Assessing LLMs for Zero-shot Abstractive Summarization Through the Lens of Relevance Paraphrasing

0
Sign in to get full access
Overview
- This paper evaluates the ability of large language models (LLMs) to perform zero-shot abstractive summarization by assessing their performance on a relevance paraphrasing task.
- The researchers propose a novel framework for measuring the robustness of LLMs in generating relevant and diverse paraphrases, which is a crucial component of effective summarization.
- The paper compares the performance of various LLMs, including GPT-3, BART, and T5, on the relevance paraphrasing task and provides insights into their strengths and limitations.
Plain English Explanation
The paper looks at how well large language models, which are powerful AI systems trained on vast amounts of text data, can summarize information in an abstract and concise way. This is a challenging task, as the models need to understand the key points of the original text and then rephrase them in a clear and relevant manner.
The researchers developed a new way to test the models' ability to do this, by having them generate paraphrases of sentences that are relevant to the original text. This "relevance paraphrasing" task allows the researchers to see how well the models can capture the important information and express it in their own words, rather than just copying the original text.
By comparing the performance of different language models, like GPT-3, BART, and T5, the researchers were able to identify the strengths and weaknesses of each model in this summarization task. This provides valuable insights for researchers and developers working on improving the summarization capabilities of these powerful language models.
Technical Explanation
The paper presents a novel framework for assessing the robustness of large language models (LLMs) in the context of zero-shot abstractive summarization. The core idea is to evaluate the models' ability to generate relevant and diverse paraphrases of input sentences, as this is a crucial component of effective summarization.
The researchers design a relevance paraphrasing task, where the models are asked to rephrase input sentences while preserving their key meaning and relevance to the original text. This allows the researchers to measure the models' understanding of semantic relationships and their capacity to express the same information in different ways.
The paper compares the performance of several prominent LLMs, including GPT-3, BART, and T5, on the relevance paraphrasing task. The results provide insights into the models' strengths and limitations in terms of generating relevant and diverse summaries.
Critical Analysis
The paper presents a well-designed framework for assessing the robustness of LLMs in the context of zero-shot abstractive summarization. The relevance paraphrasing task is a clever way to evaluate the models' understanding of semantic relationships and their ability to express the same information in different ways, which are crucial for effective summarization.
However, the paper acknowledges that the relevance paraphrasing task may not capture all aspects of summarization, such as the ability to identify and prioritize the most important information in a text. Additionally, the dataset used for the evaluation was relatively small, and the researchers note that further testing on larger and more diverse datasets would be valuable.
Another potential limitation is that the paper does not explore the impact of different fine-tuning or prompt engineering techniques on the models' performance. It would be interesting to see how the models' summarization capabilities could be improved through targeted training or fine-tuning on relevant tasks.
Overall, the paper provides a solid foundation for assessing the summarization capabilities of LLMs and highlights the importance of considering robustness and relevance in addition to traditional metrics like ROUGE. [Researchers working on improving topic relevance models or using LLMs for relevance judgments in product search may find the insights from this paper particularly relevant.]
Conclusion
This paper presents a novel framework for evaluating the ability of large language models to perform zero-shot abstractive summarization. By assessing the models' performance on a relevance paraphrasing task, the researchers were able to gain insights into the models' strengths and limitations in terms of generating relevant and diverse summaries.
The findings from this study have important implications for the development of more robust and effective summarization systems, which are crucial for making sense of the vast amounts of information available in the digital age. [As researchers continue to explore ways to leverage LLMs for medical applications or automated citation retrieval, the insights from this paper on the importance of relevance and robustness will likely prove valuable.]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assessing LLMs for Zero-shot Abstractive Summarization Through the Lens of Relevance Paraphrasing
Hadi Askari, Anshuman Chhabra, Muhao Chen, Prasant Mohapatra
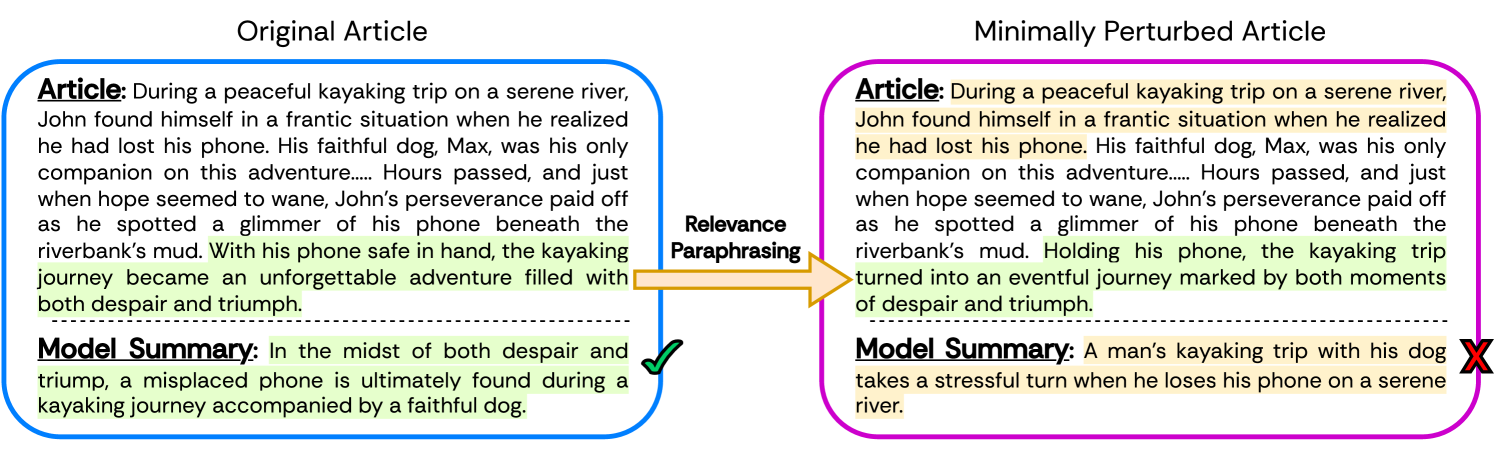
Large Language Models (LLMs) have achieved state-of-the-art performance at zero-shot generation of abstractive summaries for given articles. However, little is known about the robustness of such a process of zero-shot summarization. To bridge this gap, we propose relevance paraphrasing, a simple strategy that can be used to measure the robustness of LLMs as summarizers. The relevance paraphrasing approach identifies the most relevant sentences that contribute to generating an ideal summary, and then paraphrases these inputs to obtain a minimally perturbed dataset. Then, by evaluating model performance for summarization on both the original and perturbed datasets, we can assess the LLM's one aspect of robustness. We conduct extensive experiments with relevance paraphrasing on 4 diverse datasets, as well as 4 LLMs of different sizes (GPT-3.5-Turbo, Llama-2-13B, Mistral-7B, and Dolly-v2-7B). Our results indicate that LLMs are not consistent summarizers for the minimally perturbed articles, necessitating further improvements.
Read more6/7/2024
💬
0
On Learning to Summarize with Large Language Models as References
Yixin Liu, Kejian Shi, Katherine S He, Longtian Ye, Alexander R. Fabbri, Pengfei Liu, Dragomir Radev, Arman Cohan
Recent studies have found that summaries generated by large language models (LLMs) are favored by human annotators over the original reference summaries in commonly used summarization datasets. Therefore, we study an LLM-as-reference learning setting for smaller text summarization models to investigate whether their performance can be substantially improved. To this end, we use LLMs as both oracle summary generators for standard supervised fine-tuning and oracle summary evaluators for efficient contrastive learning that leverages the LLMs' supervision signals. We conduct comprehensive experiments with source news articles and find that (1) summarization models trained under the LLM-as-reference setting achieve significant performance improvement in both LLM and human evaluations; (2) contrastive learning outperforms standard supervised fine-tuning under both low and high resource settings. Our experimental results also enable a meta-analysis of LLMs' summary evaluation capacities under a challenging setting, showing that LLMs are not well-aligned with human evaluators. Particularly, our expert human evaluation reveals remaining nuanced performance gaps between LLMs and our fine-tuned models, which LLMs fail to capture. Thus, we call for further studies into both the potential and challenges of using LLMs in summarization model development.
Read more7/19/2024

0
What's Wrong? Refining Meeting Summaries with LLM Feedback
Frederic Kirstein, Terry Ruas, Bela Gipp
Meeting summarization has become a critical task since digital encounters have become a common practice. Large language models (LLMs) show great potential in summarization, offering enhanced coherence and context understanding compared to traditional methods. However, they still struggle to maintain relevance and avoid hallucination. We introduce a multi-LLM correction approach for meeting summarization using a two-phase process that mimics the human review process: mistake identification and summary refinement. We release QMSum Mistake, a dataset of 200 automatically generated meeting summaries annotated by humans on nine error types, including structural, omission, and irrelevance errors. Our experiments show that these errors can be identified with high accuracy by an LLM. We transform identified mistakes into actionable feedback to improve the quality of a given summary measured by relevance, informativeness, conciseness, and coherence. This post-hoc refinement effectively improves summary quality by leveraging multiple LLMs to validate output quality. Our multi-LLM approach for meeting summarization shows potential for similar complex text generation tasks requiring robustness, action planning, and discussion towards a goal.
Read more7/17/2024
0
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
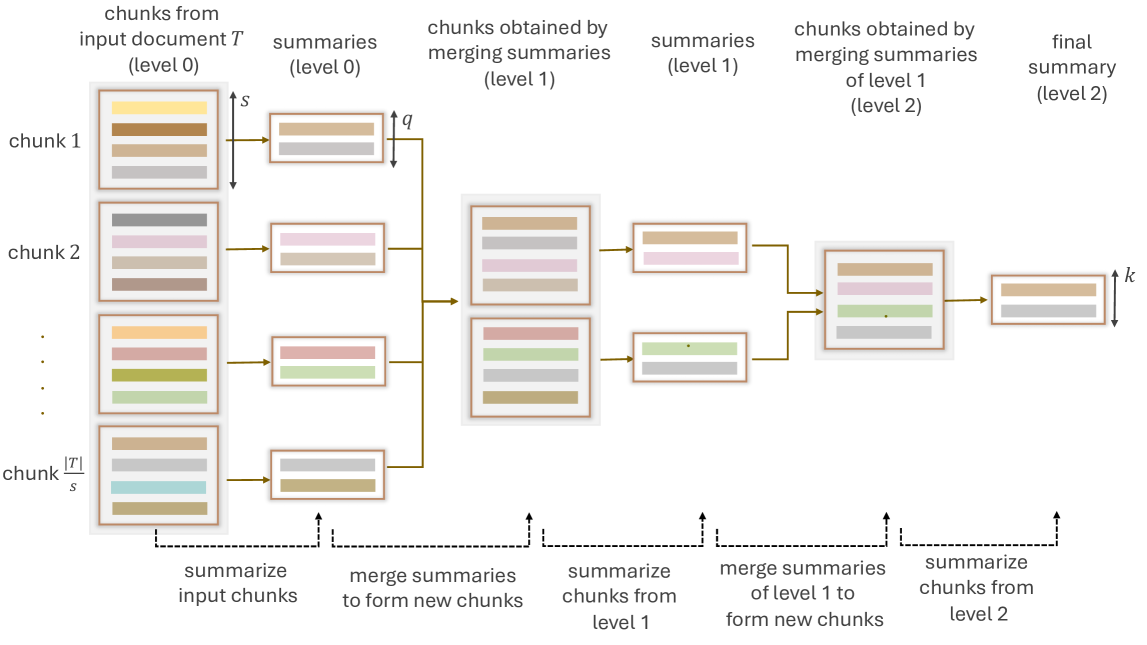
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024