Large Language Models for Generative Information Extraction: A Survey

1
Sign in to get full access
Overview
- This paper provides a comprehensive survey of the use of large language models (LLMs) for generative information extraction (IE) tasks.
- It covers the key concepts and recent advancements in this rapidly evolving field, with a focus on the unique challenges and opportunities presented by LLMs.
- The survey examines various IE tasks, such as open information extraction, entity extraction, relation extraction, and event extraction, and how LLMs can be leveraged to address them.
- It also discusses the trade-offs and limitations of using LLMs for generative IE, as well as potential future research directions in this area.
Plain English Explanation
This paper looks at how powerful language models, called large language models (LLMs), can be used to tackle a field called information extraction (IE). IE is all about automatically finding and extracting useful information from text, like the names of people, companies, or events, and the relationships between them.
The paper explains the key ideas behind using LLMs for this task. LLMs are AI models that have been trained on massive amounts of text data, giving them a deep understanding of language. The researchers explain how these powerful models can be leveraged to generate high-quality, human-like text that can be used to extract all sorts of useful information from documents, web pages, and other text sources.
The paper covers different types of IE tasks, like finding the names of people and organizations, understanding how they are related, and identifying important events. It discusses the unique advantages and challenges of using LLMs for these tasks, compared to more traditional IE approaches.
For example, LLMs can generate contextual, dynamic extractions that adapt to the specific text, rather than relying on rigid, pre-defined rules. However, they may also struggle with tasks that require precise, factual outputs, or that involve complex reasoning about the text.
Overall, the paper provides a comprehensive look at this exciting intersection of large language models and information extraction, highlighting both the promise and the pitfalls of this rapidly evolving field.
Technical Explanation
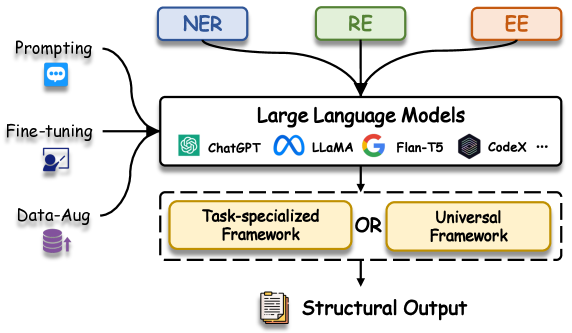
The paper begins by introducing the concept of generative information extraction, which leverages the powerful language understanding and generation capabilities of large language models (LLMs) to tackle a variety of IE tasks.
The authors outline the key differences between generative IE and more traditional, rule-based or machine learning-based IE approaches. Generative IE models can dynamically generate relevant extractions based on the specific context, rather than relying on pre-defined templates or patterns.
The paper then delves into the various IE tasks that can be addressed using LLMs, including entity extraction, relation extraction, event extraction, and open information extraction. For each task, the authors discuss the unique challenges and advantages of the generative approach, as well as recent advancements and state-of-the-art models.
For example, in entity extraction, LLMs can be fine-tuned to generate relevant entity mentions directly from the input text, rather than just classifying pre-identified spans. This allows for more flexible and contextual entity detection. However, the authors note that LLMs may struggle with rare or domain-specific entities, and that careful prompt engineering is often required.
The paper also covers cross-cutting issues in generative IE, such as the trade-off between precision and recall, the need for verifiable and consistent outputs, and the potential for bias and hallucinations in LLM-based systems.
Throughout the technical explanation, the authors draw connections to related work, such as surveys on large language models for code generation and assessments of Chinese LLMs, to provide a broader context for the research.
Critical Analysis
The paper provides a thorough and well-researched overview of the state of the art in using LLMs for generative information extraction. The authors do an excellent job of highlighting both the strengths and limitations of this approach, drawing attention to important considerations like output quality, consistency, and potential biases.
One area that could have been explored in more depth is the performance of LLM-based generative IE systems compared to more traditional, rule-based or machine learning-based approaches. While the authors mention the trade-offs between precision and recall, a more systematic evaluation of LLM performance across a range of IE tasks and datasets would have provided valuable insights.
The paper also lacks a deeper discussion of the computational and resource requirements of LLM-based IE systems, as well as their scalability and efficiency compared to other methods. This is an important consideration, especially for real-world applications of large language models.
Overall, the survey is a well-executed and informative piece that provides a solid foundation for understanding the current state of generative IE using LLMs. The authors have done an admirable job of synthesizing a large body of research and highlighting the key challenges and opportunities in this rapidly evolving field.
Conclusion
This comprehensive survey paper explores the use of large language models (LLMs) for generative information extraction (IE) tasks. The authors provide a detailed overview of the key concepts, recent advancements, and unique challenges in this rapidly evolving field.
The paper examines how the powerful language understanding and generation capabilities of LLMs can be leveraged to tackle a variety of IE tasks, such as entity extraction, relation extraction, and event extraction, in more flexible and contextual ways compared to traditional IE approaches.
The authors also discuss the trade-offs and limitations of using LLMs for generative IE, including the need for verifiable and consistent outputs, as well as the potential for bias and hallucinations. They highlight areas for further research, such as systematic performance evaluations and considerations around computational efficiency.
Overall, this survey provides a valuable resource for researchers and practitioners working at the intersection of large language models and information extraction, serving as a comprehensive guide to the current state of the art and future directions in this exciting field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Large Language Models for Generative Information Extraction: A Survey
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, Enhong Chen
Information extraction (IE) aims to extract structural knowledge (such as entities, relations, and events) from plain natural language texts. Recently, generative Large Language Models (LLMs) have demonstrated remarkable capabilities in text understanding and generation, allowing for generalization across various domains and tasks. As a result, numerous works have been proposed to harness abilities of LLMs and offer viable solutions for IE tasks based on a generative paradigm. To conduct a comprehensive systematic review and exploration of LLM efforts for IE tasks, in this study, we survey the most recent advancements in this field. We first present an extensive overview by categorizing these works in terms of various IE subtasks and learning paradigms, then we empirically analyze the most advanced methods and discover the emerging trend of IE tasks with LLMs. Based on thorough review conducted, we identify several insights in technique and promising research directions that deserve further exploration in future studies. We maintain a public repository and consistently update related resources at: url{https://github.com/quqxui/Awesome-LLM4IE-Papers}.
Read more6/5/2024
0
An Empirical Study on Information Extraction using Large Language Models
Ridong Han, Chaohao Yang, Tao Peng, Prayag Tiwari, Xiang Wan, Lu Liu, Benyou Wang
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI's GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs' information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs' human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods' effectiveness and some of their remaining issues in improving GPT-4's information extraction ability.
Read more9/10/2024
🚀
0
Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks
Yida Cai, Hao Sun, Hsiu-Yuan Huang, Yunfang Wu
Information Extraction (IE) plays a crucial role in Natural Language Processing (NLP) by extracting structured information from unstructured text, thereby facilitating seamless integration with various real-world applications that rely on structured data. Despite its significance, recent experiments focusing on English IE tasks have shed light on the challenges faced by Large Language Models (LLMs) in achieving optimal performance, particularly in sub-tasks like Named Entity Recognition (NER). In this paper, we delve into a comprehensive investigation of the performance of mainstream Chinese open-source LLMs in tackling IE tasks, specifically under zero-shot conditions where the models are not fine-tuned for specific tasks. Additionally, we present the outcomes of several few-shot experiments to further gauge the capability of these models. Moreover, our study includes a comparative analysis between these open-source LLMs and ChatGPT, a widely recognized language model, on IE performance. Through meticulous experimentation and analysis, we aim to provide insights into the strengths, limitations, and potential enhancements of existing Chinese open-source LLMs in the domain of Information Extraction within the context of NLP.
Read more6/5/2024
💬
0
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
Read more5/24/2024