What's Wrong? Refining Meeting Summaries with LLM Feedback

0

Sign in to get full access
Overview
- The paper focuses on refining meeting summaries using feedback from large language models (LLMs).
- The authors introduce the QMSum dataset, which contains annotated meeting summaries with mistakes identified by human experts.
- The paper explores using LLM feedback to automatically detect and correct these mistakes, with the goal of improving the quality of meeting summaries.
Plain English Explanation
In this paper, the researchers are looking at ways to improve the quality of meeting summaries using feedback from large language models (LLMs). They have created a dataset called QMSum, which contains meeting summaries that have been annotated by human experts to identify any mistakes or errors.
The key idea is to use the LLMs to automatically detect and correct these mistakes in the meeting summaries. The LLMs can provide valuable feedback on what is missing or inaccurate in the summaries, and this information can then be used to refine and improve the summaries.
This is an important problem to address because meeting summaries are often used to capture the key decisions and action items from important discussions. If these summaries contain errors or omissions, it can lead to confusion and misunderstandings. By leveraging the capabilities of LLMs, the researchers hope to develop more accurate and reliable meeting summaries that better reflect the actual discussions that took place.
Technical Explanation
The paper introduces the QMSum dataset, which contains 1,808 meeting summaries across 232 meetings. Each summary has been annotated by human experts to identify specific mistakes or problems, such as missing key points, inaccurate information, or irrelevant details.
The researchers then explore using large language models (LLMs) to automatically detect and correct these mistakes in the meeting summaries. They experiment with different LLM-based approaches, including using the LLM as a feedback system to identify problems in the summaries, and fine-tuning the LLM on the QMSum dataset to improve its ability to generate high-quality summaries.
The results show that the LLM-based approaches are able to effectively detect and correct many of the mistakes in the meeting summaries, leading to significant improvements in summary quality. The researchers also find that fine-tuning the LLM on the QMSum dataset is particularly effective, as it allows the model to better understand the specific characteristics and patterns of meeting summaries.
Critical Analysis
The paper provides a valuable contribution to the field of text summarization, particularly in the context of meeting summaries. However, there are a few potential limitations and areas for further research:
-
The QMSum dataset is relatively small, with only 232 meetings, which may limit the generalizability of the findings. It would be interesting to see if the LLM-based approaches can scale to larger datasets or different types of meetings.
-
The paper does not explore the use of interactive summarization approaches, where the user can provide feedback and iteratively refine the summary. This could be a promising direction for future work.
-
The evaluation metrics used in the paper, such as ROUGE, may not fully capture the nuances of summary quality, such as coherence, relevance, and usefulness. Exploring alternative evaluation methods could provide additional insights.
Overall, the paper presents a compelling approach to improving meeting summaries using LLM feedback, and the QMSum dataset provides a valuable resource for future research in this area.
Conclusion
This paper proposes a novel approach to refining meeting summaries using feedback from large language models (LLMs). By leveraging the QMSum dataset, which contains annotated meeting summaries with identified mistakes, the researchers demonstrate that LLM-based techniques can effectively detect and correct these errors, leading to significant improvements in summary quality.
The findings from this research have important implications for the field of text summarization, particularly in the context of meeting notes and other domain-specific summaries. By incorporating LLM-based feedback, organizations can strive to produce more accurate and reliable meeting summaries, which can lead to better decision-making, improved collaboration, and more effective communication.
Overall, this paper represents a significant step forward in the quest to develop more intelligent and adaptable text summarization systems, and the QMSum dataset provides a valuable resource for further exploration and innovation in this exciting field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What's Wrong? Refining Meeting Summaries with LLM Feedback
Frederic Kirstein, Terry Ruas, Bela Gipp
Meeting summarization has become a critical task since digital encounters have become a common practice. Large language models (LLMs) show great potential in summarization, offering enhanced coherence and context understanding compared to traditional methods. However, they still struggle to maintain relevance and avoid hallucination. We introduce a multi-LLM correction approach for meeting summarization using a two-phase process that mimics the human review process: mistake identification and summary refinement. We release QMSum Mistake, a dataset of 200 automatically generated meeting summaries annotated by humans on nine error types, including structural, omission, and irrelevance errors. Our experiments show that these errors can be identified with high accuracy by an LLM. We transform identified mistakes into actionable feedback to improve the quality of a given summary measured by relevance, informativeness, conciseness, and coherence. This post-hoc refinement effectively improves summary quality by leveraging multiple LLMs to validate output quality. Our multi-LLM approach for meeting summarization shows potential for similar complex text generation tasks requiring robustness, action planning, and discussion towards a goal.
Read more7/17/2024
📉
0
Summaries, Highlights, and Action items: Design, implementation and evaluation of an LLM-powered meeting recap system
Sumit Asthana, Sagih Hilleli, Pengcheng He, Aaron Halfaker
Meetings play a critical infrastructural role in the coordination of work. In recent years, due to shift to hybrid and remote work, more meetings are moving to online Computer Mediated Spaces. This has led to new problems (e.g. more time spent in less engaging meetings) and new opportunities (e.g. automated transcription/captioning and recap support). Recent advances in large language models (LLMs) for dialog summarization have the potential to improve the experience of meetings by reducing individuals' meeting load and increasing the clarity and alignment of meeting outputs. Despite this potential, they face technological limitation due to long transcripts and inability to capture diverse recap needs based on user's context. To address these gaps, we design, implement and evaluate in-context a meeting recap system. We first conceptualize two salient recap representations -- important highlights, and a structured, hierarchical minutes view. We develop a system to operationalize the representations with dialogue summarization as its building blocks. Finally, we evaluate the effectiveness of the system with seven users in the context of their work meetings. Our findings show promise in using LLM-based dialogue summarization for meeting recap and the need for both representations in different contexts. However, we find that LLM-based recap still lacks an understanding of whats personally relevant to participants, can miss important details, and mis-attributions can be detrimental to group dynamics. We identify collaboration opportunities such as a shared recap document that a high quality recap enables. We report on implications for designing AI systems to partner with users to learn and improve from natural interactions to overcome the limitations related to personal relevance and summarization quality.
Read more8/30/2024
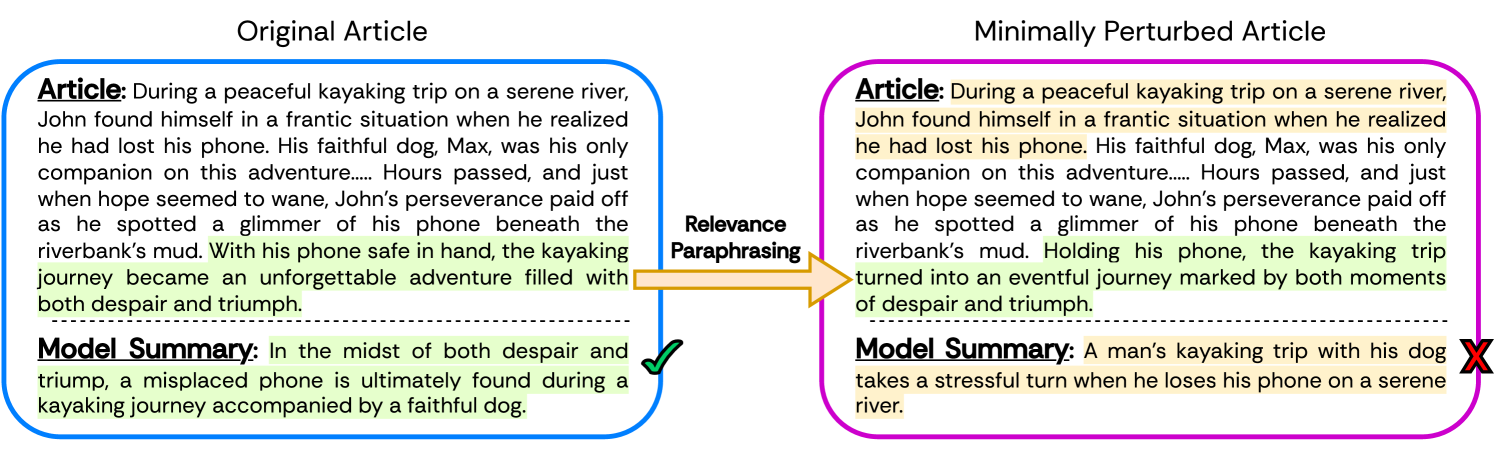
0
Assessing LLMs for Zero-shot Abstractive Summarization Through the Lens of Relevance Paraphrasing
Hadi Askari, Anshuman Chhabra, Muhao Chen, Prasant Mohapatra
Large Language Models (LLMs) have achieved state-of-the-art performance at zero-shot generation of abstractive summaries for given articles. However, little is known about the robustness of such a process of zero-shot summarization. To bridge this gap, we propose relevance paraphrasing, a simple strategy that can be used to measure the robustness of LLMs as summarizers. The relevance paraphrasing approach identifies the most relevant sentences that contribute to generating an ideal summary, and then paraphrases these inputs to obtain a minimally perturbed dataset. Then, by evaluating model performance for summarization on both the original and perturbed datasets, we can assess the LLM's one aspect of robustness. We conduct extensive experiments with relevance paraphrasing on 4 diverse datasets, as well as 4 LLMs of different sizes (GPT-3.5-Turbo, Llama-2-13B, Mistral-7B, and Dolly-v2-7B). Our results indicate that LLMs are not consistent summarizers for the minimally perturbed articles, necessitating further improvements.
Read more6/7/2024
💬
0
On Learning to Summarize with Large Language Models as References
Yixin Liu, Kejian Shi, Katherine S He, Longtian Ye, Alexander R. Fabbri, Pengfei Liu, Dragomir Radev, Arman Cohan
Recent studies have found that summaries generated by large language models (LLMs) are favored by human annotators over the original reference summaries in commonly used summarization datasets. Therefore, we study an LLM-as-reference learning setting for smaller text summarization models to investigate whether their performance can be substantially improved. To this end, we use LLMs as both oracle summary generators for standard supervised fine-tuning and oracle summary evaluators for efficient contrastive learning that leverages the LLMs' supervision signals. We conduct comprehensive experiments with source news articles and find that (1) summarization models trained under the LLM-as-reference setting achieve significant performance improvement in both LLM and human evaluations; (2) contrastive learning outperforms standard supervised fine-tuning under both low and high resource settings. Our experimental results also enable a meta-analysis of LLMs' summary evaluation capacities under a challenging setting, showing that LLMs are not well-aligned with human evaluators. Particularly, our expert human evaluation reveals remaining nuanced performance gaps between LLMs and our fine-tuned models, which LLMs fail to capture. Thus, we call for further studies into both the potential and challenges of using LLMs in summarization model development.
Read more7/19/2024