An Empirical Study on Information Extraction using Large Language Models

0
Sign in to get full access
Overview
- This paper presents an empirical study on using large language models (LLMs) for information extraction tasks.
- The researchers evaluate the performance of LLMs on common information extraction benchmarks and analyze the factors that influence their effectiveness.
- The findings provide insights into the capabilities and limitations of LLMs for information extraction, which can inform future research and applications in this domain.
Plain English Explanation
The paper explores how well large language models can be used for information extraction - the process of automatically identifying and extracting key facts, entities, and relationships from text. The researchers tested the performance of these powerful AI language models on standard benchmarks for information extraction tasks.
They found that LLMs can indeed be quite effective at information extraction, often outperforming traditional machine learning approaches. However, the models' performance can vary depending on factors like the specific task, the amount of training data available, and the complexity of the information being extracted.
The paper provides a detailed analysis of these factors, helping researchers and practitioners understand the strengths and limitations of using LLMs for information extraction. This knowledge can guide the development of more effective and reliable information extraction systems in the future.
Technical Explanation
The paper starts by assessing the performance of several prominent LLMs, including GPT-3, BERT, and RoBERTa, on a range of information extraction tasks. These tasks include named entity recognition, relation extraction, and event extraction, which are all important for leveraging large language models to extract valuable insights from text.
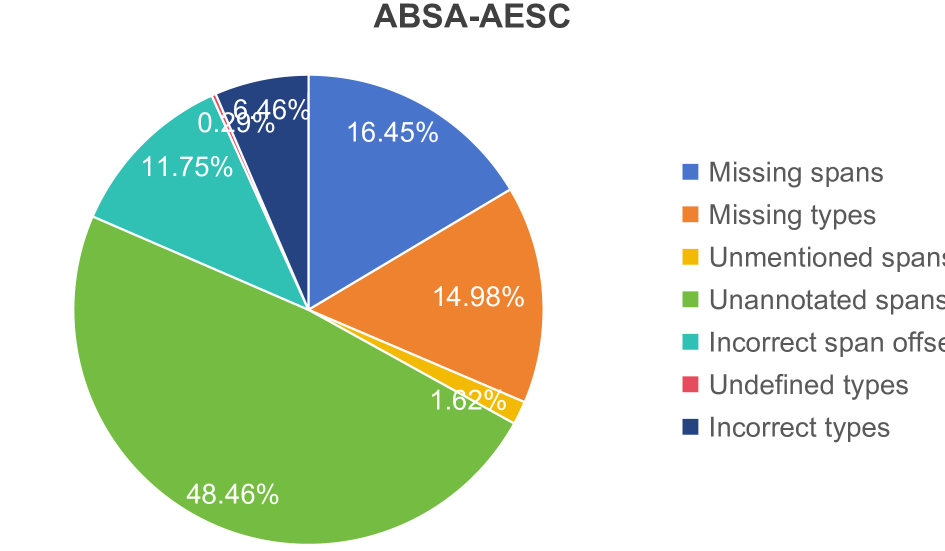
The researchers find that the LLMs generally outperform traditional machine learning approaches, especially on tasks that require deeper language understanding. However, they also identify certain limitations, such as the models' sensitivity to the amount and quality of training data, as well as their tendency to struggle with complex or ambiguous information extraction scenarios.
To further explore the use of large language models for information extraction, the paper delves into the impact of various factors, including model size, pre-training data, and task-specific fine-tuning. The results provide guidance on how to build robust and effective information extraction systems using LLMs.
Critical Analysis
The paper provides a comprehensive and well-designed empirical study on the use of LLMs for information extraction. The researchers have carefully selected a diverse set of tasks and datasets to evaluate the models' performance, and their analysis of the key factors influencing that performance is insightful.
However, the paper does acknowledge certain limitations of the study. For example, the researchers note that their experiments were conducted on English-language datasets, and the performance of LLMs may vary for other languages or domains. Additionally, the paper suggests that further research is needed to better understand the models' behavior in more complex or ambiguous information extraction scenarios.
It would also be helpful if the paper explored the potential biases or fairness issues that could arise from using LLMs for information extraction, as these models can sometimes reflect and amplify societal biases present in their training data.
Conclusion
This empirical study offers valuable insights into the capabilities and limitations of using large language models for information extraction tasks. The findings suggest that LLMs can be highly effective tools for extracting structured information from text, but their performance is influenced by a variety of factors that must be carefully considered.
The insights from this research can inform the development of more robust and reliable information extraction systems, which have important applications in fields like natural language processing, knowledge management, and business intelligence. As LLMs continue to evolve, this work provides a solid foundation for exploring their potential in the field of information extraction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Empirical Study on Information Extraction using Large Language Models
Ridong Han, Chaohao Yang, Tao Peng, Prayag Tiwari, Xiang Wan, Lu Liu, Benyou Wang
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI's GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs' information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs' human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods' effectiveness and some of their remaining issues in improving GPT-4's information extraction ability.
Read more9/10/2024
1
Large Language Models for Generative Information Extraction: A Survey
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, Enhong Chen
Information extraction (IE) aims to extract structural knowledge (such as entities, relations, and events) from plain natural language texts. Recently, generative Large Language Models (LLMs) have demonstrated remarkable capabilities in text understanding and generation, allowing for generalization across various domains and tasks. As a result, numerous works have been proposed to harness abilities of LLMs and offer viable solutions for IE tasks based on a generative paradigm. To conduct a comprehensive systematic review and exploration of LLM efforts for IE tasks, in this study, we survey the most recent advancements in this field. We first present an extensive overview by categorizing these works in terms of various IE subtasks and learning paradigms, then we empirically analyze the most advanced methods and discover the emerging trend of IE tasks with LLMs. Based on thorough review conducted, we identify several insights in technique and promising research directions that deserve further exploration in future studies. We maintain a public repository and consistently update related resources at: url{https://github.com/quqxui/Awesome-LLM4IE-Papers}.
Read more6/5/2024
🚀
0
Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks
Yida Cai, Hao Sun, Hsiu-Yuan Huang, Yunfang Wu
Information Extraction (IE) plays a crucial role in Natural Language Processing (NLP) by extracting structured information from unstructured text, thereby facilitating seamless integration with various real-world applications that rely on structured data. Despite its significance, recent experiments focusing on English IE tasks have shed light on the challenges faced by Large Language Models (LLMs) in achieving optimal performance, particularly in sub-tasks like Named Entity Recognition (NER). In this paper, we delve into a comprehensive investigation of the performance of mainstream Chinese open-source LLMs in tackling IE tasks, specifically under zero-shot conditions where the models are not fine-tuned for specific tasks. Additionally, we present the outcomes of several few-shot experiments to further gauge the capability of these models. Moreover, our study includes a comparative analysis between these open-source LLMs and ChatGPT, a widely recognized language model, on IE performance. Through meticulous experimentation and analysis, we aim to provide insights into the strengths, limitations, and potential enhancements of existing Chinese open-source LLMs in the domain of Information Extraction within the context of NLP.
Read more6/5/2024
💬
0
From Text to Insight: Leveraging Large Language Models for Performance Evaluation in Management
Ning Li, Huaikang Zhou, Mingze Xu
This study explores the potential of Large Language Models (LLMs), specifically GPT-4, to enhance objectivity in organizational task performance evaluations. Through comparative analyses across two studies, including various task performance outputs, we demonstrate that LLMs can serve as a reliable and even superior alternative to human raters in evaluating knowledge-based performance outputs, which are a key contribution of knowledge workers. Our results suggest that GPT ratings are comparable to human ratings but exhibit higher consistency and reliability. Additionally, combined multiple GPT ratings on the same performance output show strong correlations with aggregated human performance ratings, akin to the consensus principle observed in performance evaluation literature. However, we also find that LLMs are prone to contextual biases, such as the halo effect, mirroring human evaluative biases. Our research suggests that while LLMs are capable of extracting meaningful constructs from text-based data, their scope is currently limited to specific forms of performance evaluation. By highlighting both the potential and limitations of LLMs, our study contributes to the discourse on AI role in management studies and sets a foundation for future research to refine AI theoretical and practical applications in management.
Read more8/13/2024