Assistive Image Annotation Systems with Deep Learning and Natural Language Capabilities: A Review

0
Sign in to get full access
Overview
- This paper reviews the state of assistive image annotation systems that leverage deep learning and natural language capabilities.
- These systems aim to help users efficiently annotate images by providing automated suggestions, textual hints, and other AI-powered assistance.
- Key capabilities covered include image captioning, visual question answering, and semantic image augmentation.
Plain English Explanation
Annotating images, or adding descriptions and labels to them, is an important task for a variety of applications like image search, data labeling, and accessibility. However, manually annotating large image datasets can be time-consuming and tedious.
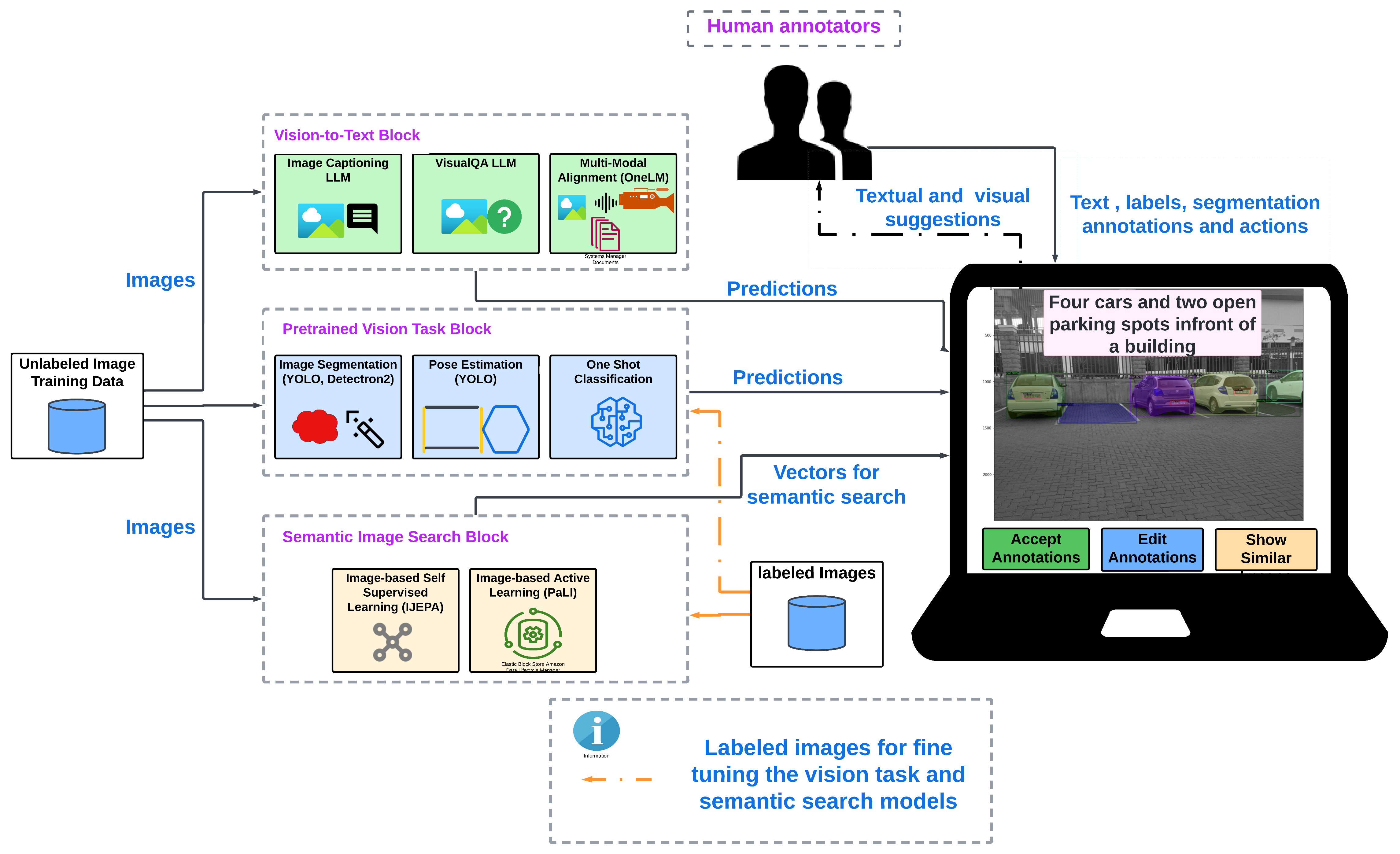
This paper looks at how AI systems can assist users with image annotation. These "assistive image annotation systems" leverage advanced techniques in computer vision and natural language processing to automate parts of the annotation workflow. For example, the system could generate captions to describe what's in an image, or answer questions about the content. The system could also suggest relevant keywords or provide other helpful hints to make the annotation process faster and more efficient.
The goal is to harness the power of AI to augment and complement human annotation efforts, rather than fully automate the task. By blending human insight with machine intelligence, these systems aim to improve the accuracy, speed, and accessibility of image annotation.
Technical Explanation
The paper provides a comprehensive review of the key capabilities and architectures underpinning assistive image annotation systems. A common approach is to leverage multi-modal deep learning that can process both visual and textual data.
For example, an image captioning model may use a convolutional neural network to extract visual features from an image, and then a recurrent neural network to generate corresponding captions. Similarly, visual question answering systems combine computer vision and natural language processing to answer questions about image content.
Some systems also explore semantic image augmentation, where textual information is used to enrich the representation of an image beyond just the visible pixels. This can facilitate more comprehensive and descriptive annotations.
The paper also discusses architectural innovations like retrieval-augmented models that leverage external knowledge sources, as well as interactive interfaces that allow users to provide feedback to refine the system's outputs.
Critical Analysis
The paper provides a thorough overview of the state-of-the-art in assistive image annotation systems, highlighting both the impressive capabilities and the remaining challenges in this field.
One key limitation mentioned is the potential for these systems to perpetuate biases present in their training data, leading to inaccurate or skewed annotations. More research is needed on bias mitigation and fairness in multi-modal AI models.
Additionally, the paper notes that the seamless integration of these AI-powered assistants into real-world annotation workflows remains an open challenge. Developing intuitive user interfaces and ensuring robust performance at scale are important areas for future work.
Overall, the review paints a promising picture of how deep learning and natural language processing can revolutionize image annotation, but also underscores the need for continued innovation and careful consideration of the societal implications of these technologies.
Conclusion
Assistive image annotation systems that leverage deep learning and natural language capabilities hold significant potential to streamline and enhance the process of adding labels and descriptions to visual data. By automating repetitive tasks, providing contextual suggestions, and enabling multimodal interaction, these systems can boost the efficiency, accuracy, and accessibility of image annotation.
As the field continues to advance, key priorities will be addressing algorithmic biases, improving user experiences, and exploring novel architectures that seamlessly integrate human and machine intelligence. With further research and development, these assistive technologies could become indispensable tools for a wide range of applications, from data curation to accessibility.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assistive Image Annotation Systems with Deep Learning and Natural Language Capabilities: A Review
Moseli Mots'oehli
While supervised learning has achieved significant success in computer vision tasks, acquiring high-quality annotated data remains a bottleneck. This paper explores both scholarly and non-scholarly works in AI-assistive deep learning image annotation systems that provide textual suggestions, captions, or descriptions of the input image to the annotator. This potentially results in higher annotation efficiency and quality. Our exploration covers annotation for a range of computer vision tasks including image classification, object detection, regression, instance, semantic segmentation, and pose estimation. We review various datasets and how they contribute to the training and evaluation of AI-assistive annotation systems. We also examine methods leveraging neuro-symbolic learning, deep active learning, and self-supervised learning algorithms that enable semantic image understanding and generate free-text output. These include image captioning, visual question answering, and multi-modal reasoning. Despite the promising potential, there is limited publicly available work on AI-assistive image annotation with textual output capabilities. We conclude by suggesting future research directions to advance this field, emphasizing the need for more publicly accessible datasets and collaborative efforts between academia and industry.
Read more7/2/2024
0
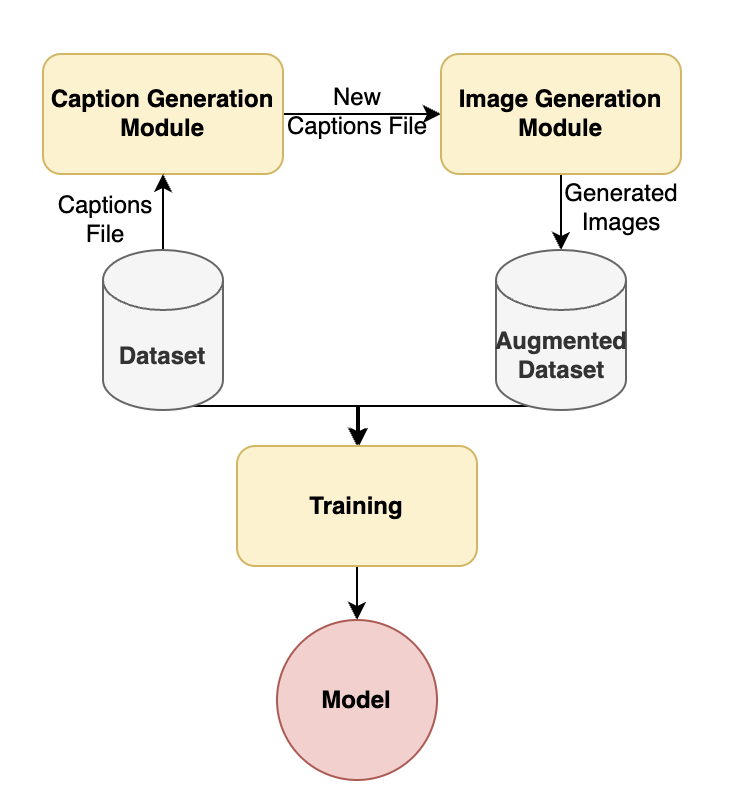
Semantic Augmentation in Images using Language
Sahiti Yerramilli, Jayant Sravan Tamarapalli, Tanmay Girish Kulkarni, Jonathan Francis, Eric Nyberg
Deep Learning models are incredibly data-hungry and require very large labeled datasets for supervised learning. As a consequence, these models often suffer from overfitting, limiting their ability to generalize to real-world examples. Recent advancements in diffusion models have enabled the generation of photorealistic images based on textual inputs. Leveraging the substantial datasets used to train these diffusion models, we propose a technique to utilize generated images to augment existing datasets. This paper explores various strategies for effective data augmentation to improve the out-of-domain generalization capabilities of deep learning models.
Read more4/4/2024
📊
0
No Need to Sacrifice Data Quality for Quantity: Crowd-Informed Machine Annotation for Cost-Effective Understanding of Visual Data
Christopher Klugmann, Rafid Mahmood, Guruprasad Hegde, Amit Kale, Daniel Kondermann
Labeling visual data is expensive and time-consuming. Crowdsourcing systems promise to enable highly parallelizable annotations through the participation of monetarily or otherwise motivated workers, but even this approach has its limits. The solution: replace manual work with machine work. But how reliable are machine annotators? Sacrificing data quality for high throughput cannot be acceptable, especially in safety-critical applications such as autonomous driving. In this paper, we present a framework that enables quality checking of visual data at large scales without sacrificing the reliability of the results. We ask annotators simple questions with discrete answers, which can be highly automated using a convolutional neural network trained to predict crowd responses. Unlike the methods of previous work, which aim to directly predict soft labels to address human uncertainty, we use per-task posterior distributions over soft labels as our training objective, leveraging a Dirichlet prior for analytical accessibility. We demonstrate our approach on two challenging real-world automotive datasets, showing that our model can fully automate a significant portion of tasks, saving costs in the high double-digit percentage range. Our model reliably predicts human uncertainty, allowing for more accurate inspection and filtering of difficult examples. Additionally, we show that the posterior distributions over soft labels predicted by our model can be used as priors in further inference processes, reducing the need for numerous human labelers to approximate true soft labels accurately. This results in further cost reductions and more efficient use of human resources in the annotation process.
Read more9/4/2024

0
Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions
Renjie Pi, Jianshu Zhang, Jipeng Zhang, Rui Pan, Zhekai Chen, Tong Zhang
Image description datasets play a crucial role in the advancement of various applications such as image understanding, text-to-image generation, and text-image retrieval. Currently, image description datasets primarily originate from two sources. One source is the scraping of image-text pairs from the web. Despite their abundance, these descriptions are often of low quality and noisy. Another is through human labeling. Datasets such as COCO are generally very short and lack details. Although detailed image descriptions can be annotated by humans, the high annotation cost limits the feasibility. These limitations underscore the need for more efficient and scalable methods to generate accurate and detailed image descriptions. In this paper, we propose an innovative framework termed Image Textualization (IT), which automatically produces high-quality image descriptions by leveraging existing multi-modal large language models (MLLMs) and multiple vision expert models in a collaborative manner, which maximally convert the visual information into text. To address the current lack of benchmarks for detailed descriptions, we propose several benchmarks for comprehensive evaluation, which verifies the quality of image descriptions created by our framework. Furthermore, we show that LLaVA-7B, benefiting from training on IT-curated descriptions, acquire improved capability to generate richer image descriptions, substantially increasing the length and detail of their output with less hallucination.
Read more6/12/2024