Asynchronous Distributed Reinforcement Learning for LQR Control via Zeroth-Order Block Coordinate Descent
2107.12416
0
0
🏅
Abstract
Recently introduced distributed zeroth-order optimization (ZOO) algorithms have shown their utility in distributed reinforcement learning (RL). Unfortunately, in the gradient estimation process, almost all of them require random samples with the same dimension as the global variable and/or require evaluation of the global cost function, which may induce high estimation variance for large-scale networks. In this paper, we propose a novel distributed zeroth-order algorithm by leveraging the network structure inherent in the optimization objective, which allows each agent to estimate its local gradient by local cost evaluation independently, without use of any consensus protocol. The proposed algorithm exhibits an asynchronous update scheme, and is designed for stochastic non-convex optimization with a possibly non-convex feasible domain based on the block coordinate descent method. The algorithm is later employed as a distributed model-free RL algorithm for distributed linear quadratic regulator design, where a learning graph is designed to describe the required interaction relationship among agents in distributed learning. We provide an empirical validation of the proposed algorithm to benchmark its performance on convergence rate and variance against a centralized ZOO algorithm.
Create account to get full access
Overview
- Distributed zeroth-order optimization (ZOO) algorithms have shown promise in distributed reinforcement learning (RL)
- However, existing ZOO algorithms often require random samples with the same dimension as the global variable and/or evaluation of the global cost function, leading to high estimation variance for large-scale networks
- This paper proposes a novel distributed zeroth-order algorithm that leverages the network structure to allow each agent to estimate its local gradient by local cost evaluation, without using a consensus protocol
Plain English Explanation
This paper introduces a new type of optimization algorithm called a "distributed zeroth-order" algorithm, which has applications in distributed reinforcement learning. Existing distributed ZOO algorithms often require collecting random samples that match the size of the overall system, or evaluating the overall cost function, which can be very computationally expensive for large-scale problems.
The key innovation in this paper is an algorithm that allows each agent (or "node" in the network) to independently estimate its own local gradient, based on the local cost function, without needing to coordinate with the other agents. This is accomplished by leveraging the inherent structure of the optimization problem. The algorithm also uses an "asynchronous" update scheme, meaning agents can perform computations and share information at different rates.
The authors test this new algorithm in the context of a "distributed linear quadratic regulator" problem, which is a type of model-free reinforcement learning for controlling a distributed system. They show that their algorithm can achieve good performance in terms of convergence rate and estimation variance, compared to a centralized ZOO approach.
Technical Explanation
The key technical contribution of this paper is a novel distributed zeroth-order optimization (ZOO) algorithm that addresses the limitations of prior distributed ZOO methods. Existing approaches often require random samples with the same dimension as the global variable and/or evaluation of the global cost function, which can lead to high estimation variance, especially for large-scale networks.
The proposed algorithm leverages the inherent network structure of the optimization problem to allow each agent to independently estimate its local gradient using only local cost function evaluations, without requiring any consensus protocol. This is achieved by formulating the problem using a block coordinate descent method, which divides the global optimization problem into smaller subproblems for each agent.
The algorithm also employs an asynchronous update scheme, where agents can perform computations and share information at different rates. This is designed to be suitable for stochastic non-convex optimization problems with a possibly non-convex feasible domain.
The authors demonstrate the effectiveness of their approach through experiments on a distributed linear quadratic regulator problem, a type of model-free reinforcement learning task. They show that their distributed ZOO algorithm outperforms a centralized ZOO approach in terms of convergence rate and estimation variance.
Critical Analysis
The paper presents a novel and promising approach to distributed zeroth-order optimization, which addresses some key limitations of prior work. By leveraging the inherent network structure, the proposed algorithm allows each agent to estimate its local gradient independently, without the need for costly global information or coordination.
However, the paper does not discuss the potential limitations or caveats of this approach. For example, it's unclear how well the algorithm would scale to extremely large-scale networks, or how robust it would be to noisy or unreliable local cost function evaluations. Additionally, the analysis of the convergence rate and variance could be further explored to better understand the algorithm's theoretical properties.
Furthermore, the paper focuses on a specific application (distributed linear quadratic regulator) and does not explore the broader applicability of the proposed algorithm. It would be valuable to see how it performs on a wider range of distributed optimization problems, particularly those with different types of network structures or constraints.
Overall, this paper presents an interesting and potentially impactful contribution to the field of distributed optimization and reinforcement learning. However, further research is needed to better understand the algorithm's limitations, robustness, and broader applicability.
Conclusion
This paper introduces a novel distributed zeroth-order optimization algorithm that addresses the limitations of existing approaches. By leveraging the inherent network structure, the proposed algorithm allows each agent to independently estimate its local gradient using only local cost function evaluations, without requiring global information or a consensus protocol.
The authors demonstrate the effectiveness of their algorithm through experiments on a distributed linear quadratic regulator problem, showing that it outperforms a centralized ZOO approach in terms of convergence rate and estimation variance. This work has important implications for the field of distributed reinforcement learning, as it provides a more scalable and efficient way to perform gradient-free optimization in large-scale, decentralized systems.
While further research is needed to better understand the limitations and broader applicability of the proposed algorithm, this paper represents a significant advancement in the field of distributed optimization and a valuable contribution to the ongoing efforts to develop more efficient and scalable reinforcement learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Zeroth-Order Proximal Algorithm for Consensus Optimization
Chengan Wang, Zichong Ou, Jie Lu
0
0
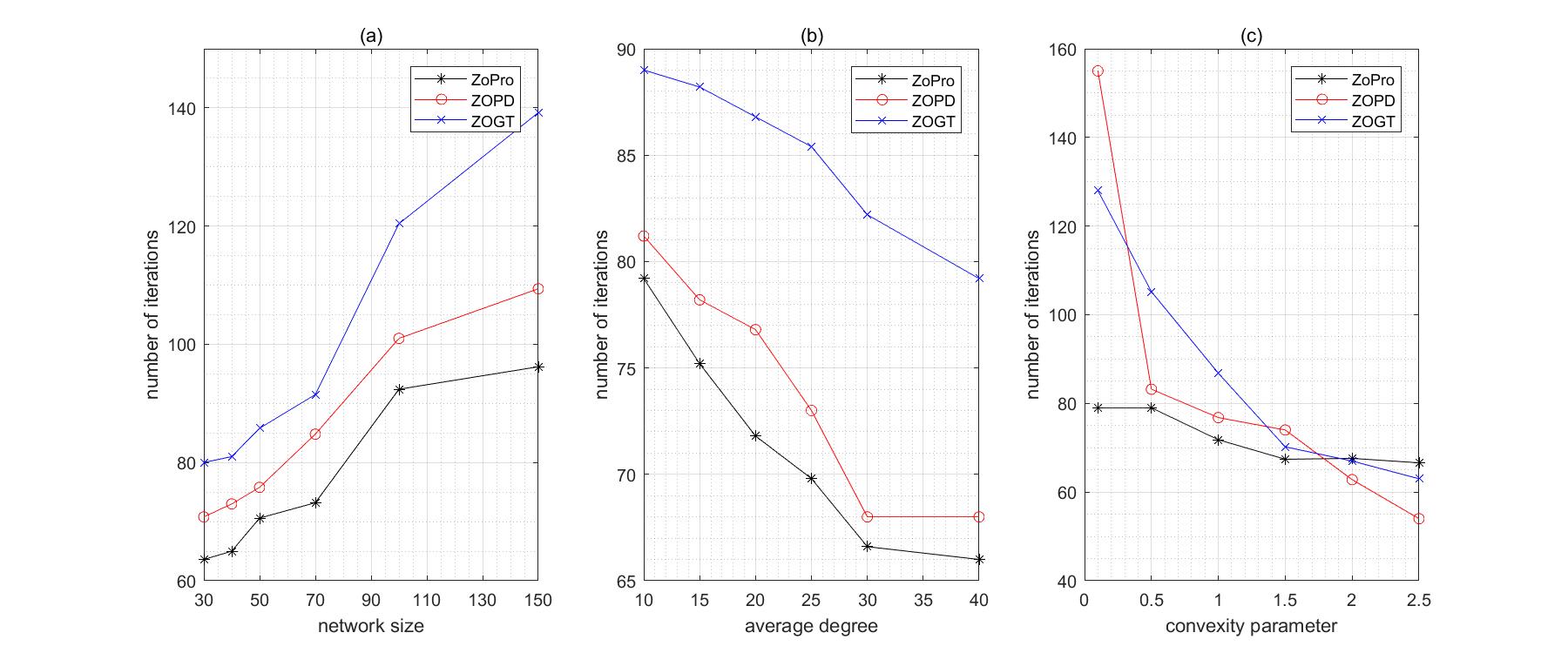
This paper considers a consensus optimization problem, where all the nodes in a network, with access to the zeroth-order information of its local objective function only, attempt to cooperatively achieve a common minimizer of the sum of their local objectives. To address this problem, we develop ZoPro, a zeroth-order proximal algorithm, which incorporates a zeroth-order oracle for approximating Hessian and gradient into a recently proposed, high-performance distributed second-order proximal algorithm. We show that the proposed ZoPro algorithm, equipped with a dynamic stepsize, converges linearly to a neighborhood of the optimum in expectation, provided that each local objective function is strongly convex and smooth. Extensive simulations demonstrate that ZoPro converges faster than several state-of-the-art distributed zeroth-order algorithms and outperforms a few distributed second-order algorithms in terms of running time for reaching given accuracy.
6/17/2024

Model-Agnostic Zeroth-Order Policy Optimization for Meta-Learning of Ergodic Linear Quadratic Regulators
Yunian Pan, Quanyan Zhu
0
0
Meta-learning has been proposed as a promising machine learning topic in recent years, with important applications to image classification, robotics, computer games, and control systems. In this paper, we study the problem of using meta-learning to deal with uncertainty and heterogeneity in ergodic linear quadratic regulators. We integrate the zeroth-order optimization technique with a typical meta-learning method, proposing an algorithm that omits the estimation of policy Hessian, which applies to tasks of learning a set of heterogeneous but similar linear dynamic systems. The induced meta-objective function inherits important properties of the original cost function when the set of linear dynamic systems are meta-learnable, allowing the algorithm to optimize over a learnable landscape without projection onto the feasible set. We provide a convergence result for the exact gradient descent process by analyzing the boundedness and smoothness of the gradient for the meta-objective, which justify the proposed algorithm with gradient estimation error being small. We also provide a numerical example to corroborate this perspective.
5/28/2024

Continuous Control Reinforcement Learning: Distributed Distributional DrQ Algorithms
Zehao Zhou
0
0
Distributed Distributional DrQ is a model-free and off-policy RL algorithm for continuous control tasks based on the state and observation of the agent, which is an actor-critic method with the data-augmentation and the distributional perspective of critic value function. Aim to learn to control the agent and master some tasks in a high-dimensional continuous space. DrQ-v2 uses DDPG as the backbone and achieves out-performance in various continuous control tasks. Here Distributed Distributional DrQ uses Distributed Distributional DDPG as the backbone, and this modification aims to achieve better performance in some hard continuous control tasks through the better expression ability of distributional value function and distributed actor policies.
4/17/2024

Federated reinforcement learning for robot motion planning with zero-shot generalization
Zhenyuan Yuan, Siyuan Xu, Minghui Zhu
0
0
This paper considers the problem of learning a control policy for robot motion planning with zero-shot generalization, i.e., no data collection and policy adaptation is needed when the learned policy is deployed in new environments. We develop a federated reinforcement learning framework that enables collaborative learning of multiple learners and a central server, i.e., the Cloud, without sharing their raw data. In each iteration, each learner uploads its local control policy and the corresponding estimated normalized arrival time to the Cloud, which then computes the global optimum among the learners and broadcasts the optimal policy to the learners. Each learner then selects between its local control policy and that from the Cloud for next iteration. The proposed framework leverages on the derived zero-shot generalization guarantees on arrival time and safety. Theoretical guarantees on almost-sure convergence, almost consensus, Pareto improvement and optimality gap are also provided. Monte Carlo simulation is conducted to evaluate the proposed framework.
4/9/2024