Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks

0
🚀
Sign in to get full access
Overview
- This paper evaluates the performance of Chinese open-source large language models (LLMs) on information extraction tasks.
- The researchers compare the capabilities of these models to those of state-of-the-art English LLMs like GPT-3.
- The study aims to assess the potential of Chinese LLMs for practical applications such as Unveiling the Potential of LLM-based ASR for Chinese Open and ADELIE: Aligning Large Language Models for Information Extraction.
Plain English Explanation
This research paper looks at how well Chinese open-source large language models (LLMs) perform on information extraction tasks. Information extraction is the process of automatically extracting specific pieces of information, like names, locations, or events, from unstructured text.
The researchers wanted to see how the capabilities of these Chinese LLMs compare to the performance of well-known English LLMs like GPT-3. LLMs are a type of AI model that can generate human-like text, and they've shown great potential for various language-related tasks.
By evaluating the Chinese LLMs on information extraction, the researchers hope to understand their practical applications, such as for automated speech recognition or aligning language models to extract information. This could help developers and researchers better leverage these powerful Chinese language models for real-world uses.
Technical Explanation
The paper describes an experimental setup where the researchers assessed the performance of several open-source Chinese LLMs on a range of information extraction tasks. They compared the results to the performance of state-of-the-art English LLMs like GPT-3.
The researchers used standardized datasets and evaluation metrics to ensure a fair comparison. They tested the models' abilities to extract entities (like people and locations), relations (connections between entities), and events (actions and occurrences) from Chinese text.
The results showed that the Chinese LLMs were able to achieve competitive performance on many of the information extraction tasks, sometimes even outperforming the English models. The researchers attribute this to the models' strong language understanding and generation capabilities, which were developed using large Chinese language datasets.
However, the paper also notes that the Chinese LLMs still lag behind the English models in certain areas, particularly for more complex extraction tasks that require deeper reasoning. The researchers suggest that further improvements to the Chinese LLMs, such as through instruction-based training, could help narrow this gap.
Critical Analysis
The paper provides a thorough and well-designed evaluation of Chinese LLMs for information extraction tasks. The researchers used appropriate datasets and metrics to ensure a fair comparison with state-of-the-art English models.
One limitation acknowledged in the paper is the relatively small size of the Chinese LLM models compared to the largest English models like GPT-3. Increasing the scale and training data of the Chinese models could potentially lead to further performance improvements.
Additionally, the paper focuses on extraction of basic entities, relations, and events, but does not explore more complex information extraction tasks that require deeper understanding of the text. Further research could investigate the models' capabilities in these more advanced areas.
Overall, the study offers valuable insights into the current state of Chinese LLMs and their potential for real-world applications in information extraction. The findings suggest that these models are a promising area for continued development and research.
Conclusion
This paper presents a comprehensive evaluation of Chinese open-source large language models (LLMs) on information extraction tasks. The results demonstrate that these models are capable of achieving competitive performance, sometimes even surpassing state-of-the-art English LLMs like GPT-3.
The findings highlight the potential of Chinese LLMs for practical applications such as automated speech recognition and aligning language models for information extraction. As these models continue to be refined and scaled, they could play an increasingly important role in enabling more advanced natural language processing capabilities for the Chinese language.
The paper's thorough evaluation and analysis provide a valuable reference for developers, researchers, and anyone interested in the capabilities of Chinese LLMs. The study's insights can help drive further progress in this rapidly evolving field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks
Yida Cai, Hao Sun, Hsiu-Yuan Huang, Yunfang Wu
Information Extraction (IE) plays a crucial role in Natural Language Processing (NLP) by extracting structured information from unstructured text, thereby facilitating seamless integration with various real-world applications that rely on structured data. Despite its significance, recent experiments focusing on English IE tasks have shed light on the challenges faced by Large Language Models (LLMs) in achieving optimal performance, particularly in sub-tasks like Named Entity Recognition (NER). In this paper, we delve into a comprehensive investigation of the performance of mainstream Chinese open-source LLMs in tackling IE tasks, specifically under zero-shot conditions where the models are not fine-tuned for specific tasks. Additionally, we present the outcomes of several few-shot experiments to further gauge the capability of these models. Moreover, our study includes a comparative analysis between these open-source LLMs and ChatGPT, a widely recognized language model, on IE performance. Through meticulous experimentation and analysis, we aim to provide insights into the strengths, limitations, and potential enhancements of existing Chinese open-source LLMs in the domain of Information Extraction within the context of NLP.
Read more6/5/2024
1
Large Language Models for Generative Information Extraction: A Survey
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, Enhong Chen
Information extraction (IE) aims to extract structural knowledge (such as entities, relations, and events) from plain natural language texts. Recently, generative Large Language Models (LLMs) have demonstrated remarkable capabilities in text understanding and generation, allowing for generalization across various domains and tasks. As a result, numerous works have been proposed to harness abilities of LLMs and offer viable solutions for IE tasks based on a generative paradigm. To conduct a comprehensive systematic review and exploration of LLM efforts for IE tasks, in this study, we survey the most recent advancements in this field. We first present an extensive overview by categorizing these works in terms of various IE subtasks and learning paradigms, then we empirically analyze the most advanced methods and discover the emerging trend of IE tasks with LLMs. Based on thorough review conducted, we identify several insights in technique and promising research directions that deserve further exploration in future studies. We maintain a public repository and consistently update related resources at: url{https://github.com/quqxui/Awesome-LLM4IE-Papers}.
Read more6/5/2024
0
An Empirical Study on Information Extraction using Large Language Models
Ridong Han, Chaohao Yang, Tao Peng, Prayag Tiwari, Xiang Wan, Lu Liu, Benyou Wang
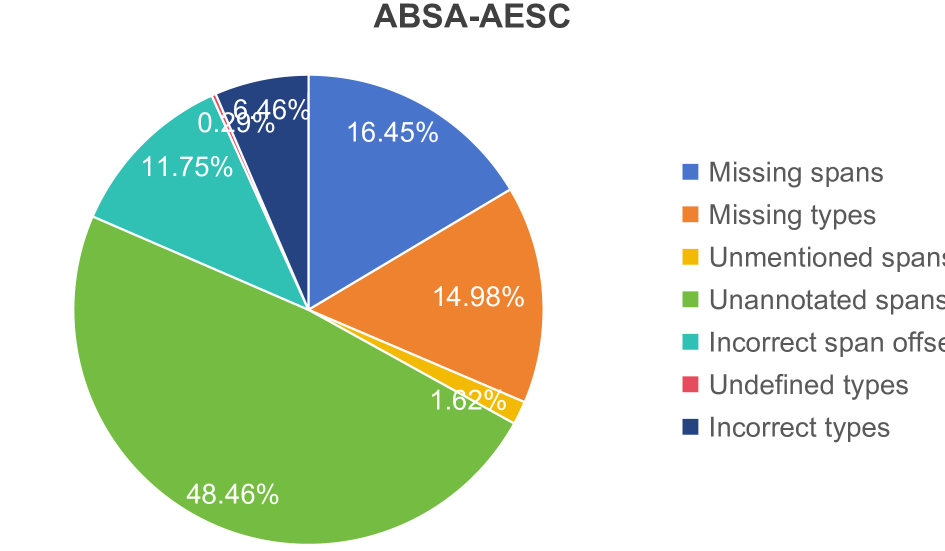
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI's GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs' information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs' human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods' effectiveness and some of their remaining issues in improving GPT-4's information extraction ability.
Read more9/10/2024
⛏️
0
A Survey on Open Information Extraction from Rule-based Model to Large Language Model
Pai Liu, Wenyang Gao, Wenjie Dong, Songfang Huang, Yue Zhang
Open information extraction is an important NLP task that targets extracting structured information from unstructured text without limitations on the relation type or the domain of the text. This survey paper covers open information extraction technologies from 2007 to 2022 with a focus on new models not covered by previous surveys. We propose a new categorization method from the source of information perspective to accommodate the development of recent OIE technologies. In addition, we summarize three major approaches based on task settings as well as current popular datasets and model evaluation metrics. Given the comprehensive review, several future directions are shown from datasets, source of information, output form, method, and evaluation metric aspects.
Read more5/1/2024