LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities

0
🛸
Sign in to get full access
Overview
- This paper presents a comprehensive evaluation of Large Language Models (LLMs) for Knowledge Graph (KG) construction and reasoning.
- The researchers conducted experiments across eight diverse datasets, covering four representative tasks: entity and relation extraction, event extraction, link prediction, and question-answering.
- The findings suggest that LLMs, represented by GPT-4, are better suited as inference assistants than few-shot information extractors.
- The paper also proposes a Virtual Knowledge Extraction task and introduces the VINE dataset to explore the generalization ability of LLMs for information extraction.
- Finally, the researchers propose AutoKG, a multi-agent-based approach that employs LLMs and external sources for KG construction and reasoning.
Plain English Explanation
The paper looks at how well large language models, like GPT-4, can be used to create and work with knowledge graphs. Knowledge graphs are like structured databases that store information about the world, like the relationships between different entities (people, places, things, etc.).
The researchers ran experiments using eight different datasets to test the language models' performance on four key tasks:
- Extracting entities (like people or places) and the relationships between them from text.
- Extracting information about events, like what happened, when, and who was involved.
- Predicting missing links or connections in a knowledge graph.
- Answering questions by reasoning over the information in a knowledge graph.
The main finding is that while the language models are good at the construction tasks (extracting entities and relationships), they're even better at the reasoning tasks, like link prediction and question-answering. In some cases, the language models outperformed specialized models that had been trained specifically for those tasks.
The researchers also proposed a new task called "Virtual Knowledge Extraction" to test how well the language models can generalize their knowledge extraction skills to new domains. They created a dataset called VINE to support this new task.
Finally, the researchers introduced a new system called AutoKG that combines language models with other external sources to build and reason over knowledge graphs. The goal is to create a more powerful and flexible system for working with knowledge graphs.
Overall, the paper provides important insights into the strengths and limitations of using large language models for knowledge-based tasks, and proposes new directions for research and application in this area.
Technical Explanation
The paper presents a comprehensive evaluation of Large Language Models (LLMs) for Knowledge Graph (KG) construction and reasoning. The researchers conducted experiments across eight diverse datasets, focusing on four representative tasks: entity and relation extraction, event extraction, link prediction, and question-answering.
The results suggest that LLMs, represented by GPT-4, are more suited as inference assistants rather than few-shot information extractors. While GPT-4 exhibits good performance in tasks related to KG construction, it excels further in reasoning tasks, surpassing fine-tuned models in certain cases.
Furthermore, the researchers investigated the potential generalization ability of LLMs for information extraction, leading to the proposition of a Virtual Knowledge Extraction task and the development of the corresponding VINE dataset.
Based on these empirical findings, the researchers propose AutoKG, a multi-agent-based approach that employs LLMs and external sources for KG construction and reasoning.
Critical Analysis
The paper provides a thorough and well-designed evaluation of LLMs for KG construction and reasoning. The use of diverse datasets and representative tasks ensures a comprehensive understanding of the models' capabilities.
However, the paper could have delved deeper into the potential limitations or caveats of using LLMs for these tasks. For example, the researchers could have explored the model's performance on more specialized or domain-specific KG tasks, or investigated potential biases or inconsistencies in the models' knowledge or reasoning.
Additionally, the paper could have discussed the computational and resource requirements of the proposed AutoKG system, as well as any potential scalability or deployment challenges that may arise in real-world applications.
Overall, the paper presents valuable insights and a solid foundation for future research in the field of knowledge graph construction and reasoning using large language models.
Conclusion
This paper presents a comprehensive evaluation of Large Language Models (LLMs) for Knowledge Graph (KG) construction and reasoning. The researchers found that LLMs, represented by GPT-4, are more suited as inference assistants than few-shot information extractors, performing better on reasoning tasks like link prediction and question-answering.
The paper also introduces the concept of Virtual Knowledge Extraction and the VINE dataset to explore the generalization ability of LLMs for information extraction. Additionally, the researchers propose AutoKG, a multi-agent-based approach that combines LLMs and external sources for KG construction and reasoning.
The findings and insights presented in this paper have the potential to significantly impact the field of knowledge graph research and applications, paving the way for more advanced and versatile systems that leverage the strengths of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities
Yuqi Zhu, Xiaohan Wang, Jing Chen, Shuofei Qiao, Yixin Ou, Yunzhi Yao, Shumin Deng, Huajun Chen, Ningyu Zhang
This paper presents an exhaustive quantitative and qualitative evaluation of Large Language Models (LLMs) for Knowledge Graph (KG) construction and reasoning. We engage in experiments across eight diverse datasets, focusing on four representative tasks encompassing entity and relation extraction, event extraction, link prediction, and question-answering, thereby thoroughly exploring LLMs' performance in the domain of construction and inference. Empirically, our findings suggest that LLMs, represented by GPT-4, are more suited as inference assistants rather than few-shot information extractors. Specifically, while GPT-4 exhibits good performance in tasks related to KG construction, it excels further in reasoning tasks, surpassing fine-tuned models in certain cases. Moreover, our investigation extends to the potential generalization ability of LLMs for information extraction, leading to the proposition of a Virtual Knowledge Extraction task and the development of the corresponding VINE dataset. Based on these empirical findings, we further propose AutoKG, a multi-agent-based approach employing LLMs and external sources for KG construction and reasoning. We anticipate that this research can provide invaluable insights for future undertakings in the field of knowledge graphs. The code and datasets are in https://github.com/zjunlp/AutoKG.
Read more8/20/2024
🌀
0
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Yihao Li, Ru Zhang, Jianyi Liu
While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
Read more6/13/2024
💬
0
Combining Knowledge Graphs and Large Language Models
Amanda Kau, Xuzeng He, Aishwarya Nambissan, Aland Astudillo, Hui Yin, Amir Aryani
In recent years, Natural Language Processing (NLP) has played a significant role in various Artificial Intelligence (AI) applications such as chatbots, text generation, and language translation. The emergence of large language models (LLMs) has greatly improved the performance of these applications, showing astonishing results in language understanding and generation. However, they still show some disadvantages, such as hallucinations and lack of domain-specific knowledge, that affect their performance in real-world tasks. These issues can be effectively mitigated by incorporating knowledge graphs (KGs), which organise information in structured formats that capture relationships between entities in a versatile and interpretable fashion. Likewise, the construction and validation of KGs present challenges that LLMs can help resolve. The complementary relationship between LLMs and KGs has led to a trend that combines these technologies to achieve trustworthy results. This work collected 28 papers outlining methods for KG-powered LLMs, LLM-based KGs, and LLM-KG hybrid approaches. We systematically analysed and compared these approaches to provide a comprehensive overview highlighting key trends, innovative techniques, and common challenges. This synthesis will benefit researchers new to the field and those seeking to deepen their understanding of how KGs and LLMs can be effectively combined to enhance AI applications capabilities.
Read more7/10/2024
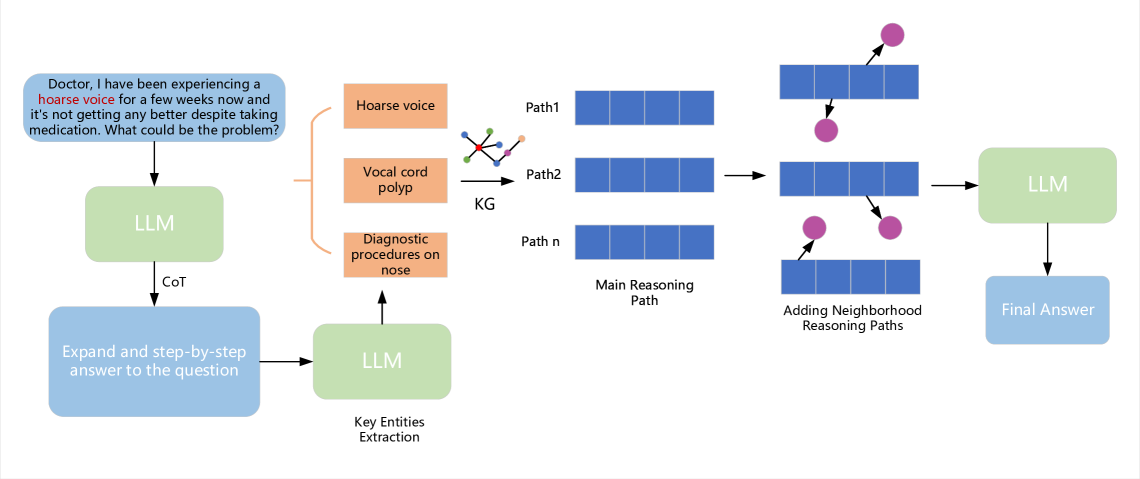
0
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
Read more4/17/2024