is a powerful speech enhancement approach, it often requires manual parameter tuning to handle moving speakers. Recently, this approach was augmented with an attention-based spatial covariance matrix aggregator (ASA) module, enabling accurate tracking of moving speakers without manual tuning. However, the deep neural network model used in this module is limited to specific microphone arrays, necessitating a different model for varying channel permutations, numbers, or geometries. To improve the robustness of the ASA module against such variations, in this paper we investigate three approaches: training with random channel configurations, employing the transform-average-concatenate method to process multi-channel input features, and utilizing robust input features. Our experiments on the CHiME-3 and DEMAND datasets show that these approaches enable the ASA-augmented beamformer to track moving speakers across different microphone arrays unseen in training.
Read more6/18/2024

0
Efficient Area-based and Speaker-Agnostic Source Separation
Martin Strauss, Okan Kopuklu
This paper introduces an area-based source separation method designed for virtual meeting scenarios. The aim is to preserve speech signals from an unspecified number of sources within a defined spatial area in front of a linear microphone array, while suppressing all other sounds. Therefore, we employ an efficient neural network architecture adapted for multi-channel input to encompass the predefined target area. To evaluate the approach, training data and specific test scenarios including multiple target and interfering speakers, as well as background noise are simulated. All models are rated according to DNSMOS and scale-invariant signal-to-distortion ratio. Our experiments show that the proposed method separates speech from multiple speakers within the target area well, besides being of very low complexity, intended for real-time processing. In addition, a power reduction heatmap is used to demonstrate the networks' ability to identify sources located within the target area. We put our approach in context with a well-established baseline for speaker-speaker separation and discuss its strengths and challenges.
Read more8/20/2024

0
Neural Blind Source Separation and Diarization for Distant Speech Recognition
Yoshiaki Bando, Tomohiko Nakamura, Shinji Watanabe
This paper presents a neural method for distant speech recognition (DSR) that jointly separates and diarizes speech mixtures without supervision by isolated signals. A standard separation method for multi-talker DSR is a statistical multichannel method called guided source separation (GSS). While GSS does not require signal-level supervision, it relies on speaker diarization results to handle unknown numbers of active speakers. To overcome this limitation, we introduce and train a neural inference model in a weakly-supervised manner, employing the objective function of a statistical separation method. This training requires only multichannel mixtures and their temporal annotations of speaker activities. In contrast to GSS, the trained model can jointly separate and diarize speech mixtures without any auxiliary information. The experiments with the AMI corpus show that our method outperforms GSS with oracle diarization results regarding word error rates. The code is available online.
Read more6/13/2024