ASTRA: Aligning Speech and Text Representations for Asr without Sampling

0
Sign in to get full access
Overview
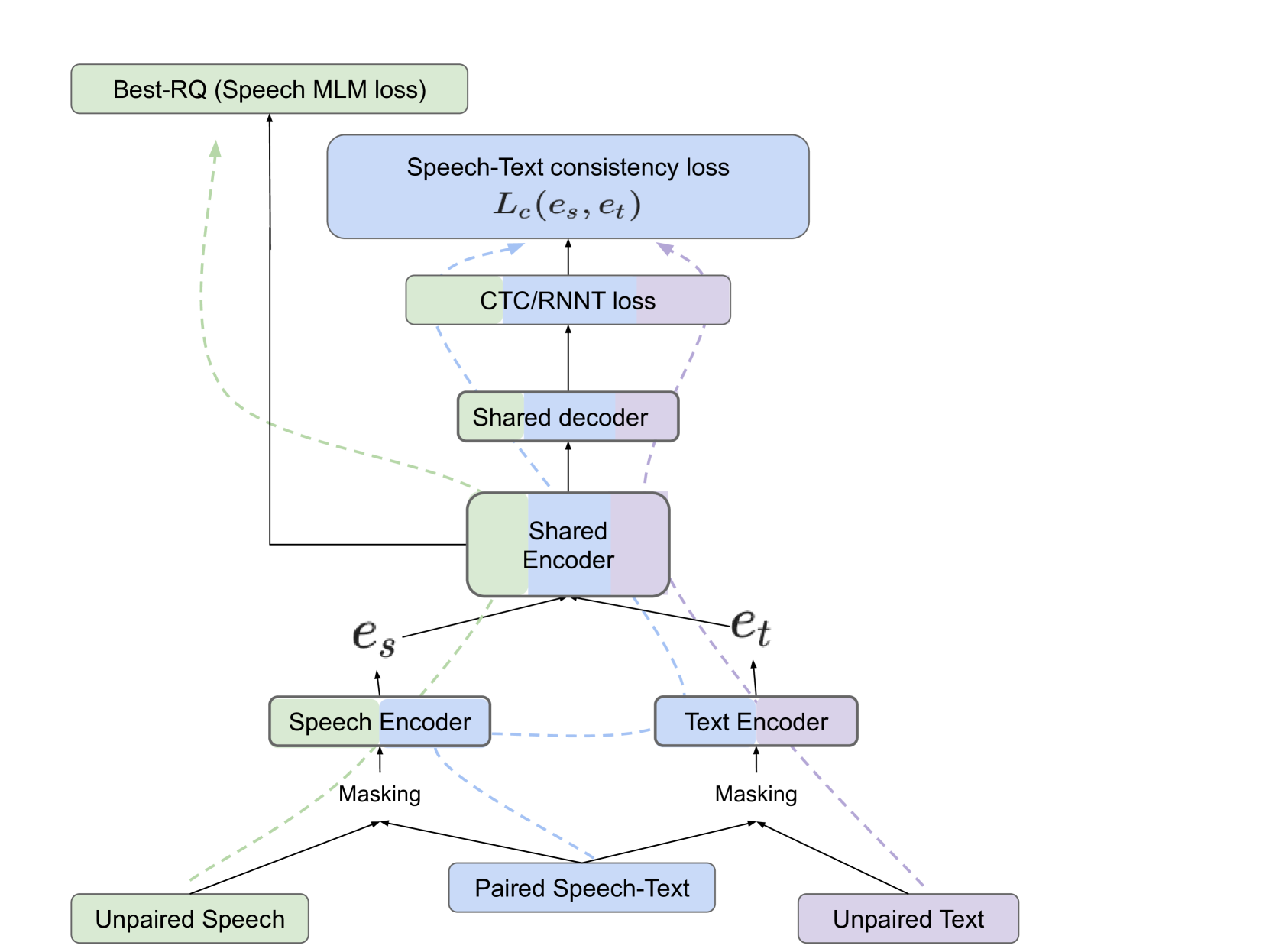
- This paper presents a new method called ASTRA (Aligning Speech and Text Representations for ASR) for training automatic speech recognition (ASR) models without the need for speech-text parallel data.
- ASTRA aligns speech and text representations in an unsupervised manner, enabling ASR training on monolingual speech and text data.
- The key innovation is a novel contrastive loss function that encourages the model to learn speech and text representations that are well-aligned, without relying on paired data.
Plain English Explanation
The ASTRA method tackles a common challenge in automatic speech recognition (ASR) - the need for large datasets of speech audio paired with their corresponding text transcripts. This can be a significant bottleneck for developing ASR systems, especially for low-resource languages.
ASTRA sidesteps this issue by learning to align speech and text representations in an unsupervised way, using only monolingual speech and text data. The key insight is that even without paired data, the model can learn to associate similar speech and text through a clever loss function that rewards "matching" representations.
This means ASTRA can be trained on large quantities of standalone speech audio and text, without requiring the time-consuming and expensive process of transcribing the speech. The approach is similar to other work on textless speech-to-speech, but applied to the ASR task.
The end result is an ASR model that can be trained more efficiently, without the bottleneck of needing large amounts of speech-text parallel data. This could enable more effective automated speaking assessment and improved conversational speech recognition in low-resource settings.
Technical Explanation
The core of the ASTRA approach is a contrastive loss function that aligns the speech and text representations learned by the model. Given a speech input and a set of text candidates, the loss encourages the model to assign a higher similarity score to the "correct" text representation (i.e., the one that matches the speech) compared to other, unmatched text representations.
This is implemented by passing the speech and text through separate encoder networks to obtain their respective representations. A contrastive loss is then applied that pulls the matching speech-text pair closer together in the representation space, while pushing unmatched pairs further apart.
Importantly, ASTRA does not require any parallel speech-text data. The model is trained on monolingual speech and text datasets, with the contrastive loss providing the necessary supervision signal to align the representations. This departs from traditional ASR training which relies on paired data.
The authors demonstrate the effectiveness of ASTRA on several ASR benchmarks, showing it can achieve competitive performance compared to models trained on paired data. They also show the benefits of the approach for low-resource languages, where parallel data is scarce.
Critical Analysis
The ASTRA approach is a promising step towards more efficient and flexible ASR training. By removing the need for paired speech-text data, it opens up the possibility of leveraging large quantities of unlabeled speech and text, which could be particularly valuable for low-resource languages.
However, the paper does not extensively explore the limitations of the method. For example, it's unclear how ASTRA would scale to very large vocabulary sizes or how it would perform on more challenging speech recognition tasks beyond simple benchmarks.
Additionally, the authors acknowledge that ASTRA still requires some amount of parallel data for initialization and validation, which could be a barrier in truly low-resource settings. Further research is needed to address this limitation.
Overall, ASTRA represents an interesting and important contribution to the field of speech recognition. While it has some caveats, the core idea of aligning speech and text representations in an unsupervised manner is a promising direction that could lead to more efficient and accessible ASR systems in the future.
Conclusion
The ASTRA method proposes a novel approach to training automatic speech recognition (ASR) models without the need for large datasets of paired speech audio and text transcripts. By aligning the representations of speech and text in an unsupervised manner, ASTRA can leverage monolingual speech and text data to train effective ASR models.
This has the potential to significantly improve the accessibility and affordability of ASR, especially for low-resource languages where parallel data is scarce. While the method has some limitations that require further research, the core idea of unsupervised speech-text alignment represents an important step forward in the field of speech recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ASTRA: Aligning Speech and Text Representations for Asr without Sampling
Neeraj Gaur, Rohan Agrawal, Gary Wang, Parisa Haghani, Andrew Rosenberg, Bhuvana Ramabhadran
This paper introduces ASTRA, a novel method for improving Automatic Speech Recognition (ASR) through text injection.Unlike prevailing techniques, ASTRA eliminates the need for sampling to match sequence lengths between speech and text modalities. Instead, it leverages the inherent alignments learned within CTC/RNNT models. This approach offers the following two advantages, namely, avoiding potential misalignment between speech and text features that could arise from upsampling and eliminating the need for models to accurately predict duration of sub-word tokens. This novel formulation of modality (length) matching as a weighted RNNT objective matches the performance of the state-of-the-art duration-based methods on the FLEURS benchmark, while opening up other avenues of research in speech processing.
Read more6/14/2024

0
A Single-Step Non-Autoregressive Automatic Speech Recognition Architecture with High Accuracy and Inference Speed
Ziyang Zhuang, Chenfeng Miao, Kun Zou, Ming Fang, Tao Wei, Zijian Li, Ning Cheng, Wei Hu, Shaojun Wang, Jing Xiao
Non-autoregressive (NAR) automatic speech recognition (ASR) models predict tokens independently and simultaneously, bringing high inference speed. However, there is still a gap in the accuracy of the NAR models compared to the autoregressive (AR) models. In this paper, we propose a single-step NAR ASR architecture with high accuracy and inference speed, called EffectiveASR. It uses an Index Mapping Vector (IMV) based alignment generator to generate alignments during training, and an alignment predictor to learn the alignments for inference. It can be trained end-to-end (E2E) with cross-entropy loss combined with alignment loss. The proposed EffectiveASR achieves competitive results on the AISHELL-1 and AISHELL-2 Mandarin benchmarks compared to the leading models. Specifically, it achieves character error rates (CER) of 4.26%/4.62% on the AISHELL-1 dev/test dataset, which outperforms the AR Conformer with about 30x inference speedup.
Read more8/29/2024
📊
0
An Effective Automated Speaking Assessment Approach to Mitigating Data Scarcity and Imbalanced Distribution
Tien-Hong Lo, Fu-An Chao, Tzu-I Wu, Yao-Ting Sung, Berlin Chen
Automated speaking assessment (ASA) typically involves automatic speech recognition (ASR) and hand-crafted feature extraction from the ASR transcript of a learner's speech. Recently, self-supervised learning (SSL) has shown stellar performance compared to traditional methods. However, SSL-based ASA systems are faced with at least three data-related challenges: limited annotated data, uneven distribution of learner proficiency levels and non-uniform score intervals between different CEFR proficiency levels. To address these challenges, we explore the use of two novel modeling strategies: metric-based classification and loss reweighting, leveraging distinct SSL-based embedding features. Extensive experimental results on the ICNALE benchmark dataset suggest that our approach can outperform existing strong baselines by a sizable margin, achieving a significant improvement of more than 10% in CEFR prediction accuracy.
Read more4/15/2024
🛸
0
Enabling ASR for Low-Resource Languages: A Comprehensive Dataset Creation Approach
Ara Yeroyan (Data Science Department, American University of Armenia), Nikolay Karpov (Nvidia, NeMo Conversational AI team)
In recent years, automatic speech recognition (ASR) systems have significantly improved, especially in languages with a vast amount of transcribed speech data. However, ASR systems tend to perform poorly for low-resource languages with fewer resources, such as minority and regional languages. This study introduces a novel pipeline designed to generate ASR training datasets from audiobooks, which typically feature a single transcript associated with hours-long audios. The common structure of these audiobooks poses a unique challenge due to the extensive length of audio segments, whereas optimal ASR training requires segments ranging from 4 to 15 seconds. To address this, we propose a method for effectively aligning audio with its corresponding text and segmenting it into lengths suitable for ASR training. Our approach simplifies data preparation for ASR systems in low-resource languages and demonstrates its application through a case study involving the Armenian language. Our method, which is portable to many low-resource languages, not only mitigates the issue of data scarcity but also enhances the performance of ASR models for underrepresented languages.
Read more6/4/2024