Efficient Area-based and Speaker-Agnostic Source Separation

0

Sign in to get full access
Overview
- Efficient area-based and speaker-agnostic source separation technique
- Leverages spatial information and speaker-independent models
- Aims to separate audio sources without requiring speaker-specific models
Plain English Explanation
The paper presents a method for separating different audio sources, such as voices or instruments, from a mixed audio recording. This is a common problem in audio processing and has applications in areas like audio-based virtual assistants, video conferencing, and music production.
The key idea of the proposed technique is to leverage spatial information about the sources, rather than relying on speaker-specific models. This makes the approach speaker-agnostic, meaning it can work without needing to train separate models for each individual speaker.
The method also uses an area-based approach, which focuses on separating audio sources based on their spatial locations, rather than trying to identify individual speakers. This can be more efficient and effective than techniques that require prior knowledge about the speakers.
Overall, this research aims to develop a more robust and versatile source separation system that can work in a variety of real-world scenarios without the need for extensive per-speaker training.
Technical Explanation
The paper formulates the source separation problem as estimating the spatial location and activity of each audio source in the mixed recording. The authors propose an area-based approach that does not require speaker-specific models.
The key components of the proposed method are:
-
Spatial feature extraction: The system extracts spatial features from the input audio, such as binaural cues that capture the spatial properties of the sources.
-
Source activity detection: A speaker-independent activity detection model is used to identify the time-frequency regions where each source is active.
-
Source separation: The spatial features and source activity information are combined to separate the individual sources from the mixed audio.
The authors evaluate their method on various benchmark datasets and demonstrate that it can achieve competitive separation performance without requiring speaker-specific models.
Critical Analysis
The paper presents a promising approach for efficient and speaker-agnostic source separation. However, the authors acknowledge several limitations and areas for future work:
- The method relies on accurate spatial feature extraction, which may be challenging in complex acoustic environments with reflections and reverberation.
- The speaker-independent activity detection model may not be as accurate as speaker-specific models, potentially affecting separation quality.
- The paper focuses on separating a fixed number of sources, whereas real-world scenarios may involve an unknown and varying number of sources.
Further research could explore techniques to improve spatial feature extraction, develop more robust speaker-independent activity detection models, and extend the method to handle variable numbers of sources.
Conclusion
This paper introduces an efficient and speaker-agnostic source separation technique that leverages spatial information and avoids the need for per-speaker models. The proposed approach shows promise for practical applications where the number and identities of audio sources are not known in advance. Continued research in this direction could lead to more versatile and widely applicable audio source separation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Area-based and Speaker-Agnostic Source Separation
Martin Strauss, Okan Kopuklu
This paper introduces an area-based source separation method designed for virtual meeting scenarios. The aim is to preserve speech signals from an unspecified number of sources within a defined spatial area in front of a linear microphone array, while suppressing all other sounds. Therefore, we employ an efficient neural network architecture adapted for multi-channel input to encompass the predefined target area. To evaluate the approach, training data and specific test scenarios including multiple target and interfering speakers, as well as background noise are simulated. All models are rated according to DNSMOS and scale-invariant signal-to-distortion ratio. Our experiments show that the proposed method separates speech from multiple speakers within the target area well, besides being of very low complexity, intended for real-time processing. In addition, a power reduction heatmap is used to demonstrate the networks' ability to identify sources located within the target area. We put our approach in context with a well-established baseline for speaker-speaker separation and discuss its strengths and challenges.
Read more8/20/2024

0
Inference-Adaptive Neural Steering for Real-Time Area-Based Sound Source Separation
Martin Strauss, Wolfgang Mack, Mar'ia Luis Valero, Okan Kopuklu
We propose a novel Neural Steering technique that adapts the target area of a spatial-aware multi-microphone sound source separation algorithm during inference without the necessity of retraining the deep neural network (DNN). To achieve this, we first train a DNN aiming to retain speech within a target region, defined by an angular span, while suppressing sound sources stemming from other directions. Afterward, a phase shift is applied to the microphone signals, allowing us to shift the center of the target area during inference at negligible additional cost in computational complexity. Further, we show that the proposed approach performs well in a wide variety of acoustic scenarios, including several speakers inside and outside the target area and additional noise. More precisely, the proposed approach performs on par with DNNs trained explicitly for the steered target area in terms of DNSMOS and SI-SDR.
Read more8/26/2024
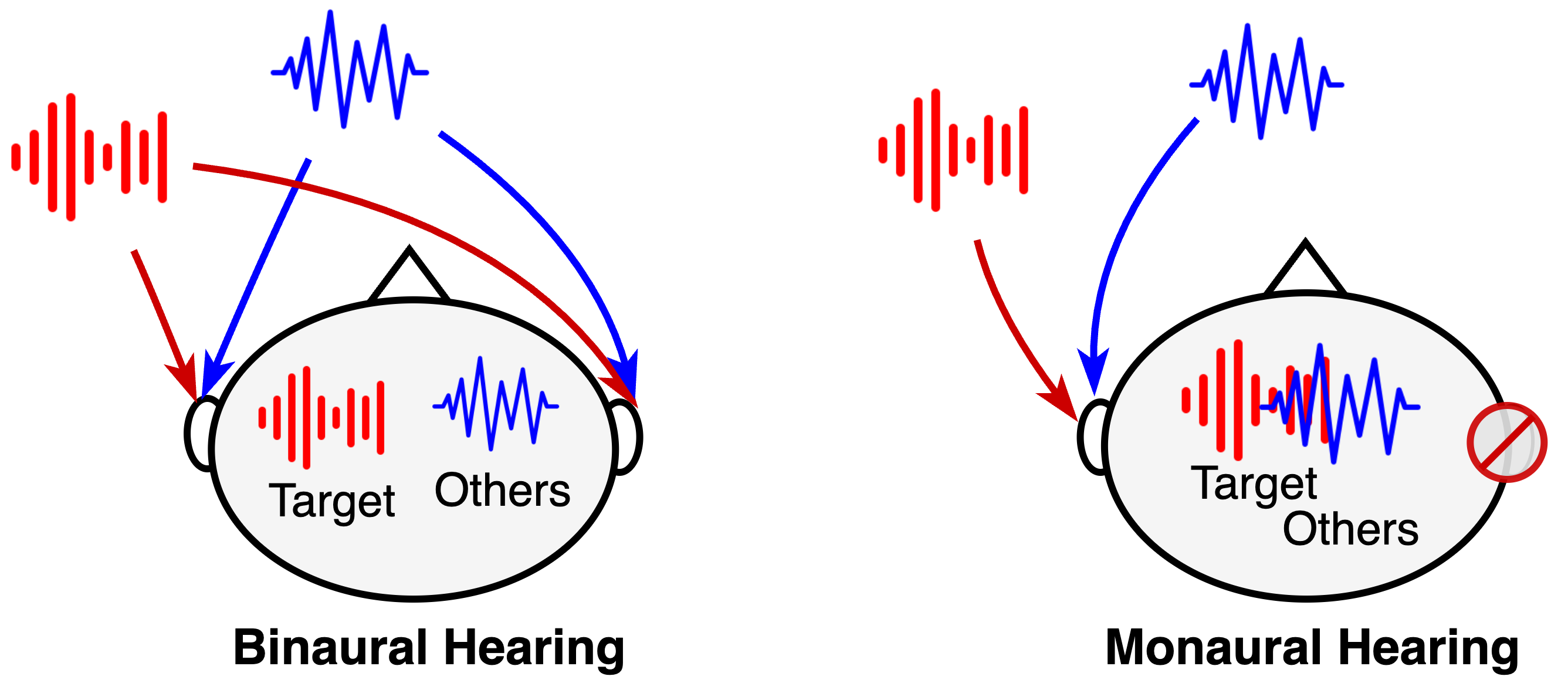
0
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024

0
Neural Blind Source Separation and Diarization for Distant Speech Recognition
Yoshiaki Bando, Tomohiko Nakamura, Shinji Watanabe
This paper presents a neural method for distant speech recognition (DSR) that jointly separates and diarizes speech mixtures without supervision by isolated signals. A standard separation method for multi-talker DSR is a statistical multichannel method called guided source separation (GSS). While GSS does not require signal-level supervision, it relies on speaker diarization results to handle unknown numbers of active speakers. To overcome this limitation, we introduce and train a neural inference model in a weakly-supervised manner, employing the objective function of a statistical separation method. This training requires only multichannel mixtures and their temporal annotations of speaker activities. In contrast to GSS, the trained model can jointly separate and diarize speech mixtures without any auxiliary information. The experiments with the AMI corpus show that our method outperforms GSS with oracle diarization results regarding word error rates. The code is available online.
Read more6/13/2024