Assessing SPARQL capabilities of Large Language Models

0
Sign in to get full access
Overview
- The paper assesses the SPARQL query capabilities of large language models (LLMs).
- SPARQL is a query language used to interact with knowledge graphs and databases.
- The research aims to understand how well LLMs can perform SPARQL-based tasks.
Plain English Explanation
The paper explores how well large language models, which are advanced AI systems trained on massive amounts of text data, can handle SPARQL queries. SPARQL is a specialized language used to interact with knowledge graphs and databases.
The researchers wanted to understand the capabilities of LLMs when it comes to tasks like understanding SPARQL queries, generating correct SPARQL queries based on natural language instructions, and retrieving accurate information from knowledge graphs. This is important because LLMs are becoming increasingly powerful and versatile, and being able to leverage them for SPARQL-based tasks could have many practical applications, such as building more intelligent question-answering systems or automating data analysis workflows.
Technical Explanation
The researchers conducted a series of experiments to assess the SPARQL capabilities of several prominent LLMs, including GPT-3, T5, and BERT. They evaluated the models' performance on tasks like:
- Translating natural language questions into SPARQL queries
- Executing SPARQL queries against knowledge graphs
- Generating SPARQL queries to answer natural language questions
The experiments used a variety of benchmark datasets and evaluation metrics to measure the models' accuracy, robustness, and generalization capabilities. The researchers also analyzed the types of errors the models made and explored strategies for improving their SPARQL performance.
Critical Analysis
The paper provides a comprehensive assessment of LLMs' SPARQL capabilities, but it also acknowledges several limitations and areas for further research. For example, the models were primarily evaluated on relatively simple SPARQL queries, and their performance may degrade for more complex or ambiguous queries. The researchers suggest that developing specialized training or fine-tuning approaches could help address this limitation.
Additionally, the experiments were conducted on a limited set of LLMs and datasets, so the findings may not generalize to other models or real-world applications. There is a need for more diverse benchmarking and further exploration of the underlying factors that influence LLMs' SPARQL performance.
Conclusion
This paper offers valuable insights into the current state of LLMs' SPARQL capabilities and highlights opportunities for further research and development. As LLMs continue to advance, the ability to effectively leverage them for SPARQL-based tasks could have significant implications for a wide range of applications, from knowledge management to data analysis and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assessing SPARQL capabilities of Large Language Models
Lars-Peter Meyer, Johannes Frey, Felix Brei, Natanael Arndt
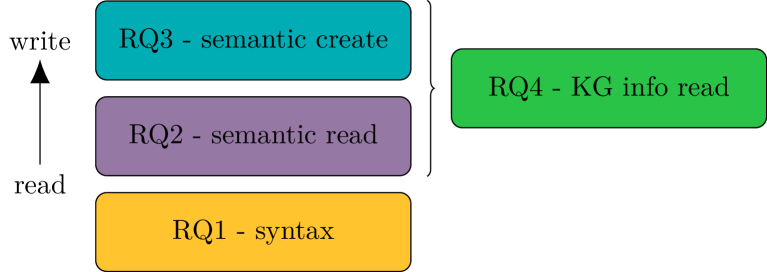
The integration of Large Language Models (LLMs) with Knowledge Graphs (KGs) offers significant synergistic potential for knowledge-driven applications. One possible integration is the interpretation and generation of formal languages, such as those used in the Semantic Web, with SPARQL being a core technology for accessing KGs. In this paper, we focus on measuring out-of-the box capabilities of LLMs to work with SPARQL and more specifically with SPARQL SELECT queries applying a quantitative approach. We implemented various benchmarking tasks in the LLM-KG-Bench framework for automated execution and evaluation with several LLMs. The tasks assess capabilities along the dimensions of syntax, semantic read, semantic create, and the role of knowledge graph prompt inclusion. With this new benchmarking tasks, we evaluated a selection of GPT, Gemini, and Claude models. Our findings indicate that working with SPARQL SELECT queries is still challenging for LLMs and heavily depends on the specific LLM as well as the complexity of the task. While fixing basic syntax errors seems to pose no problems for the best of the current LLMs evaluated, creating semantically correct SPARQL SELECT queries is difficult in several cases.
Read more9/11/2024

0
Leveraging Large Language Models for Semantic Query Processing in a Scholarly Knowledge Graph
Runsong Jia, Bowen Zhang, Sergio J. Rodr'iguez M'endez, Pouya G. Omran
The proposed research aims to develop an innovative semantic query processing system that enables users to obtain comprehensive information about research works produced by Computer Science (CS) researchers at the Australian National University (ANU). The system integrates Large Language Models (LLMs) with the ANU Scholarly Knowledge Graph (ASKG), a structured repository of all research-related artifacts produced at ANU in the CS field. Each artifact and its parts are represented as textual nodes stored in a Knowledge Graph (KG). To address the limitations of traditional scholarly KG construction and utilization methods, which often fail to capture fine-grained details, we propose a novel framework that integrates the Deep Document Model (DDM) for comprehensive document representation and the KG-enhanced Query Processing (KGQP) for optimized complex query handling. DDM enables a fine-grained representation of the hierarchical structure and semantic relationships within academic papers, while KGQP leverages the KG structure to improve query accuracy and efficiency with LLMs. By combining the ASKG with LLMs, our approach enhances knowledge utilization and natural language understanding capabilities. The proposed system employs an automatic LLM-SPARQL fusion to retrieve relevant facts and textual nodes from the ASKG. Initial experiments demonstrate that our framework is superior to baseline methods in terms of accuracy retrieval and query efficiency. We showcase the practical application of our framework in academic research scenarios, highlighting its potential to revolutionize scholarly knowledge management and discovery. This work empowers researchers to acquire and utilize knowledge from documents more effectively and provides a foundation for developing precise and reliable interactions with LLMs.
Read more5/27/2024
0
Chatbot-Based Ontology Interaction Using Large Language Models and Domain-Specific Standards
Jonathan Reif, Tom Jeleniewski, Milapji Singh Gill, Felix Gehlhoff, Alexander Fay
The following contribution introduces a concept that employs Large Language Models (LLMs) and a chatbot interface to enhance SPARQL query generation for ontologies, thereby facilitating intuitive access to formalized knowledge. Utilizing natural language inputs, the system converts user inquiries into accurate SPARQL queries that strictly query the factual content of the ontology, effectively preventing misinformation or fabrication by the LLM. To enhance the quality and precision of outcomes, additional textual information from established domain-specific standards is integrated into the ontology for precise descriptions of its concepts and relationships. An experimental study assesses the accuracy of generated SPARQL queries, revealing significant benefits of using LLMs for querying ontologies and highlighting areas for future research.
Read more8/6/2024
🛸
0
LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities
Yuqi Zhu, Xiaohan Wang, Jing Chen, Shuofei Qiao, Yixin Ou, Yunzhi Yao, Shumin Deng, Huajun Chen, Ningyu Zhang
This paper presents an exhaustive quantitative and qualitative evaluation of Large Language Models (LLMs) for Knowledge Graph (KG) construction and reasoning. We engage in experiments across eight diverse datasets, focusing on four representative tasks encompassing entity and relation extraction, event extraction, link prediction, and question-answering, thereby thoroughly exploring LLMs' performance in the domain of construction and inference. Empirically, our findings suggest that LLMs, represented by GPT-4, are more suited as inference assistants rather than few-shot information extractors. Specifically, while GPT-4 exhibits good performance in tasks related to KG construction, it excels further in reasoning tasks, surpassing fine-tuned models in certain cases. Moreover, our investigation extends to the potential generalization ability of LLMs for information extraction, leading to the proposition of a Virtual Knowledge Extraction task and the development of the corresponding VINE dataset. Based on these empirical findings, we further propose AutoKG, a multi-agent-based approach employing LLMs and external sources for KG construction and reasoning. We anticipate that this research can provide invaluable insights for future undertakings in the field of knowledge graphs. The code and datasets are in https://github.com/zjunlp/AutoKG.
Read more8/20/2024